



We put out our first blog on the introducing the Arize database – adb – in the beginning of July; this blog dives deeper into the realtime ingestion support of adb.
AI data use-cases require an interface that supports both large files (like custom datasets) and real-time events from traces. The Arize AX platform was designed to handle both of these use-cases in a consistent fashion, and at the extremes of scale.
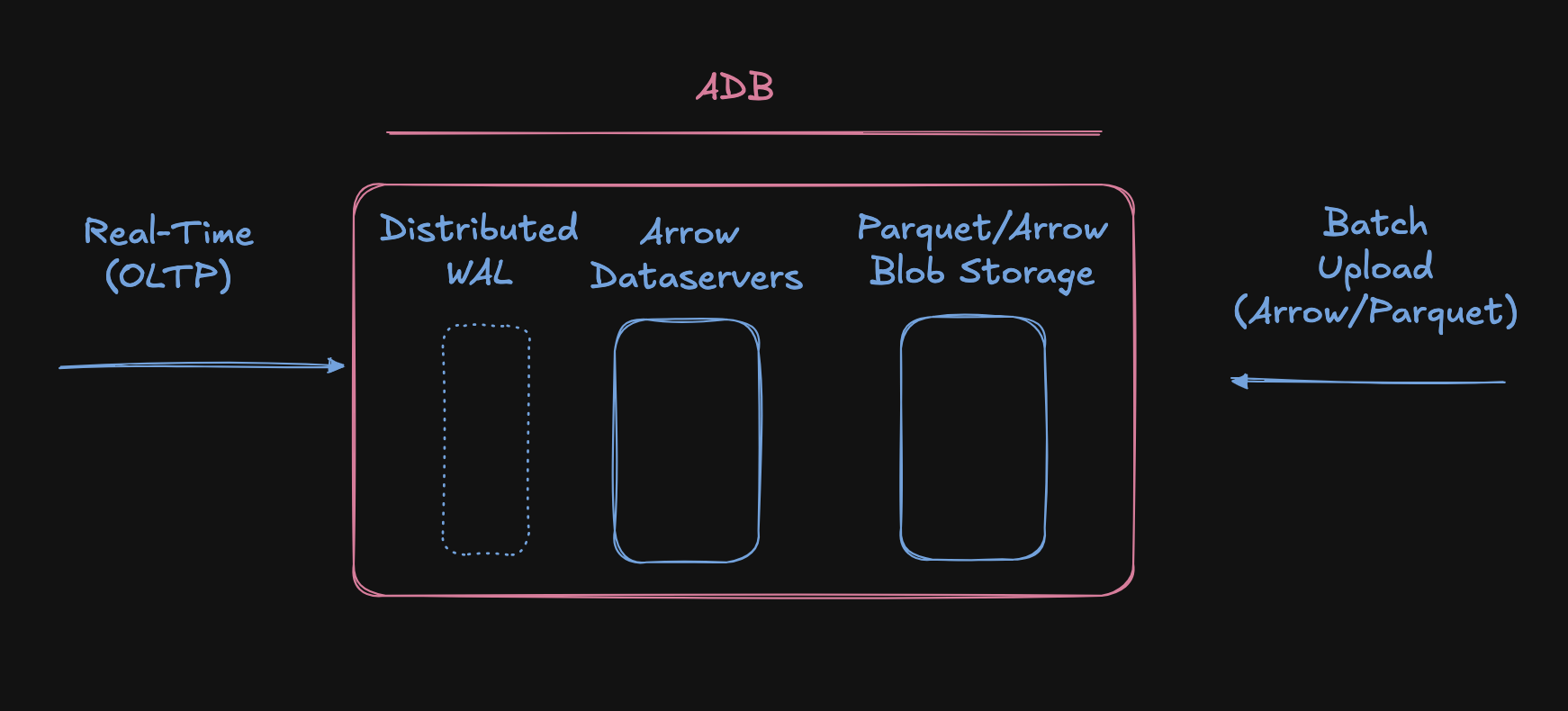
In this post, we take a deeper dive into the unique features of adb’s data-storage and realtime ingestion path (the batch upload will be covered in a different blog).
Before we jump into the details, let’s recap the motivations we experienced while building Arize AX:
- Arize has individual integrations that produce many terabytes per day across billions of spans. This means adb needs to be elastically and efficiently scalable.
- Users expect ownership of their data. This extends past owning the infrastructure and requires that users have access to their data directly, in a standard format, via whatever data-warehouse they prefer.
- Interactive feedback is critical for iteration, and building a language application is an iterative process. This means it needs to be able to ingest streams of data in real-time, and expose it for query or update in under a second.
Though there are no silver-bullets when it comes to achieving performance, elasticity, and reliability, adb’s clear separation of compute from data storage combined with the choice to leverage the best of both Apache Parquet and Arrow put our goals within reach.
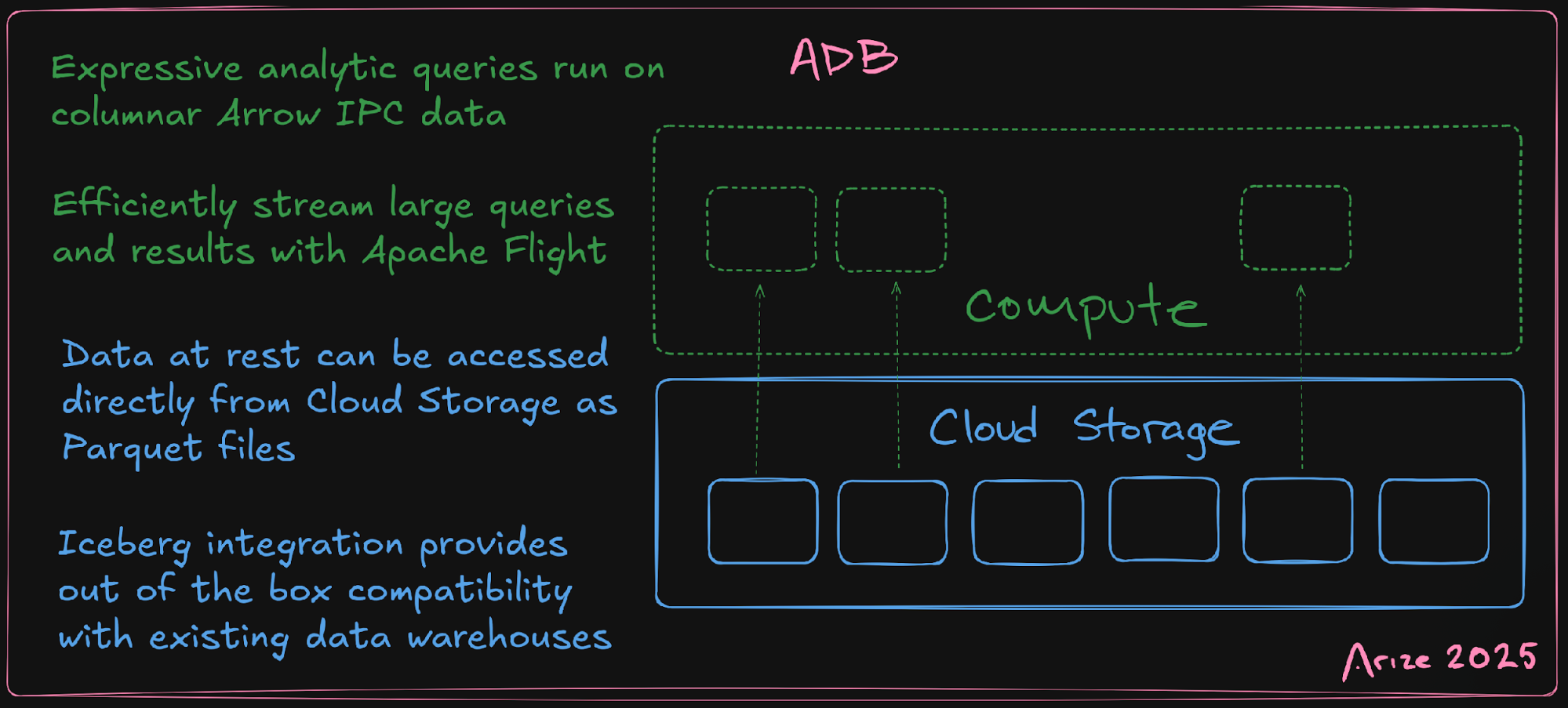
Now somewhat common, the choice to separate storage and compute provides a ton of advantages when building a resilient and durable system without sacrificing operational efficiency. Keeping the data outside of the system allows us to make operational choices as if the system were stateless. Should the system need to be moved due to infrastructure failure, operator choice, etc. then all that is needed is to scale up compute in the destination — most importantly, the stable location of the data does not change and nothing needs to be copied or moved. In addition to these operational benefits, the separation allows us to scale our capacity independently along the dimensions of compute and storage. This means we can elastically add resources to meet the fluctuating demand of queries and UI ingestion, and store far more data than we will ever query at any point in time — only paying the corresponding compute cost when (and if) that data is accessed.
From top to bottom, adb is designed to not only take advantage of the strengths of external BLOB storage, but also to seamlessly hide the higher IO-cost of network storage. Through a combination of pre-fetching and caching, the query layer is able to maintain a low access-rate to the objects in Cloud Storage. Reasons like this made us confident that we needed to design our IO patterns to optimize for external storage, instead of revisiting it as an extension or plugin. The separation of storage and compute in adb goes beyond operational convenience and abstractions in code. adb utilizes two different file formats, (the cousins of columnar data) Parquet and ArrowIPC, for data-at-rest and data-in-flight respectively.
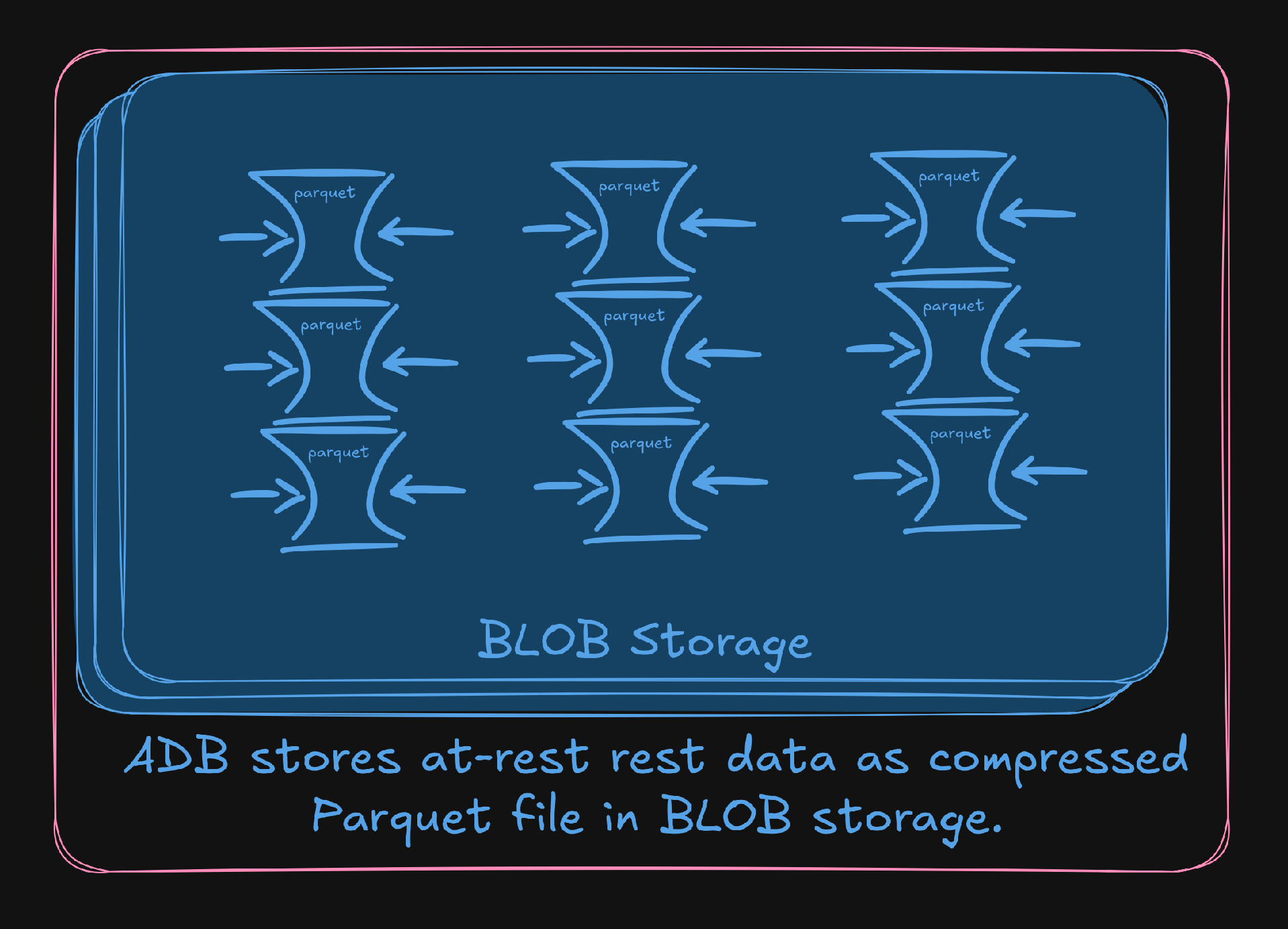
Both formats are maintained by the Apache Software Foundation (in some languages as a single code-base). Though similar, each has its own distinct advantages and use case. Parquet’s internal column-compression makes it extremely efficient for long-term storage, and its near ubiquitous compatibility with big-data warehouses lay clear the path for DataFabric (an Arize AX feature we will expand on in a future post).
While it’s possible to run queries on data stored in Parquet format, we can definitely do better. That’s where the Arrow IPC (Inter-Process Communication) format comes in. Like Parquet, Arrow is a columnar format, but unlike Parquet, Arrow formatted column-data is not compressed (and so does not need to be decompressed on read). Better yet, a column of Arrow format data has the same representation on disk and in memory, meaning it can be accessed/stored without deserialization/serialization costs. This alone makes Arrow an attractive storage-format, but it’s called Arrow IPC for a reason — Flight. Flight is built on gRPC(HTTP/2), so out of the box it has clearly defined types and wide language support. Flight implementations provide a concrete definition of the abstract specification in terms of gRPC streams. Because of the structure of Arrow data in memory, Fight implementations can often be copy-free in addition to serialization-free, resulting in memory-efficient and fast clients.
Arrow and Flight are fantastic building blocks, but adb is a streaming analytic database, and it was left to us to “draw the rest of the owl.”
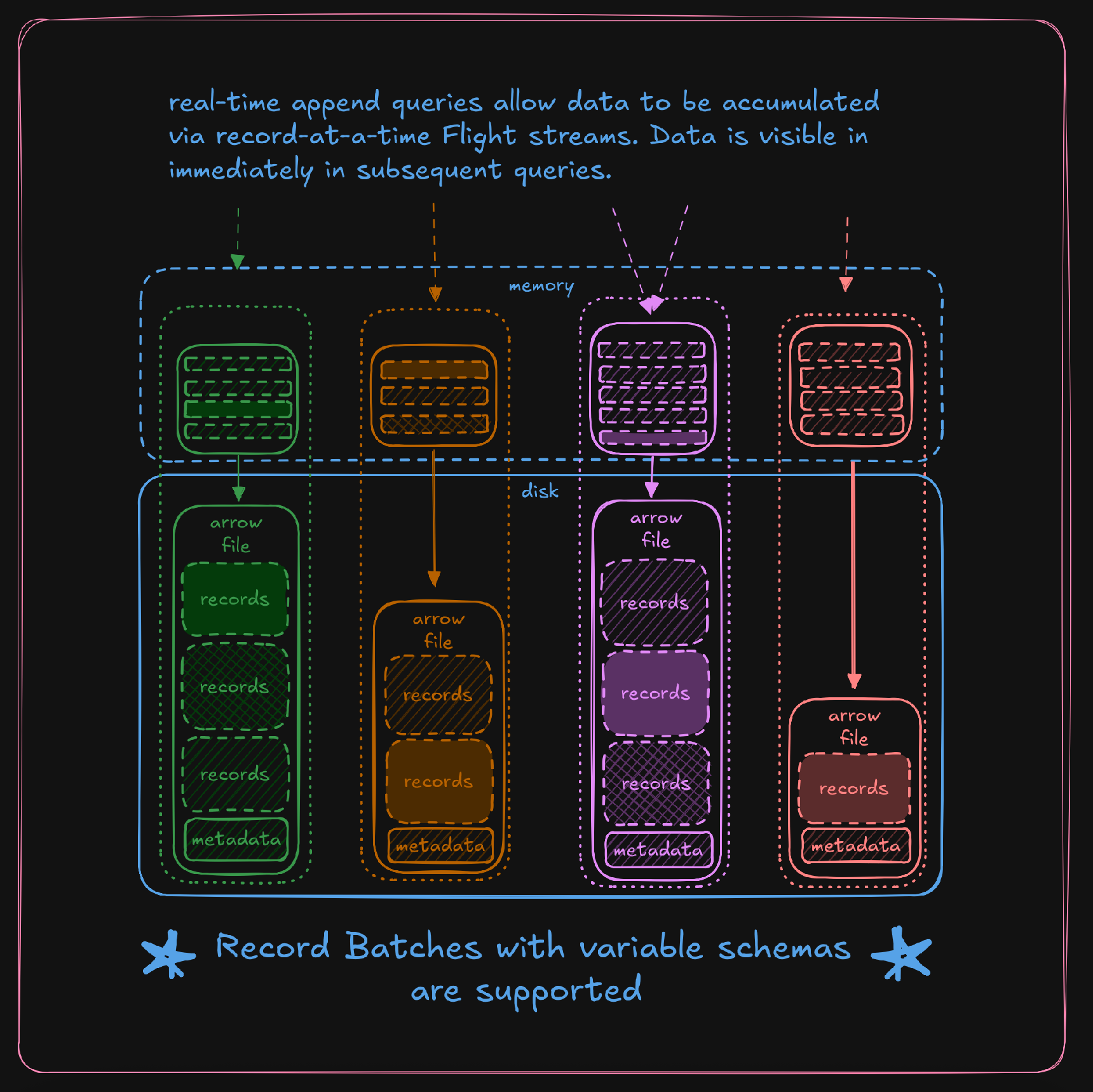
The figure above depicts the simplified internals of an adb query-broker. Streams of individual records accumulate in memory, periodically flushing to local disk (later synchronized to BLOB storage). From the moment a record arrives in memory it is included in the results of any query the broker processes. Because we set out to build adb after years of operating OLAPs specifically for Arize AX, we knew from experience that real-time streams were a must-have, and that knowing a stream’s schema in advance is the exception, not the rule. Arize adb provides this flexibility without breaking backwards compatibility with Flight or ArrowIPC (which are by definition a sequence of record-blocks with the same schema). The challenges we encountered required us to rewrite some of the low level arrow primitives, allowing for dynamic schemas in flight but then enabling us to persist final arrow-compatible files. This strategy achieves our goal of sub-second data availability, but in order to uphold our effectively-once delivery guarantees we need one more thing.
Because memory is not durable, inbound messages are not acknowledged to the client until they are synchronized to disk. Any failure or error during the stream’s lifetime requires that the client restart the stream from the last committed record. This gets us at-least-once delivery guarantees, but with retries come duplicates.
To address the issue of duplicate data, each stream has an optional client-settable identifier. On stream retries, the identifier from the previous attempt is re-used, allowing adb to deduplicate events based on their sequence number within the stream. This now satisfies our requirement for strong delivery guarantees in adb and leaves us in a good position as application developers in AX to integrate our OpenTelemetry network-edge through a distributed write-ahead-log.
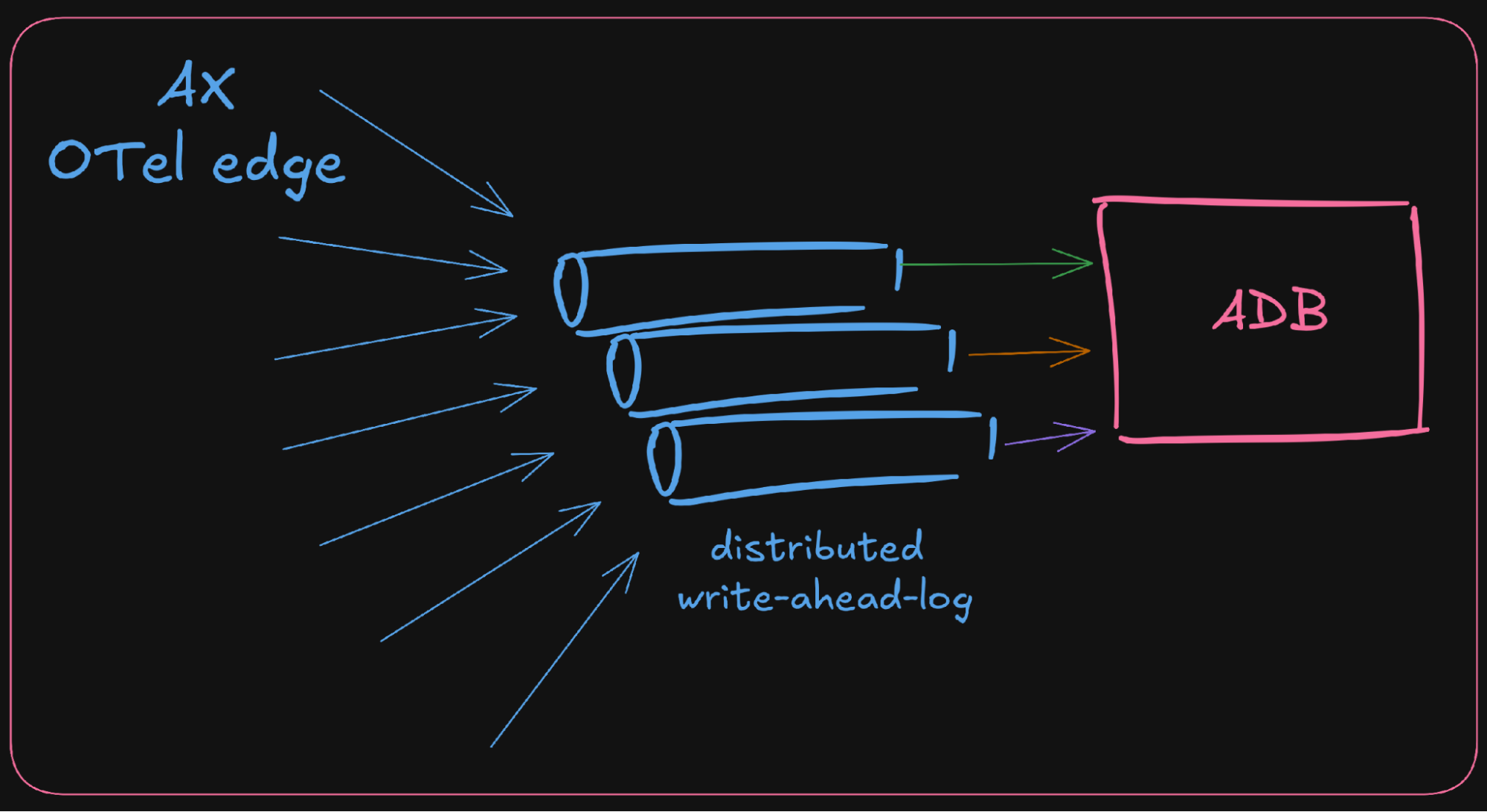
The WAL provides a first-line of data persistence, sitting behind our stateless network-edge. In this context we are adb clients, creating and maintaining append streams and the WAL allows us to uphold the client-side retry requirements in adb’s effectively-once protocol.
We didn’t build adb because we wanted to, or because we thought we could improve on existing, well-packaged, battle-tested solutions. We built adb because we needed a specific combination of features that no off-the-shelf option provided. The end result not only achieves our functional goals within Arize but, we believe, also represents a result worth sharing in and of itself.
What’s Next
This covered the real-time ingestion path. For the full picture, read our introduction to adb to see how the batch upload, compaction, and cache management work together. Or skip straight to the benchmarks to see how adb performs on dataset uploads, real-time ingest latency, and full-text search.