


Model swaps look like configuration changes, but they behave more like product migrations.
A new model may be cheaper, faster, easier to get capacity for, or stronger on public benchmarks. The API call may barely change. From the outside, swapping models can look as simple as changing a model name in a config file.
But the product question is harder: if you change only the model, does the system still behave the way users expect?
That question matters more for agents than for single-turn prompts. An agent is not just a model call. It is a model operating inside a harness: instructions, tools, schemas, state, retries, rate-limit handling, output expectations, and evals.
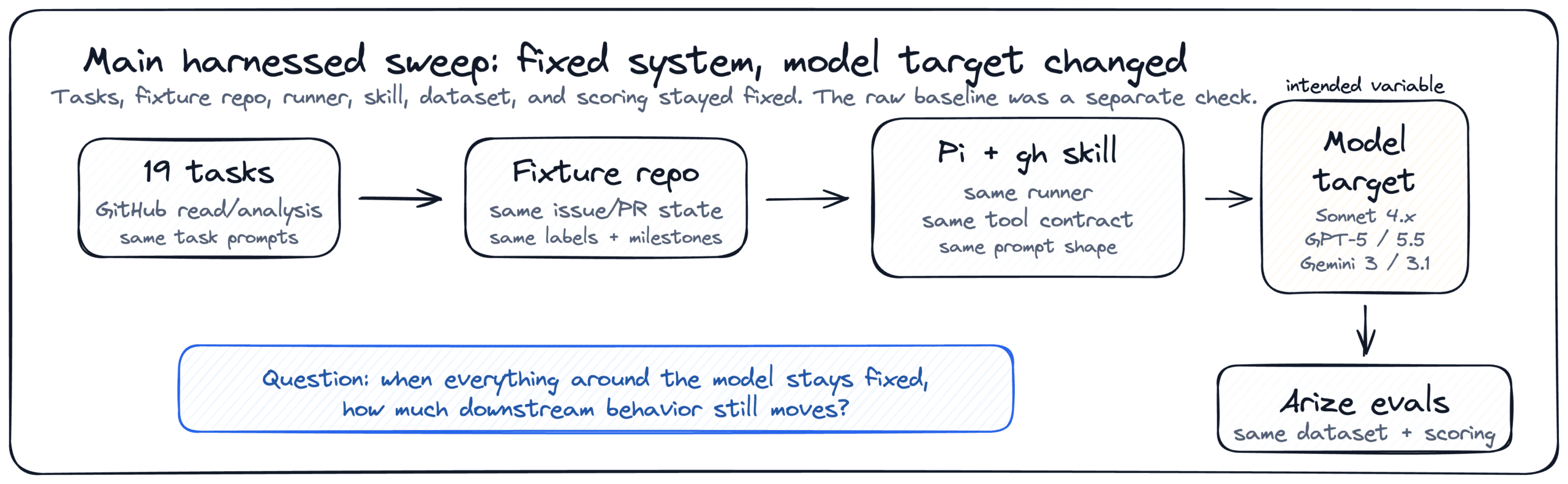
We ran the same pi.dev + GitHub CLI agent harness across seven model targets: Sonnet 4.0, Sonnet 4.5, Sonnet 4.6, GPT-5, GPT-5.5, Gemini 3.1 Pro, and Gemini 3 Flash. Only the model changed.
The results were mixed in the way production results usually are. Correctness stayed relatively close across models, but operational behavior moved more: latency, tool-call counts, retry behavior, and timeout risk.
That is the real lesson: a model swap is not safe just because the final answer still looks right. You need to know what the system has to do to get there.
TL;DR
We tested seven models on the same GitHub agent tasks using the same pi.dev + GitHub CLI harness and Arize evaluator setup. The goal was to see what changed when only the model changed.
Key findings:
- Correctness stayed relatively close, but not identical. The harnessed runs clustered between 79.6% and 85.1% correctness.
- Operational behavior moved more than final-answer quality. Models differed significantly in latency, tool calls, retries, and timeout risk.
- Final-answer evals are not enough. Two models can both get the right answer while imposing very different cost, latency, and fragility on the system.
- The harness appeared to reduce drift, but did not eliminate it. The result supports the stable harness hypothesis, but does not prove the harness caused all of the stability.
- Model swaps should be treated like migrations. Before routing production traffic to a new model, evaluate both answer quality and the path the agent took to get there.
The experiment
We used a controlled GitHub-ops benchmark. The code and task harness live in acme-agent-evals, and the fixture is a fictional Acme SDK repository seeded with issues, pull requests, labels, milestones, comments, and realistic repo state.
The tasks are the kinds of things a GitHub agent should be able to do:
- Count open bugs.
- Find issues with zero comments.
- Identify PRs without reviews.
- Compare milestone contents.
- Audit labels, linked PRs, and issue metadata.
The important part: the harness stayed fixed.
Every model got the same task text, the same fixture repo, the same gh CLI access, the same pi.dev runner, the same GitHub CLI skill, and the same Arize evaluator suite. Only the model target changed.
We ran seven models:
- Claude Sonnet 4.0
- Claude Sonnet 4.5
- Claude Sonnet 4.6
- GPT-5
- GPT-5.5
- Gemini 3.1 Pro
- Gemini 3 Flash
The main sweep covered 19 read and analysis tasks. Each model ran the full task set ten times.
19 tasks x 7 models x 10 runs = 1,330 attempted examples
The evaluators scored correctness, output quality, efficiency, latency, and tool adherence. Correctness was the primary metric. We also scored output quality, efficiency, latency, and tool adherence. For operational behavior, we put more weight on raw measurements: average latency seconds, tool calls, tool errors, and timeouts.
In Arize, evaluators are customizable checks that return structured results such as a score, label, and explanation. For this benchmark, correctness scored answers against task-specific expected outputs. Output quality used an LLM judge for harder analysis tasks, scoring completeness, accuracy, and organization. Efficiency was a tool-call-count heuristic, latency score bucketed raw latency seconds, and tool adherence checked whether the run stayed on the expected GitHub CLI tool path.
The tables below use 10 runs per model, for 1,330 scored task attempts. Timeouts and failed attempts are included rather than removed.
What we found
Result 1: correctness moved, but stayed in a relatively tight band
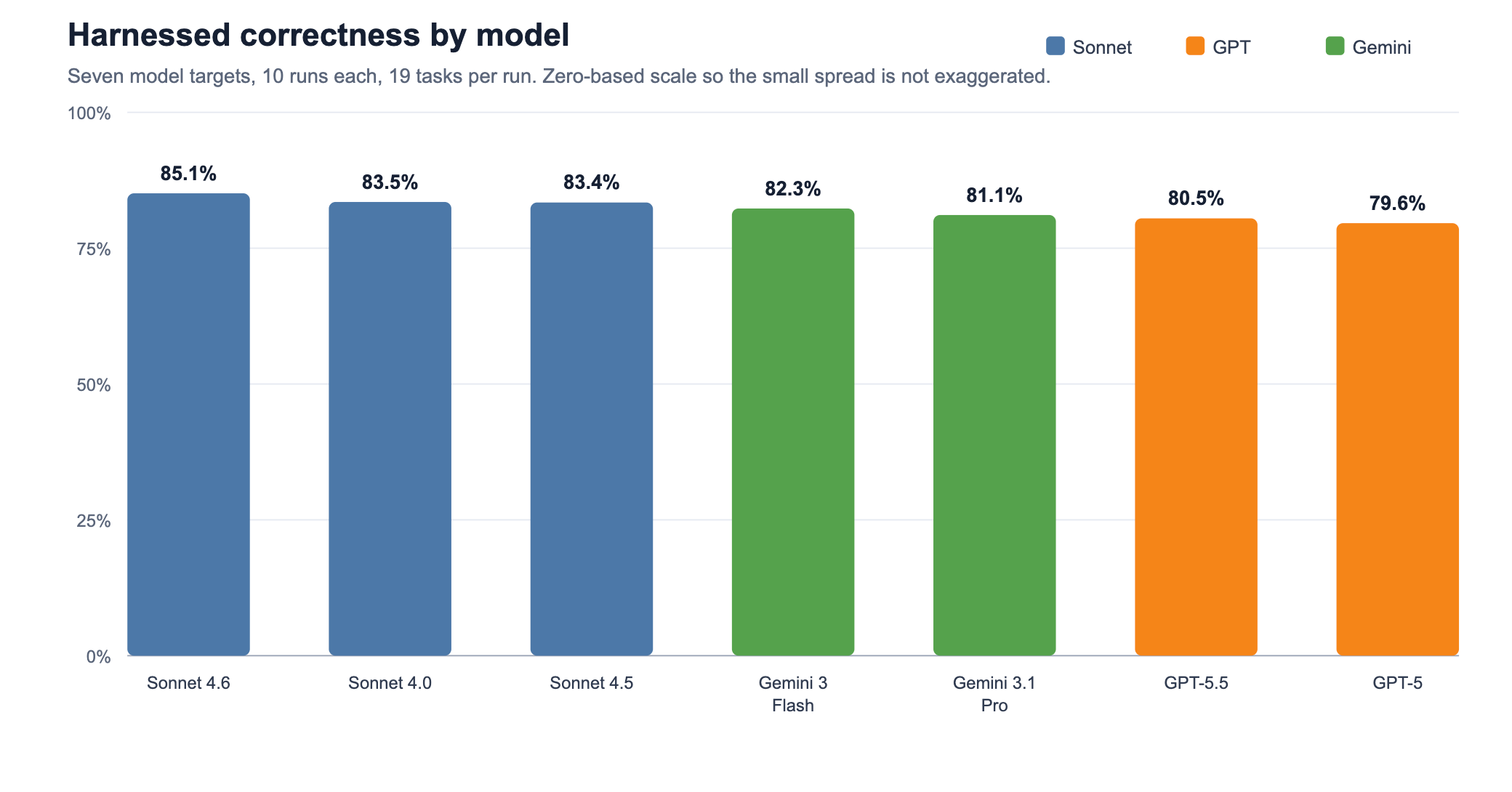
In the harnessed sweep, the seven model targets clustered between 79.6% and 85.1% correctness. Sonnet 4.6 was highest in this run; GPT-5 was lowest. Gemini 3 Flash landed at 82.3%, and Gemini 3.1 Pro landed at 81.1%.
That matters: under the fixed harness, behavior was relatively stable across providers, but the models were not equivalent. This shows that, under a fixed harness, model differences were measurable but contained enough to compare meaningfully.
| Model | Runs | Examples | Correctness | Output quality | Efficiency | Latency score | Tool adherence | Avg latency seconds | Avg tool calls |
|---|---|---|---|---|---|---|---|---|---|
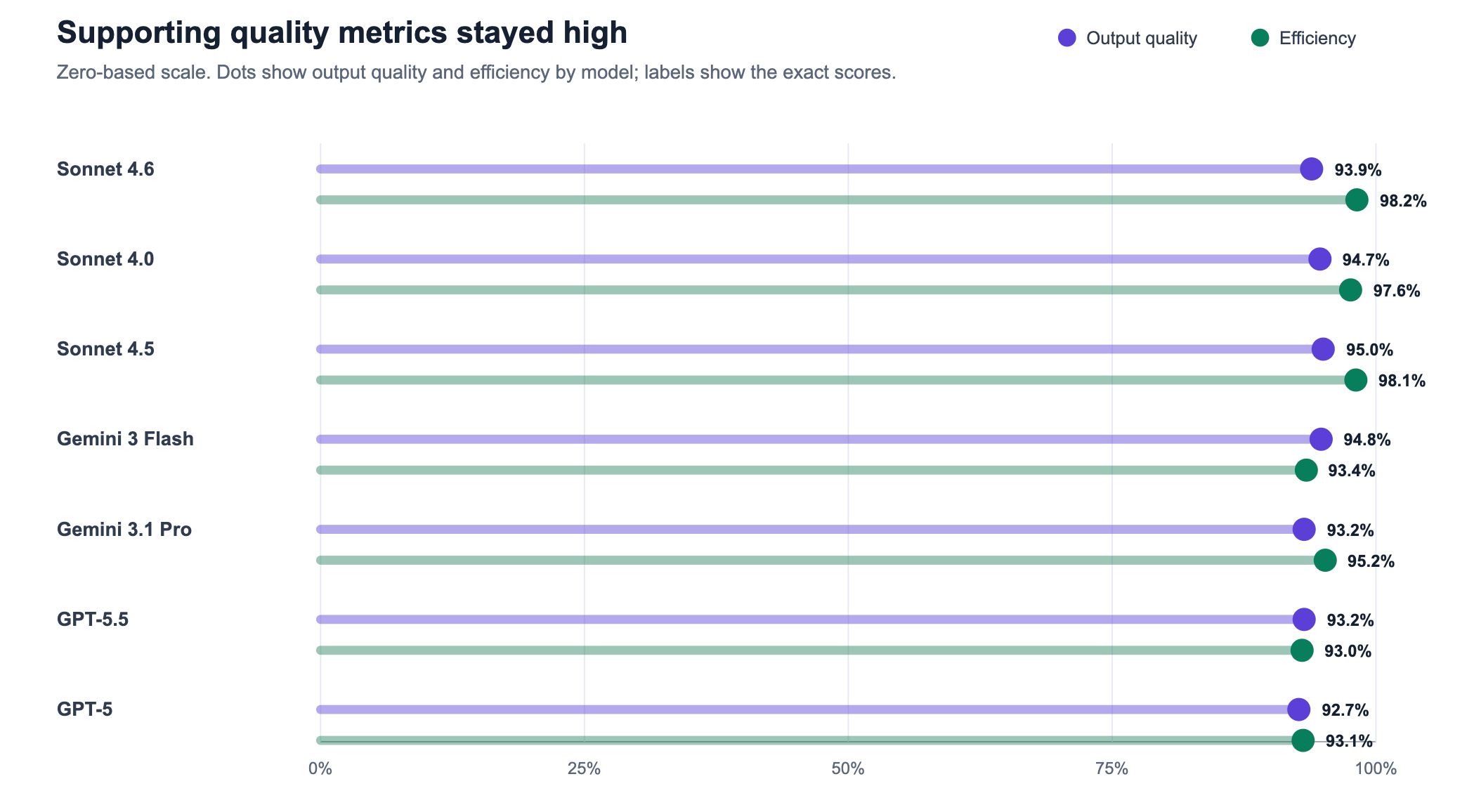
| Sonnet 4.6 | 10 | 190 | 85.1% | 93.9% | 98.2% | 100.0% | 100.0% | 9.5 | 1.45 |
| Sonnet 4.0 | 10 | 190 | 83.5% | 94.7% | 97.6% | 96.4% | 100.0% | 17.0 | 2.36 |
| Sonnet 4.5 | 10 | 190 | 83.4% | 95.0% | 98.1% | 97.8% | 100.0% | 16.1 | 1.84 |
| Gemini 3 Flash | 10 | 190 | 82.3% | 94.8% | 93.4% | 96.1% | 100.0% | 20.2 | 5.82 |
| Gemini 3.1 Pro | 10 | 190 | 81.1% | 93.2% | 95.2% | 92.3% | 100.0% | 28.7 | 2.64 |
| GPT-5.5 | 10 | 190 | 80.5% | 93.2% | 93.0% | 96.1% | 100.0% | 18.4 | 3.39 |
| GPT-5 | 10 | 190 | 79.6% | 92.7% | 93.1% | 87.1% | 100.0% | 32.2 | 3.14 |
The best and worst harnessed model slices were separated by 5.5 percentage points of correctness.
That is the first useful result: in this setup, changing only the model did not completely change answer-level behavior, but it also did not leave behavior unchanged.
It did not mean the models behaved the same. Output quality and efficiency stayed high too, but the larger practical split appeared in operational behavior.
Result 2: final-answer correctness hid larger operational drift
The bigger differences showed up in how the models got to the answer.
Sonnet 4.6 averaged 9.5 seconds per task and 1.45 tool calls. GPT-5 averaged 32.2 seconds and 3.14 tool calls. GPT-5.5 was faster than GPT-5 at 18.4 seconds, but still averaged 3.39 tool calls. Gemini 3 Flash landed at 20.2 seconds and used the most tools at 5.82 calls per task. Gemini 3.1 Pro averaged 28.7 seconds and 2.64 tool calls.
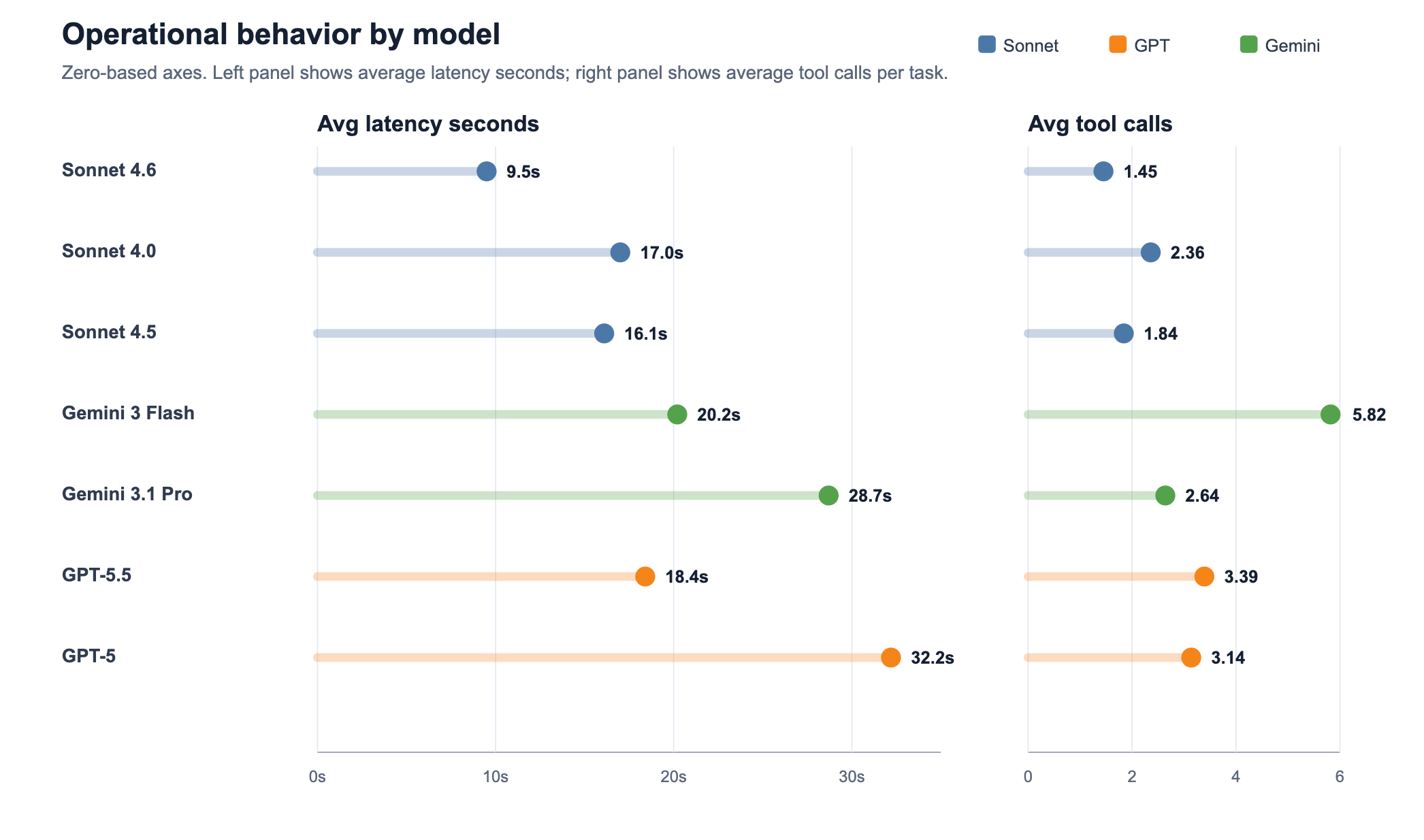
That matters in production.
A user may see the same final answer while the system absorbs very different latency, retry risk, timeout risk, and tool traffic. If your eval only checks final correctness, you will miss that difference.
For example, two models can both answer a milestone-comparison task correctly. One may get there with a single targeted gh query. Another may issue several redundant issue and PR lookups before producing the same answer. Both runs may pass a correctness check, but they have very different cost, latency, and failure exposure.
This is the part of model drift that is easy to miss. It does not always show up as “the answer is wrong.” Sometimes it shows up as “the product is slower, more expensive, more fragile, or more dependent on retries.”
Result 3: Tool adherence saturated
Tool adherence saturated across the clean model-behavior rows. That is good news. It means the models generally stayed on the allowed tool path in the harnessed run. It is also a warning.
Once a metric nearly saturates, a binary “did it use tools?” check stops telling you much.
The next question is tool discipline:
- Did the model choose the smallest useful
ghquery? - Did it avoid unnecessary retries?
- Did it handle pagination and empty states?
- Did it transform JSON deterministically?
- Did it use the tool when it should, instead of asking the user for help?
Tool adherence is a guardrail. It is not the whole eval.
Then we removed the harness
To check whether the harness itself was doing useful work, we ran the same 19 tasks through a raw baseline: direct model API calls with a small JSON protocol for requesting safe read-only gh commands.
This was not meant to compare pi.dev against raw API calls as products. It was a stress test: how much behavior changes when the task stays fixed but the agent scaffold is reduced?
This comparison is intentionally imperfect. The raw runner still had access to GitHub, but it did not get the full agent harness and received less scaffolding around how to ask for tools. That makes it useful as a stress test, not a final verdict on raw model calls. It also allowed us to ask a narrower question: what changes when the task stays the same, but most of the agent scaffold goes away?
| Model | Pi correctness | Raw correctness | Pi tool adherence | Raw tool adherence | Raw runner errors |
|---|---|---|---|---|---|
| Sonnet 4.6 | 85.1% | 77.2% | 100.0% | 98.9% | 0 |
| Sonnet 4.0 | 83.5% | 80.4% | 100.0% | 96.8% | 0 |
| Sonnet 4.5 | 83.4% | 77.7% | 100.0% | 92.6% | 0 |
| Gemini 3 Flash | 82.3% | 73.6% | 100.0% | 98.4% | 8 |
| Gemini 3.1 Pro | 81.1% | 71.7% | 100.0% | 90.5% | 4 |
| GPT-5.5 | 80.5% | 74.0% | 100.0% | 94.7% | 1 |
| GPT-5 | 79.6% | 72.5% | 100.0% | 99.5% | 0 |
Raw correctness was lower for every model in this run. The drop was small for Sonnet 4.0 and larger for Gemini 3.1 Pro, Gemini 3 Flash, GPT-5, and Sonnet 4.6. The raw runner also exposed a different failure mode: 13 task attempts exceeded the eight tool-round limit, mostly on Gemini.
That does not mean raw model calls are always bad, or that this harness is better for every workload. It means this benchmark behaved more reliably when the model operated inside a fuller agent harness. One likely reason is that the harness reduced the amount of protocol design each model had to rediscover on every task.
What this means
The result is consistent with the stable harness hypothesis. It does not prove that the harness caused all of the stability we observed.
The careful version: In this read-task benchmark, a fixed pi.dev plus gh skill harness kept seven model targets in a relatively tight correctness band. It did not eliminate drift. Model choice still mattered, and much of the visible spread showed up in operational behavior: latency, tool calls, timeouts, recovery, and command efficiency.
That is still useful.
For product teams, model upgrades should be treated like migrations, not vibes. You need to know whether the system still behaves acceptably after the model changes. That means measuring both final-answer quality and the path the agent took to get there.
If you measure only correctness, you may conclude the models are interchangeable. If you measure only latency, you may miss that a slower model is more complete. The useful view is both:
Did the model get the job done, and what did the system have to do to make that happen?
What to do before you swap models
The practical lesson is to treat model swaps like migrations.
- Freeze the harness: same tools, prompts, fixture, dataset, and scoring.
- Run enough repeats to separate signal from noise.
- Score both final-answer quality and operational behavior.
- Inspect task-level failures instead of stopping at the average.
- Use the failures as the migration plan before changing production traffic.
Stable harnesses need stable measurements. When scores move, the tempting story is “the model changed.” Sometimes the task changed. Sometimes the fixture changed. Sometimes the judge was underspecified. If the task, fixture, or scoring changes underneath the model, you are no longer measuring model drift cleanly.
Can you swap models safely? Yes, sometimes. But only when the eval says the behavior still meets the product bar. A model card can tell you what changed in the model. Your traces, evaluator results, and experiment comparisons tell you what changed in your product.