



In our last post on Prompt Learning (our prompt optimization feature), we optimized Cline, a powerful coding agent, through its system prompt.
This time, we used it on one that more of you are probably familiar with – Claude Code – and saw some awesome results.
Claude Code is considered one of the best coding agents in the world. It employs Claude Sonnet 4-5, which is also considered to be a state-of-the-art coding model. You can see that it dominates the leaderboards for SWE bench (a popular benchmark used to evaluate code generation).
As a developer looking to bring the best out of these coding agents, one workflow available to you is editing Claude Code’s system prompt. If you use the CLI, this workflow is accessed through the --append-system-prompt tag in the Claude Code CLI.

You can also specify custom rules through a CLAUDE.md file. Claude’s best practices guide for Claude Code states the following:
"
CLAUDE.md is a special file that Claude automatically pulls into context when starting a conversation. This makes it an ideal place for documenting:
Common bash commands
Core files and utility functions
Code style guidelines
Testing instructions
Repository etiquette (e.g., branch naming, merge vs. rebase, etc.)
Developer environment setup (e.g., pyenv use, which compilers work)
Any unexpected behaviors or warnings particular to the project
Other information you want Claude to remember
"
This lets you add custom instructions to your Claude Code calls, giving you a lot of power and say in the code Claude Code generates.
In this blog post, we’ll show you how we used Prompt Learning to generate an optimal set of custom instructions that improved Claude Code’s results on SWE Bench. We show you how we improved Claude Code – without changing tools, architecture, fine-tuning LLMs, or any changes you could make other than adding optimal instructions to the system prompt.
Quick Prompt Learning Overview
Prompt Learning is a prompt optimization approach, inspired by reinforcement learning. It looks to optimize an agent through its prompt, based on how the agent performs over a dataset of queries.

Both reinforcement learning and Prompt Learning employ a feedback loop based on output generation and evaluation of that output, but instead of model weights, Prompt Learning focuses on updating system prompts for agents.
Instead of PPO, Q learning, gradient descent, or some adjacent weight update algorithm, Prompt Learning uses meta-prompting to make prompt improvements. Meta-prompting is the simple task of asking an LLM to optimize your prompt, with respect to some data on how that prompt performs.
What makes Prompt Learning really special is using LLM evals, instead of just scalar rewards, as feedback into the meta prompt. For every rollout (agent generates output), we ask an LLM to tell us WHY the output was correct/incorrect, and WHERE improvements could be made. This allows the meta-prompt LLM to make informed and guided decisions on how to optimize the agent’s system prompt.
See this blog for a more detailed description of Prompt Learning. We go in depth into LLM Evals and meta-prompting.
About SWE Bench Lite (our chosen benchmark)
For reference, see the SWE bench paper and the SWE Bench leaderboard.
SWE Bench Lite is a popular benchmark used to evaluate coding models/agents. It consists of 300 Github issues from a set of popular open source Python repositories (like Django, matplotlib, etc.) It tests whether coding models/agents can solve those Github issues.
We used data from SWE Bench Lite to train the optimizer and evaluate Claude Code at each iteration of optimization.
Prompt Learning on Claude Code
Here’s precisely how we applied Prompt Learning to optimize Claude Code.
Step 1: Train/Test Split
First, we separate SWE Bench Lite into training and test sets.
We will use about half of SWE Bench Lite to train the optimizer (and generate new prompts), and the other half to test out whether our prompt optimizations lead to better solutions.
Important: For Claude Code, we used two different train/test splits.
1. Split by Repo
We selected all SWE Bench Lite Github issues from six Python repositories for training, and all issues from the other six Python repositories to be for testing. This split helps us see if we can improve the general coding ability of Claude Code. We split by repository to avoid overfitting -> any rules hyperspecific to the six training repositories for training should not help Claude Code generate better code for any of the six test repositories.
Train Repos:
'django/django',
'pytest-dev/pytest',
'sphinx-doc/sphinx',
'astropy/astropy',
'psf/requests',
'pylint-dev/pylint'
Test Repos:
'sympy/sympy',
'matplotlib/matplotlib',
'scikit-learn/scikit-learn',
'pydata/xarray',
'mwaskom/seaborn',
'pallets/flask'
2. Split within Repo
For this split, we selected all 114 Django issues from SWE Bench Lite and divided them into train and test sets based on timestamp. The motivation is simple: if you’re a developer working on the same codebase every day, you want Claude Code to get better at your repository. By training the system prompt on past issues and their correct solutions, you give Claude Code context about how this codebase typically evolves – its patterns, conventions, and common pitfalls – so it can generate stronger patches for future issues in the same repo.
Keep In Mind
Both splits test different things. Split 1 tests whether we can improve Claude Code’s general ability to code, by splitting train/test based on Python repository. Split 2 tests a more practical developer workflow – whether you can localize your Claude Code calls to your repository, and train it to be better at solving issues in your codebase based on previous issues from that same codebase.
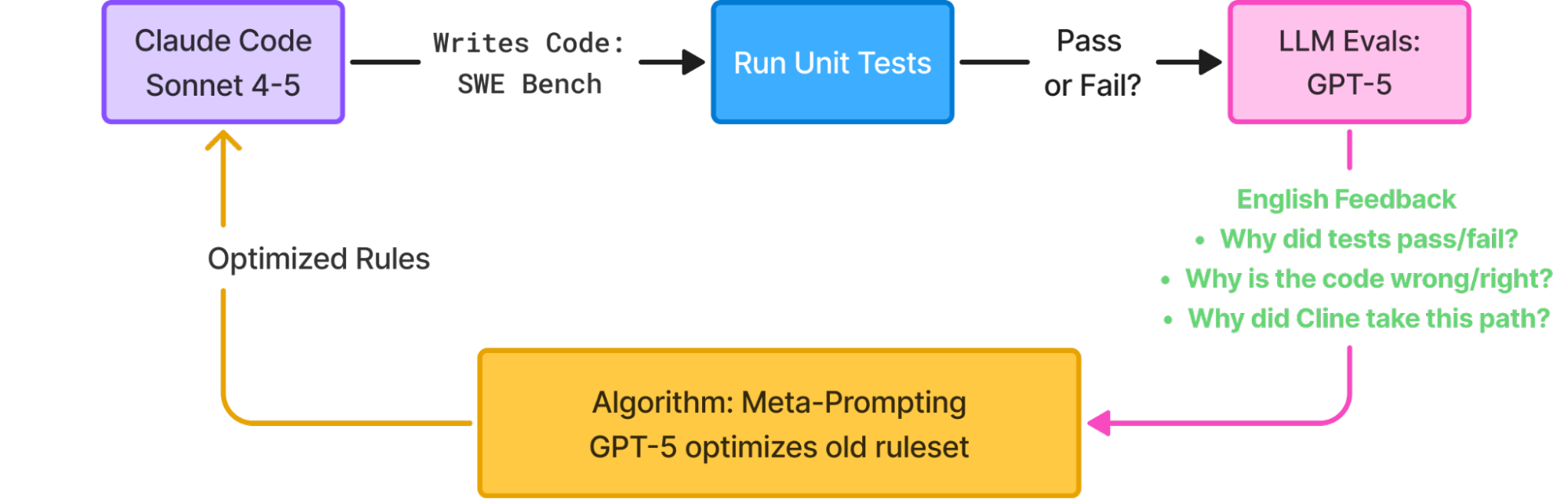
Step 2: Run Claude Code on Training Set
Second, we run Claude Code on the training examples, generating solution patches for each Github issue in our SWE Bench training set. These patches are formed by running Claude Code on the repository, with the issue body as its prompt, and running git diff to extract all changes made to the repo.
We used Phoenix experiments to easily run Claude Code on a dataset, and set up evaluations (step 4).
Step 3: Run Unit Tests
For every solution patch Claude Code generates, we run the unit tests provided by SWE Bench to determine whether Claude Code’s solution passes or fails. From this we generate our score -> 1 for pass, 0 for fail.
Step 4: Generate LLM Feedback
In order to boost optimization, we generate LLM feedback, by asking an LLM to evaluate Claude Code’s solution.
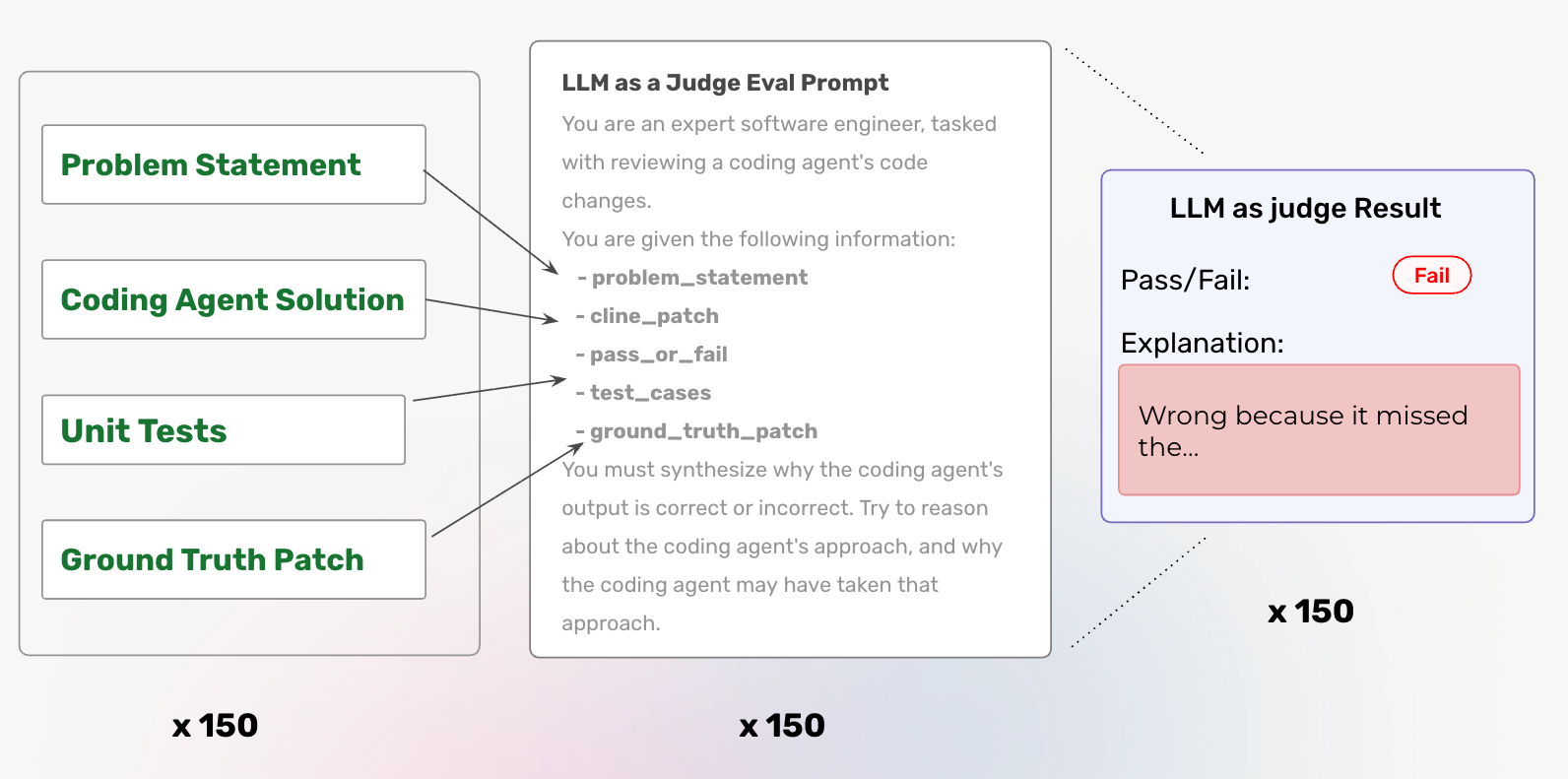
For reference, here is the full evaluator prompt.
This step gives us richer feedback for optimization. It helps guide the next stage, meta prompting, to generating better prompts. Instead of just telling our meta prompt that 6 tests passed, and 4 tests failed, we generate stronger feedback, answering questions like:
- Was the solution right/wrong at a conceptual level?
- Why did those tests pass/fail? Was it because of specific nuances, or the overall solution being right/wrong?
- Why did Claude Code take this approach, instead of the right one? (if Claude Code was wrong)
Step 5: Optimize System Prompt with Meta Prompting
With our training data fully built, we can now feed this to our meta prompt, asking it to generate an optimized prompt.
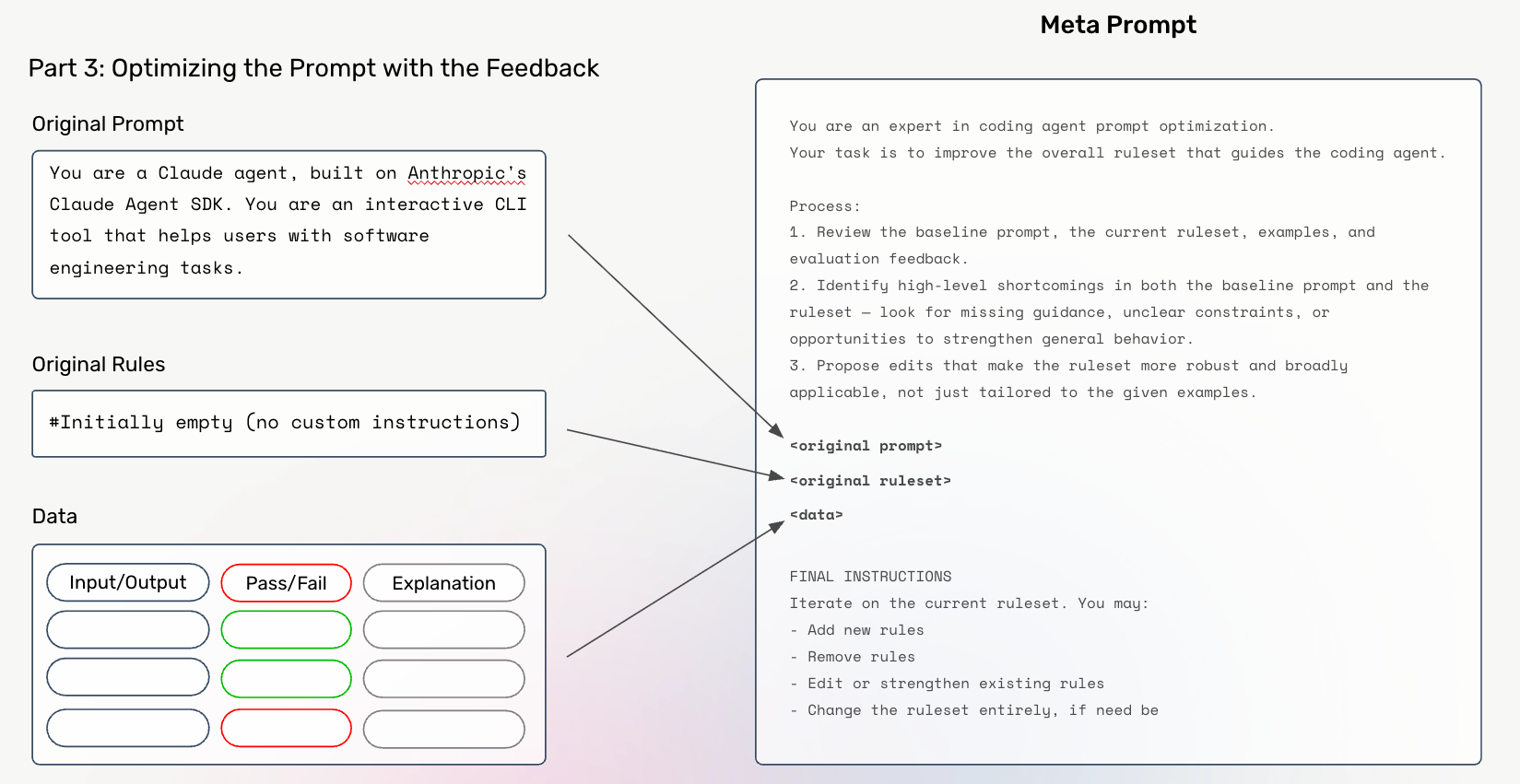
The term “rules” here refers to anything you supply through CLAUDE.md, or --append-system-prompt.
Step 6: Run Claude Code on Test Set, With New Rules
The final step of the loop is to test Claude Code on our test data, using the optimized rules we built after the meta prompting stage. This will tell us if Claude Code has improved, and how much.
Step 7: Repeat
We repeat this loop until we plateau or hit a maximum on SWE Bench accuracy, or until a certain threshold for API costs is reached.
Results
Here are our results for both train/test splits. If you missed the important distinction between the by-repo and within-repo splits, please refer back to that above.
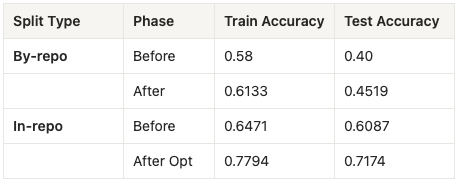
By-Repo
We were able to boost Claude Code’s test accuracy by 5.19%. By-repo split indicates that we were able to improve Claude Code’s general codegen abilities, as the test set contains issues from repositories that don’t exist in the training set.
In-Repo
We saw an even bigger improvement for our in-repo test: +10.87%. This is expected, as we were training and testing Claude Code using issues from the same Python repo.
You may look at this result and attribute it to overfitting. However, the goal of this task was to train Claude Code’s prompt to the same repo as testing. As stated earlier, this mimics a developer’s workflow. In this case “overfitting” to a specific repository is actually the goal – it allows you to tailor the code Claude Code generates to the specific codebases you work on!
Final Takeaways
Prompt optimization meaningfully improves even top-tier coding agents. Claude Code already uses one of the strongest coding models available (Claude Sonnet 4.5), yet optimizing only its system prompt yielded 5%+ gains in general coding performance and even larger gains when specialized to a single repository.
Repository-specific optimization is a practical superpower. If you work on the same codebase(s) every day, Prompt Learning can train Claude Code to internalize that repo’s patterns, norms, quirks, and conventions, for something that looks like +11% better code! What looks like “overfitting” from a benchmarking perspective becomes an advantage in real-world workflows.
You don’t need to modify models, tooling, or architecture to get better performance. All improvements came purely from refining the instructions given to Claude Code—no fine-tuning, no retraining, no custom infrastructure. Just better prompts driven by real performance data.
LLM Evals provide richer learning signals than scalar rewards. By explaining why a patch worked or failed, LLM feedback allows the meta-optimizer to target the actual failure modes (misunderstood APIs, missing edge cases, incorrect assumptions about repository structure), instead of blindly exploring prompt variations.
Meta-prompting scales to any agent that exposes a system prompt. Claude Code, Cline, custom coding agents, RAG assistants, or internal developer tools—anything with an editable prompt can be optimized using this exact loop.
Helpful Links
Relevant resources:
- Prompt Learning SDK
- Prompt Learning on Claude Code (code)
- Prompt Learning (blog post)
- Optimizing Cline Rules (blog post)