



Co-Authored by Jim Bennett, Principal Developer Experience Engineer & Laurie Voss, Head of Developer Relations.
Enterprise software is on the verge of its first compounding data loop, the same kind of self-reinforcing mechanism that built the most valuable consumer businesses of the last twenty years. The unit of capture is the decision trace: a structured record of how an agent and a human together resolved a decision. As traces accumulate into a context graph, an organization gains a queryable record of how it actually thinks.
This article walks through why this loop never existed in the enterprise before, what three recent shifts make it possible now, how a single decision trace works as the atomic unit of capture, why the loop compounds as traces accumulate, where the rest of the industry is converging on the same idea, and the consequential choice every enterprise will face between proprietary platforms and open, portable decision history.
Enterprise reasoning has never been observable before now
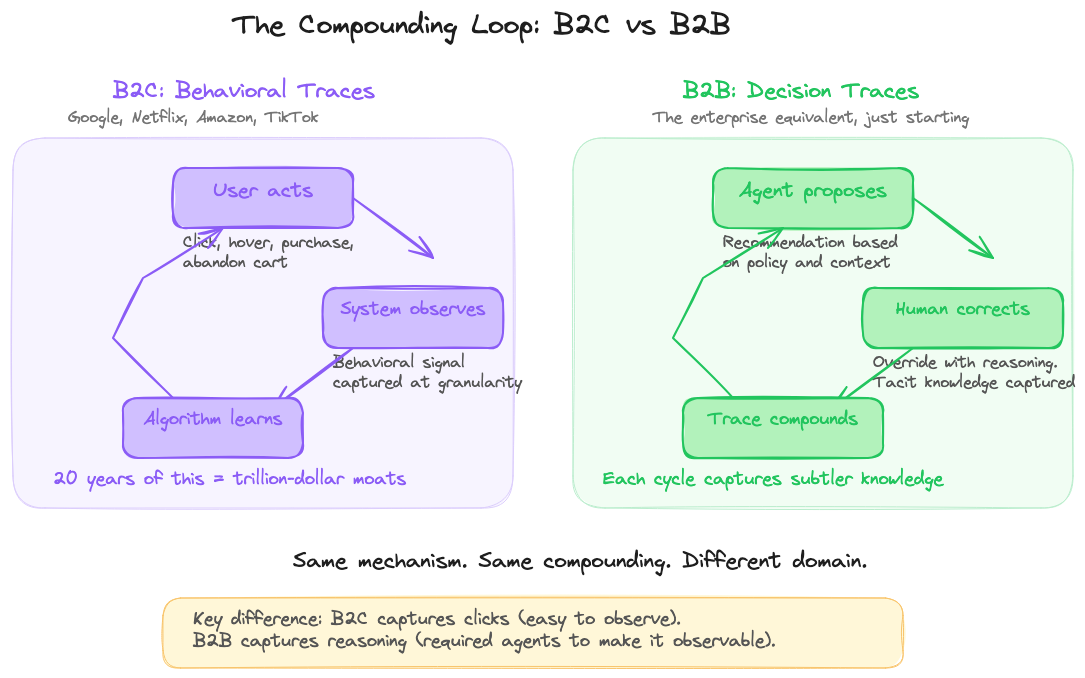
Google, Netflix, Amazon, and TikTok built trillion-dollar businesses on a single mechanism: capture behavior with extraordinary granularity, feed it into systems that learn, improve, and capture again.
Every click, every hover, every abandoned cart became a structured signal that made the next recommendation better. Over twenty years, that loop compounded into the most valuable data assets ever created.
Enterprise software has never had an equivalent.
Not because enterprise decisions are less frequent. A mid-size company makes thousands of decisions a day: approvals, escalations, exceptions, overrides, pricing calls, and vendor selections. The volume is there. What was never there was a way to observe them.
Enterprise decisions are not clicks. They are multiplayer negotiations across sales, finance, legal, and operations. They happen partly in a meeting, partly in someone’s head, partly in a Slack or Teams thread. The reasoning was never treated as data. It was treated as process exhaust: ephemeral, disposable, gone the moment the decision was made.
Systems of record capture outcomes, not the reasoning that produced them
Every enterprise system records outcomes. The CRM has the final deal price. The ticketing system has the resolution. These are systems of record, and they are good at storing the current state of things.
What they do not store is how that state came to be.
A discount field shows 15%. It does not show that the VP made an exception based on a similar deal last quarter, or that the standard policy was overridden because the customer threatened to churn. A support ticket says “escalated to Tier 3.” It does not say the support lead cross-referenced three systems and made a judgment call based on twelve years of experience.
That reasoning lives in people’s heads: exception logic, precedent from past decisions, cross-system synthesis, and approval chains that happen outside any system of record. When experienced employees leave, the knowledge leaves with them.
Now agents are entering the decision path. They can read data, apply policy, and take action. But they hit a wall: they have rules but no precedent. Policy but no judgment. What if there were a way to capture that reasoning and make it available to every agent and every employee?
Three shifts now make a graph of organizational reasoning possible
A context graph is a living, queryable record of how an organization actually makes decisions. Not the outcomes recorded in systems of record, but the reasoning behind them. It is built from decision traces, and its structure is not predefined. It emerges from the trajectories of actual work.
Three shifts have made context graphs possible.
Enterprise work moved to instrumentable surfaces. Distributed, async work means decisions now leave digital trails: comment threads, approval flows, and call recordings. The raw material exists. It just was never structured or connected.
LLMs made unstructured data computable. Transcripts, chat logs, and email threads were always searchable, but never learnable. LLMs can now extract structured decision artifacts from them and link them to outcomes.
Agents created decision checkpoints. This is the shift that matters most. When an agent proposes an action and a human approves, modifies, or overrides it, the agent’s proposal is a structured prior. The human’s response is a judgment signal. That interaction is a decision trace, and the capture is implicit. You do not ask humans to document their reasoning (they will not). Agents create natural checkpoints where tacit knowledge is forced to become explicit. Every time a human edits an agent’s proposal, what was once silent expertise becomes a structured signal.
Every decision follows the same arc
A decision trace captures the full arc of a single decision.
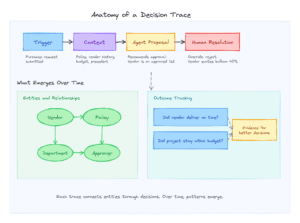
It starts with a trigger (a purchase request, an escalation, a renewal). The agent gathers context: policy, historical data, entities involved. It makes a proposal: approve, reject, escalate, or approve with conditions.
A human makes a resolution: agree, modify, or override. When the human overrides, the trace captures why. The agent said approve. The reviewer said reject because this vendor’s quotes always balloon 40%. That reasoning is now structured data.
Finally, the outcome closes the loop. Did the vendor deliver on time? Did the project stay within budget? Without outcome data, you have opinions. With it, you have evidence for which overrides produce better results.
You do not need to build this capture infrastructure from scratch. AI observability platforms like Arize AX instrument your agents automatically, recording every tool call, every piece of context retrieved, and every proposal and resolution as a structured trace.
Over time, entities and relationships emerge across traces. Vendors, departments, policies, and approvers, all connected through decisions. A vendor appears across dozens of traces. A policy that gets consistently overridden reveals itself as outdated. The graph grows richer with every decision.
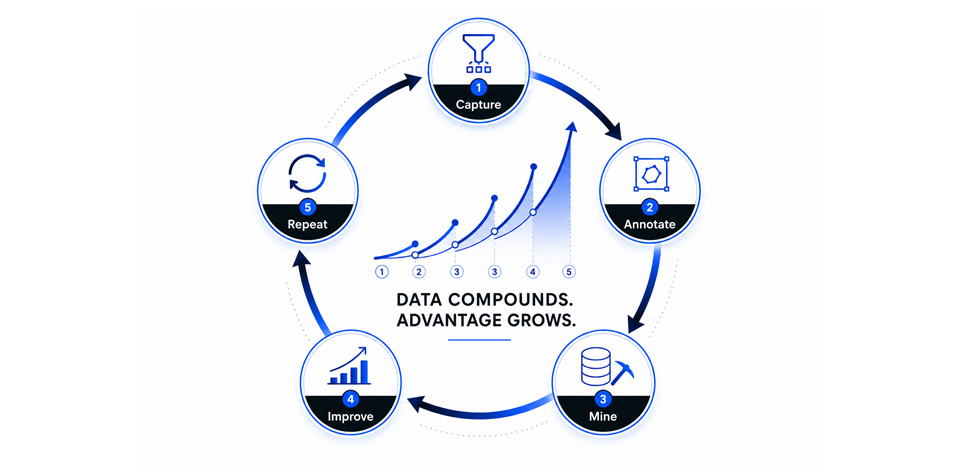
The loop compounds with every cycle
That growing graph is where the B2C analogy becomes structural. Google observes a click, the ranking improves, the next search is better, more users come, more signal accumulates. Twenty years of this created a moat no competitor has overcome.
The enterprise decision trace loop could work the same way, but the feedback would be deliberate, not automatic. An agent proposes. A human corrects. The trace captures the correction. But the agent does not learn from it on the next run. Instead, traces accumulate in an observability platform, where they become a structured, queryable dataset. An organization could then mine those traces to discover patterns and use what it finds to improve the agent: updating rules, refining prompts, and changing code.
Annotation could make the traces richer still. Reviewers and domain experts annotate decisions directly in the observability platform: flagging correctness, adding context that was not captured at decision time. Each annotation is another datapoint enriching the signal for mining. The traces become more valuable after capture, not just at capture.
Imagine a concrete example. An agent recommends approving a vendor on the approved list. A reviewer overrides: this vendor’s quotes always balloon 30 to 40%. That trace joins dozens of others involving the same vendor. Mining reveals the pattern across eight requests. The vendor lookup tool gets updated to surface cost history. The evaluator prompt gets modified to weight vendor track record more heavily.
Now the agent handles obvious vendor risk correctly. The reviewer’s overrides shift to subtler cases: maybe the overrun is category-specific. Those subtler corrections produce new traces, get annotated, get mined, and drive the next round of improvements. Each cycle would capture knowledge that was invisible in the previous cycle because it was buried under more obvious patterns.
Capture, annotate, mine, improve, and repeat. This could be the first compounding loop enterprise software has ever had.
Who owns the data?
The industry is arriving at this insight from multiple directions. Foundation Capital’s context graphs thesis frames decision traces as a trillion-dollar platform opportunity: agent startups sit in the write path where decisions happen. Salesforce and Snowflake do not. CrewAI’s “entangled software” describes the same loop from the product side: systems that reshape themselves through use. LangChain’s Viv Trivedy is asking how agent memory architecture handles the hyper-exponential data agents produce over months and years.
The common thread: frameworks and execution layers are commoditizing. The durable value is in what accumulates through use. We wrote about this in January when the Foundation Capital essay first circulated, and what we observed then has only accelerated. Agent traces are not telemetry. They are not debugging exhaust. They are durable business assets.
Where these perspectives diverge matters. Proprietary compounding loops (learning locked inside one vendor’s platform) versus open, queryable decision history (an organizational asset that lives in your data lake, not someone else’s). When decision traces are stored in standard, interoperable formats, they are portable. When they are locked inside a platform, switching means rebuilding the compounding loop from scratch.
Coming next: the demo
Everything above is conceptual, but the substrate already exists. Arize AX instruments agents automatically and captures every trace (trigger, context, proposal, resolution, outcome) in open, queryable formats that live in your data lake, not behind a vendor’s API. Reviewers annotate traces directly. Patterns surface across thousands of decisions. Teams mine what they find to update rules, refine prompts, and improve agents, and the next round of traces captures the next layer of knowledge. The loop is no longer hypothetical; it simply has not been demonstrated end-to-end yet. That is what comes next.
B2C built trillion-dollar empires on behavioral traces over twenty years. The enterprise equivalent is finally possible: built on decision traces, owned by the organizations that produce them, compounding from the first capture. The only question is who starts building it first.