
Co-Authored by Yesmine Rouis, Data Scientist, TheFork & Natalia Skaczkowska-Drabczyk, AI Solutions Engineer.
TheFork is one of Europe’s leading restaurant discovery and booking platforms, connecting millions of diners with tens of thousands of restaurants across major cities. The company’s marketplace spans everything from neighborhood bistros to destination dining, with real-time availability, offers, and a seamless reservation flow.
How TheFork Uses AI
AI is woven into customer journeys at TheFork. Generative AI use cases include review understanding and summarization, entity extraction from restaurant content, content moderation and clustering, and internal developer assistance for faster iteration.
The team’s flagship AI initiatives, which are being rolled out selectively across TheFork’s markets, are:
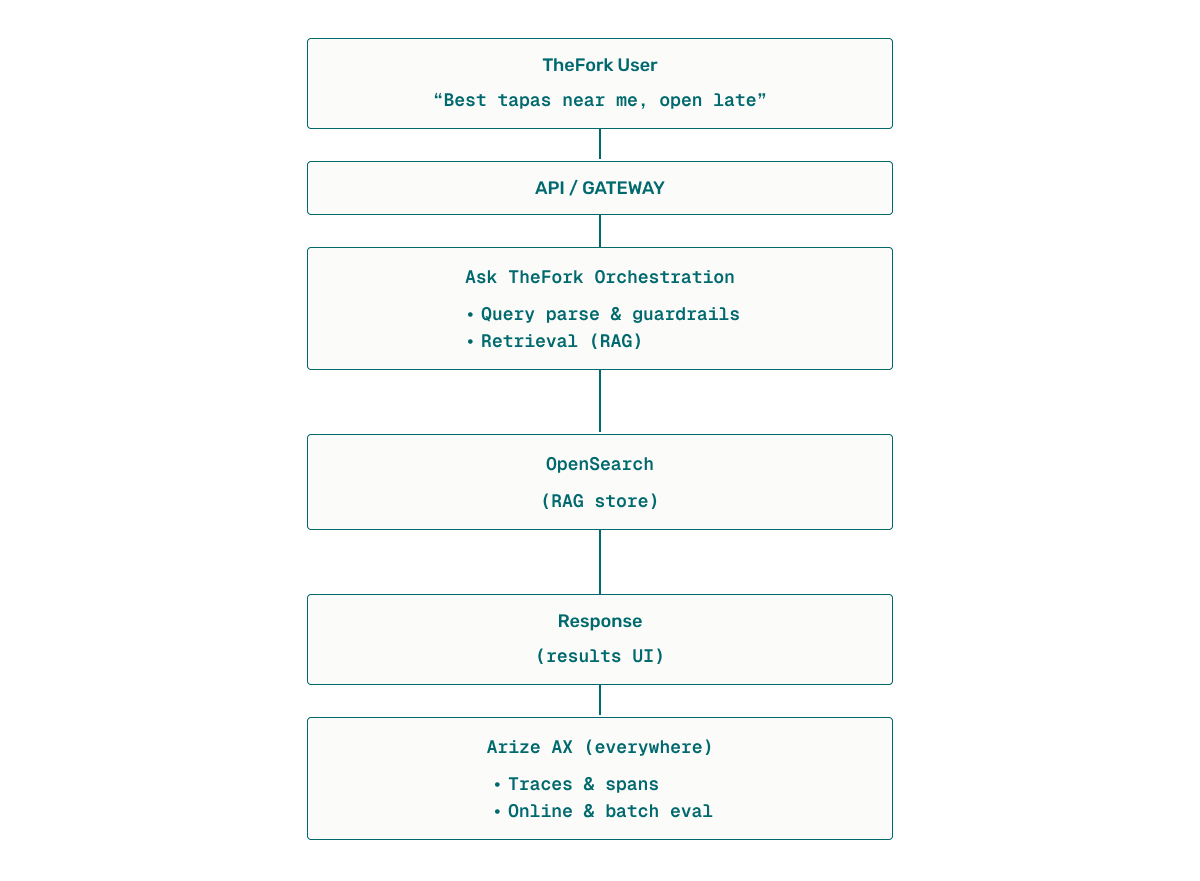
- Ask TheFork. A retrieval and semantic-search experience (not a chatbot) that interprets diner intent—e.g., “best tapas near me, open late”—then retrieves and composes highly relevant results.
- AI For Service Applications: a third-party integrated chatbot that responds to users queries and helps the customer care team in their daily operations. TheFork ingests batches of conversations into Arize AX and then runs LLM-as a-judge evals and leverages alerts to monitor the chatbot performance.
The Challenge
With millions of diners searching across tens of thousands of restaurants, even small gains in retrieval quality or latency can translate into more seated guests and fewer empty tables — advancing TheFork’s mission to connect people with great dining experiences while helping restaurants grow.
Shipping LLM-powered features to production introduces three requirements:
- Tight feedback loops for prompt, retrieval, and guardrail quality
- Production-grade observability across traces, latency, cost, and drift
- Flexible evals that run continuously (online) and in batch, targeting the spans that actually matter
“Arize AX on AWS gives us prompt‑level tracing, automated evaluations, and drift alerts, so we catch regressions early and meet strict SLOs at scale.” — Luca Temperini, CTO, TheFork
TheFork’s AI Architecture at a Glance
AWS underpins hosting and data services; TheFork uses Amazon SageMaker for model endpoints and OpenSearch for vector retrieval at marketplace scale. Orchestration (e.g., LangGraph) manages multi-step flows. Arize AX is layered across this stack to capture traces/spans, run online and batch evals, monitor latency and cost, and enable observability when changes roll out.
To keep teams aligned as systems evolve, TheFork invests in automated architecture documentation and board-level governance. That cultural emphasis — document, measure, and review — pairs naturally with Arize’s trace-everything approach and makes it easier to justify changes with evidence (latency distributions, cost tables, eval scores) instead of anecdotes.
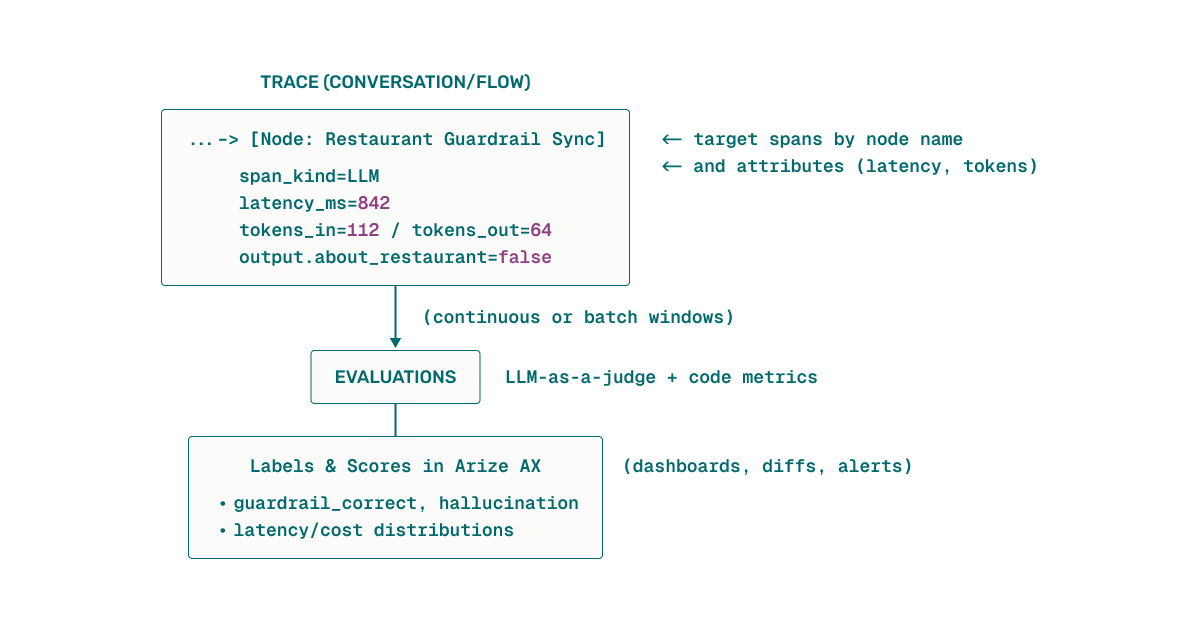
Arize AX in Practice: Online Evals That Target the Right Spans
TheFork configures attribute-driven online evals that zero in on the highest-leverage parts of the flow. Engineers filter spans by kind (LLM), node name (i.e. guardrails), latency thresholds, token counts, or error flags — then continuously score those spans with a blend of LLM-as-a-Judge prompts and code-based checks. They run the same evals on historical windows to compare versions and catch regressions, using diff views and dashboards for shared visibility. At marketplace scale, the team also samples spans that cross latency or guardrail thresholds, scoring the highest-leverage slices instead of every call — focusing effort where it moves the needle most. Because providers and models are configured by TheFork, evals and prompt playgrounds run under the team’s governance.
“It is crucial to use Arize AX to monitor the behavior of LLM models, as they can suffer from hallucinations and non-deterministic outputs, particularly when powering real-time features exposed directly to our users.”
— Yesmine Rouis, Data Scientist, TheFork
Results
Since implementing Arize AX, TheFork is seeing tangible benefits and ROI:
- Latency win: duplicate embeddings eliminated. Arize AX tracing surfaced duplicated LLM calls to generate embeddings on a critical path. Removing the duplication cut wasted work and delivered a material reduction in p95 for that flow.
- Fewer missing evals & faster iteration. Moving to hourly data uploads plus targeted backfills reduced gaps while enabling quicker read-outs of guardrail correctness and retrieval quality.
- Sharper, shared visibility. Product and engineering teams now align on color-coded eval labels, cost tables, and latency distributions, with the ability to diff experiments before shipping.
- Cost governance that scales. Normalizing provider/model metadata unlocks cost tables and a “cost per 1K queries” KPI, so teams can ship quality improvements without unexpected spend.
“Arize helped us turn tracing into tangible wins: lower latency, clearer cost signals, and faster iteration.”
— Yann Jouanin, Director of Engineering Strategy & Transformation, TheFork
TheFork engineering team is also implementing richer session and multi-span evaluations, deeper cost visibility tied to model/provider metadata, and closer links between technical signals (retrieval, prompts) and business KPIs and other new capabilities across the stack as priorities and timelines evolve.