


The Evaluator
Your go-to blog for insights on AI observability and evaluation.
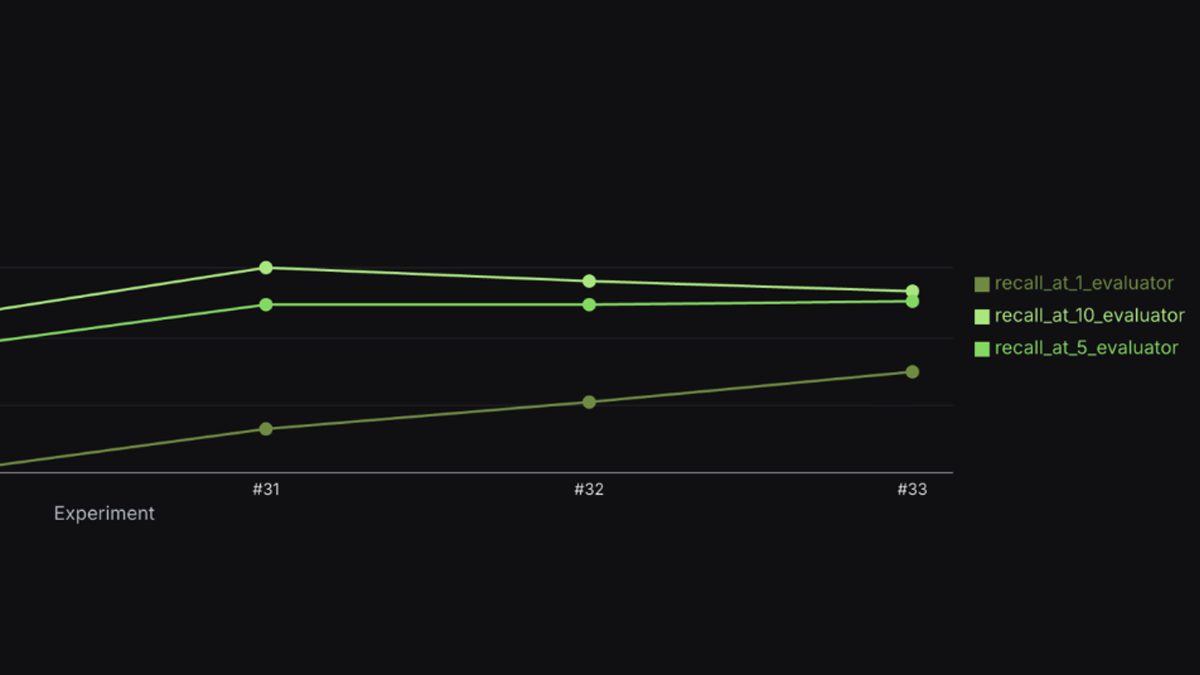
How Arize Skills Improved RAG Recall from 39% to 75% in 8 Hours
The Pain of Iterative RAG Development If you’ve built a production RAG system, you know this cycle. Tweak parameters, re-index, re-evaluate, repeat. It’s slow. It’s manual. The feedback loop between…

From First Eval to Autonomous AI Ops: A Maturity Model for AI Evaluation
Every team runs evals. Almost none have an evaluation practice. The difference is the gap between a one-off notebook and a system that continuously assesses, alerts, and acts on what…

100 AI Agents Per Employee: The Enterprise Governance Gap
100 AI agents per employee: The enterprise governance gap NVIDIA CEO Jensen Huang recently described a future where companies operate with roughly 100 AI agents per employee. That future is…
Sign up for our newsletter, The Evaluator — and stay in the know with updates and new resources:

Managing Memory in AI Agents: Beyond the Context Window
This is part two of our deep dive series on how we built Alyx 2.0, our AI engineering agent. Watch us discuss it above, or keep reading for the full…

Why Banks Adopt the Arize Ecosystem
This post covers the organizational and regulatory patterns that shape AI platform decisions in banking, and why the Arize ecosystem aligns with how these institutions actually operate. Federated Architectures …

Arize AX Adds Native Support for NVIDIA NIM as AI Model Provider
We’re excited to announce that Arize AX now supports NVIDIA NIM as a native AI model provider. Enterprises running NIM-deployed models can now connect them directly to the Arize platform…

How We Used Evals (and an AI Agent) to Iteratively Improve an AI Newsletter Generator
We love building little AI-powered tools that accelerate our workflows. One we built recently is a tool that takes our recent tweets and uses Claude to create a draft of…
Arize Skills: Coding Agent Workflows for Traces, Evals, and Instrumentation
Two weeks ago we launched Alyx 2.0, the AI engineering agent inside Arize AX. Last week we launched the AX CLI, which made your trace data headless and agent-readable. Today…
How to Build Planning Into Your Agent (The Architecture That Actually Works)
2025 was supposed to be the year of agents. And for the most part, it wasn’t. The industry was full of hype, demos looked incredible, but when you actually tried…
From UI to Terminal: Bringing Alyx’s Superpowers Into Your Coding Agent
Last week we launched Alyx 2.0, the in-app AI engineering agent for Arize AX. Alyx replaced clicking through the UI with natural language intent. The AX CLI takes it a…


