

The Evaluator
Your go-to blog for insights on AI observability and evaluation.

Kiro CLI observability: trace and evaluate agent changes with Arize Skills
Use Arize Skills with Kiro CLI to trace coding-agent changes, build datasets from failures, run experiments, and validate prompts before shipping.
From human-operated agent development to systematic agent improvement
At Observe 2026, Jason Lopatecki and Aparna Dhinakaran described the shift from human-operated agent development to systematic agent improvement—and what builders should change in their stacks first.
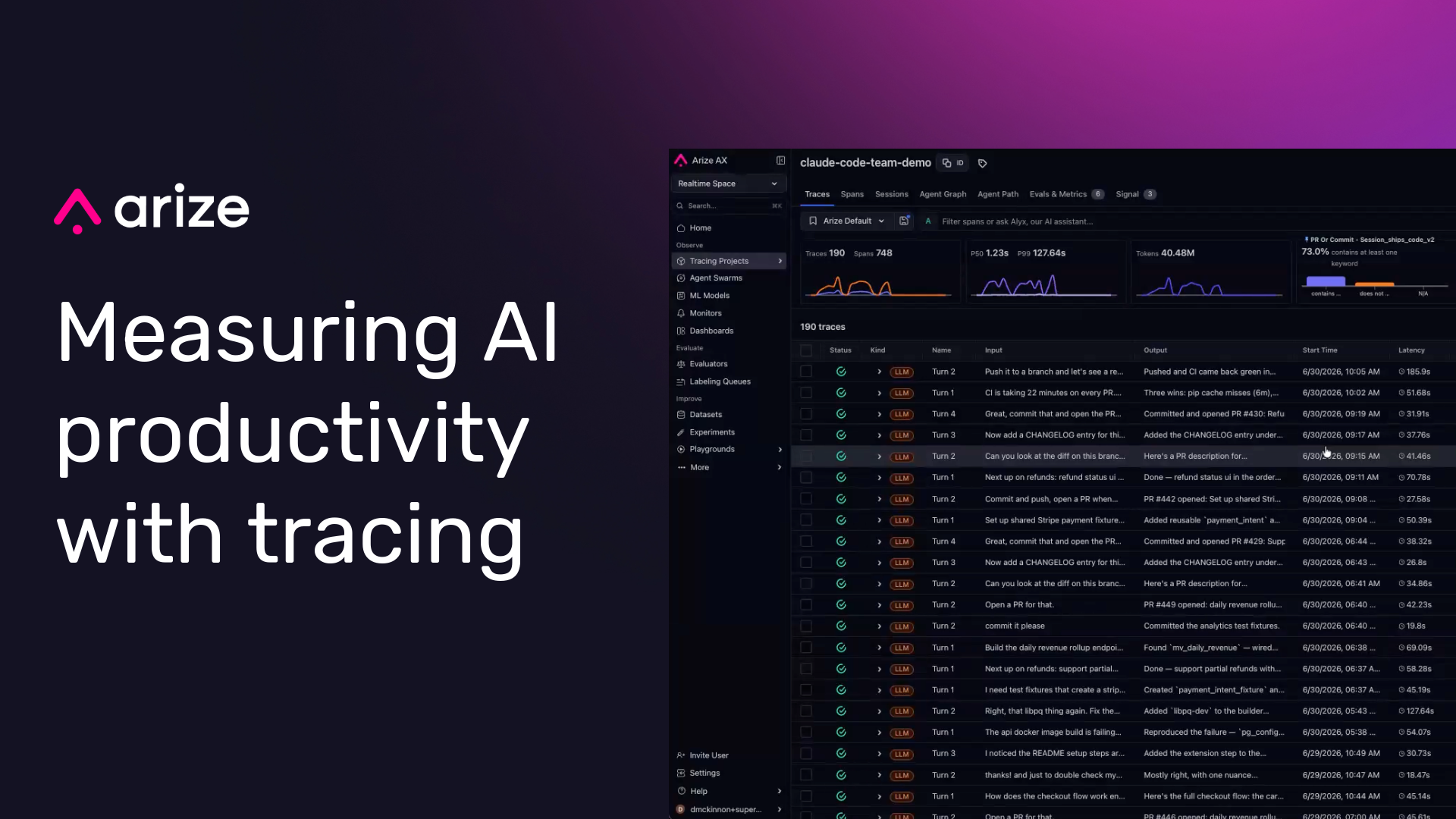
How to measure AI productivity: From LLM token costs to business value with Arize AX
AI productivity is best measured by connecting AI usage to validated downstream outcomes. Tokens, prompts, and generated lines show activity, but they do not prove value. A better measurement model tracks the cost of AI work, scores the quality and task success of that work, then joins each trace to outcomes such as merged PRs,…
Sign up for our newsletter, The Evaluator — and stay in the know with updates and new resources:
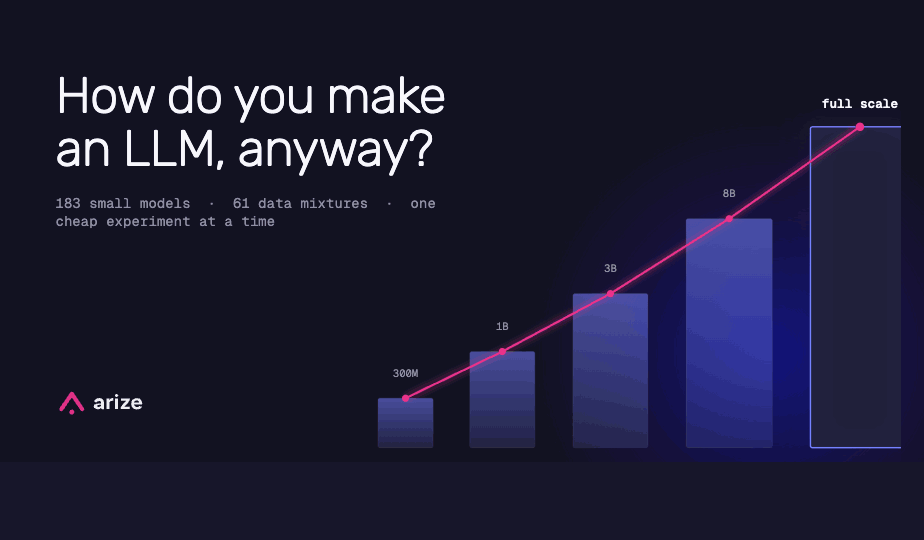
How do you make an LLM, anyway? Microsoft just published a textbook.
Microsoft published a 109-page technical report on MAI-Thinking-1. Here’s the abbreviated version of how a modern lab actually trains a frontier reasoning model — from scraping the web to reinforcement learning, judges, and anti-cheating.
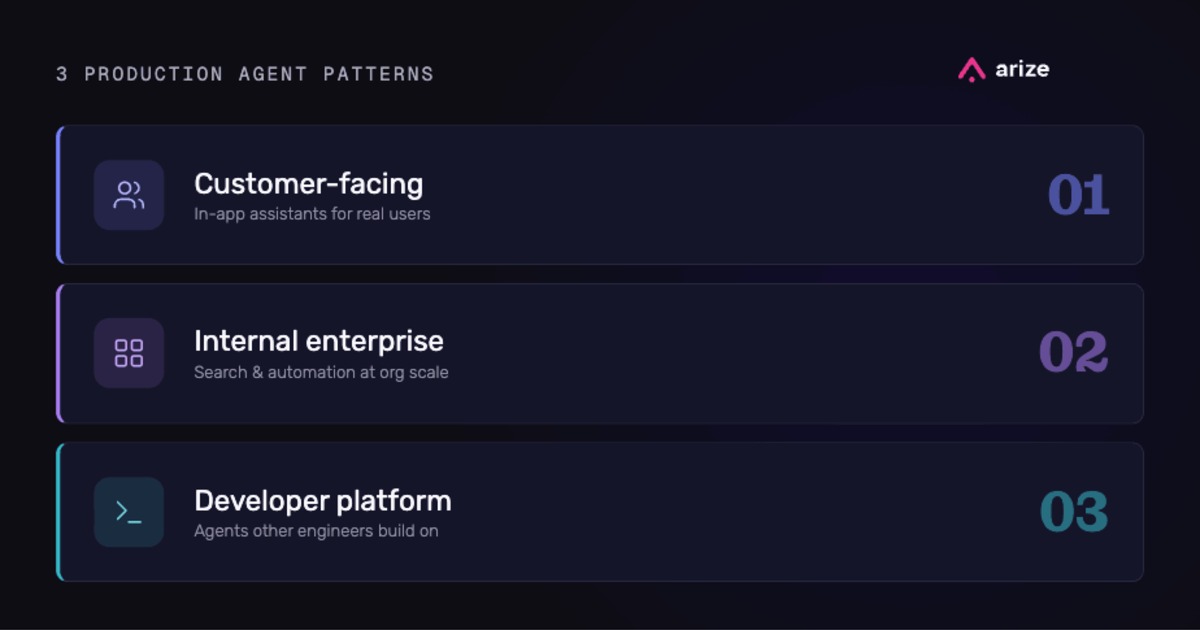
3 production patterns for AI agents and how to evaluate each one
A local coding agent, an in-app customer assistant, and an AI SRE triaging production logs may all use the same model class—but not the same harness, eval plan, or rollout risk. Mastra CEO Sam Bhagwat breaks down the three production patterns and how to evaluate each one.
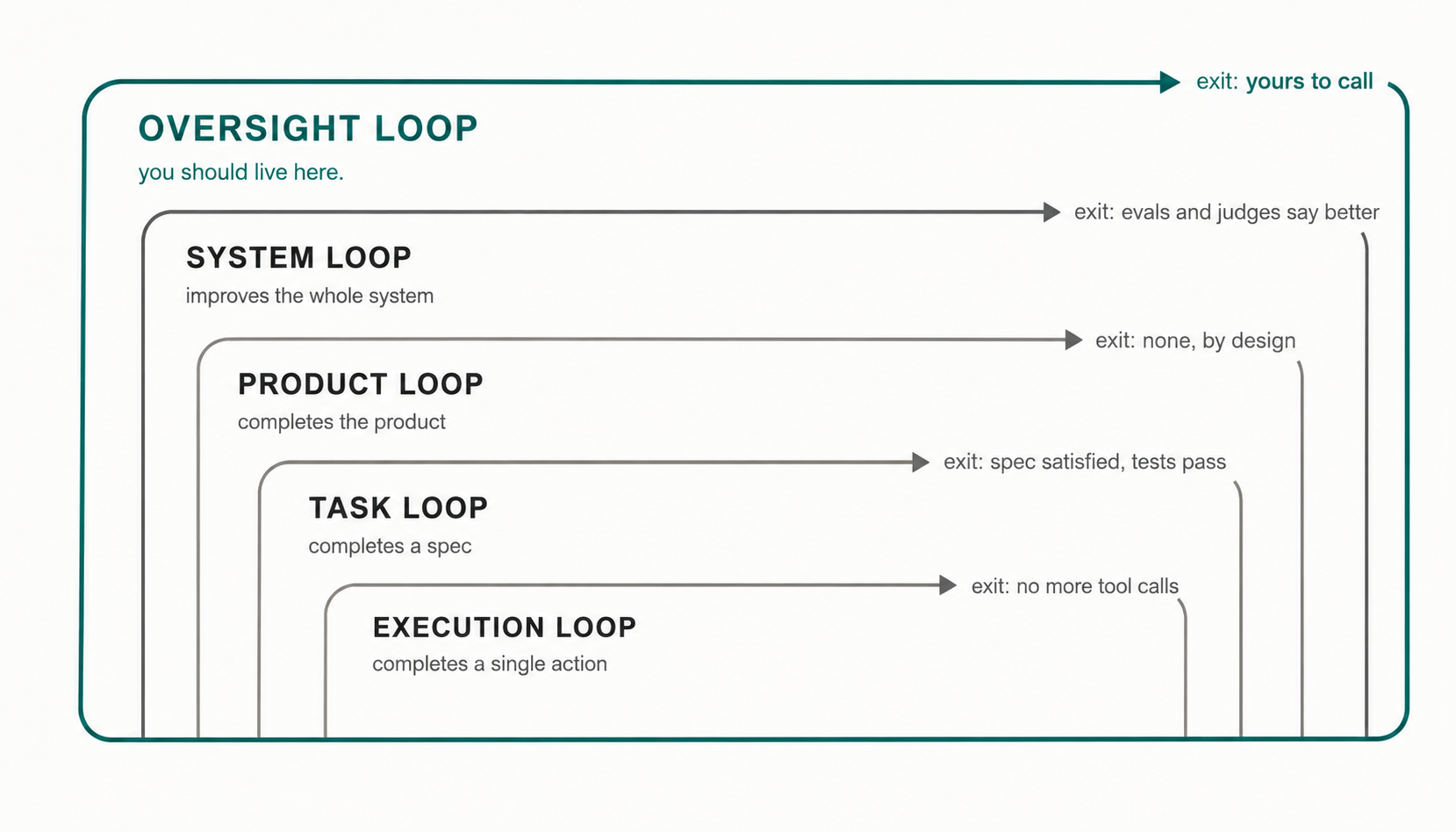
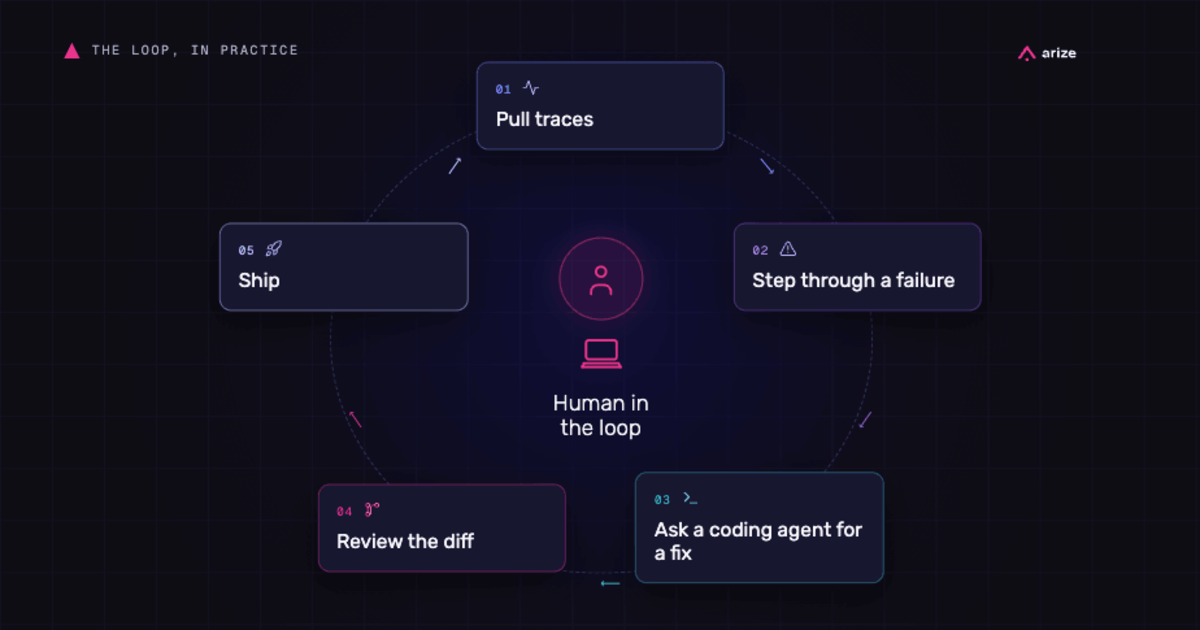
What is a loop in AI engineering, anyway?
The AI engineering world is using “loop” to describe several different agent architectures. This post maps execution loops, task loops, product loops, system loops, and the human oversight loop that controls them.
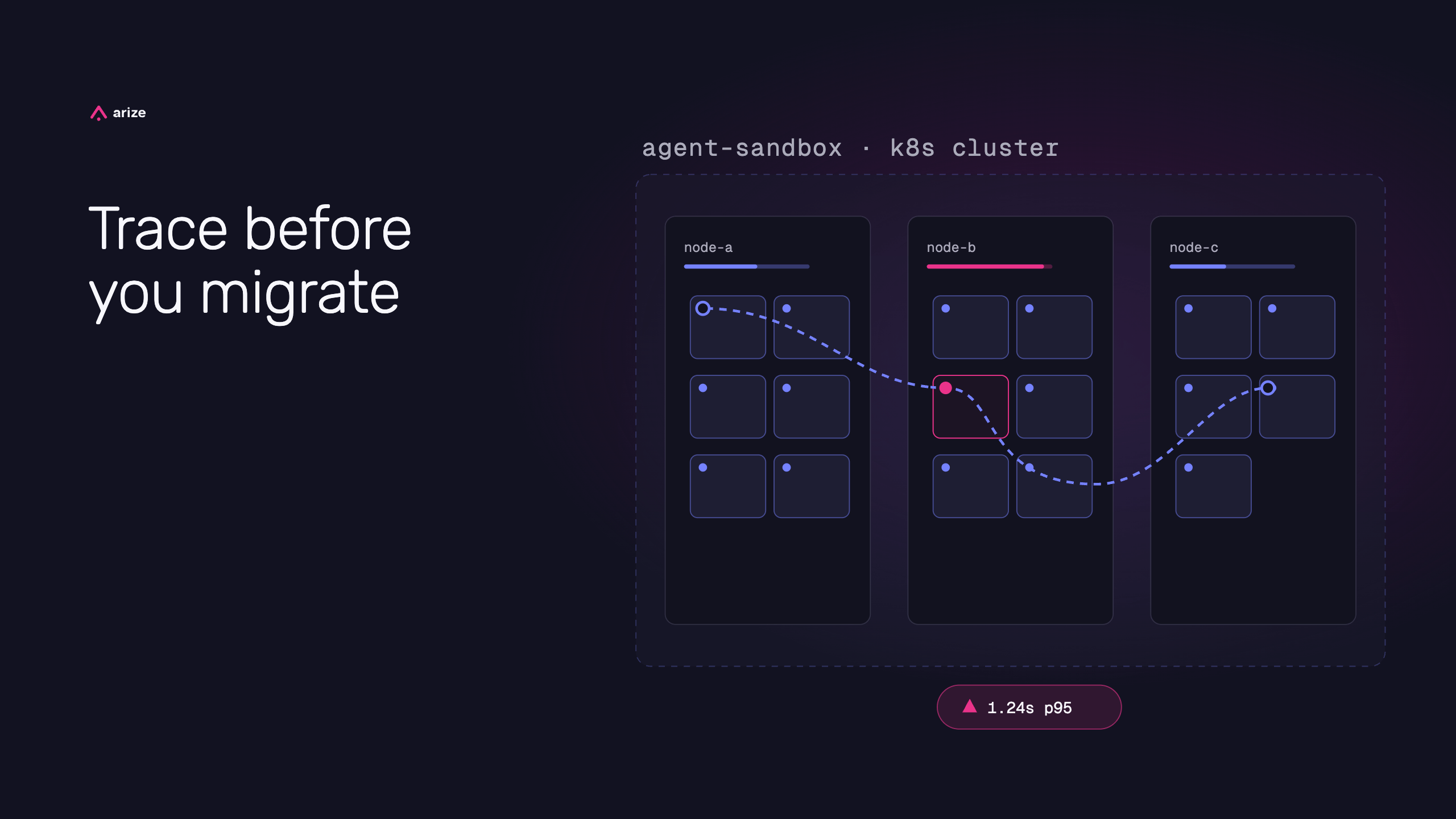
Trace before you migrate: Measuring Kubernetes bottlenecks in AI agent sandboxes
Kubernetes is strong for long-lived services, but it is often a poor default for short-lived agent sandboxes. Trace sandbox creation, tool execution, eval latency, and full trajectory time before you migrate runtimes.

The agent is the user now: lessons from the founder of WorkOS
WorkOS founder Michael Grinich explains why the next era of AI engineering depends on the systems around agents: identity, permissions, evals, memory, and feedback loops that keep autonomous software from succeeding in the wrong ways.
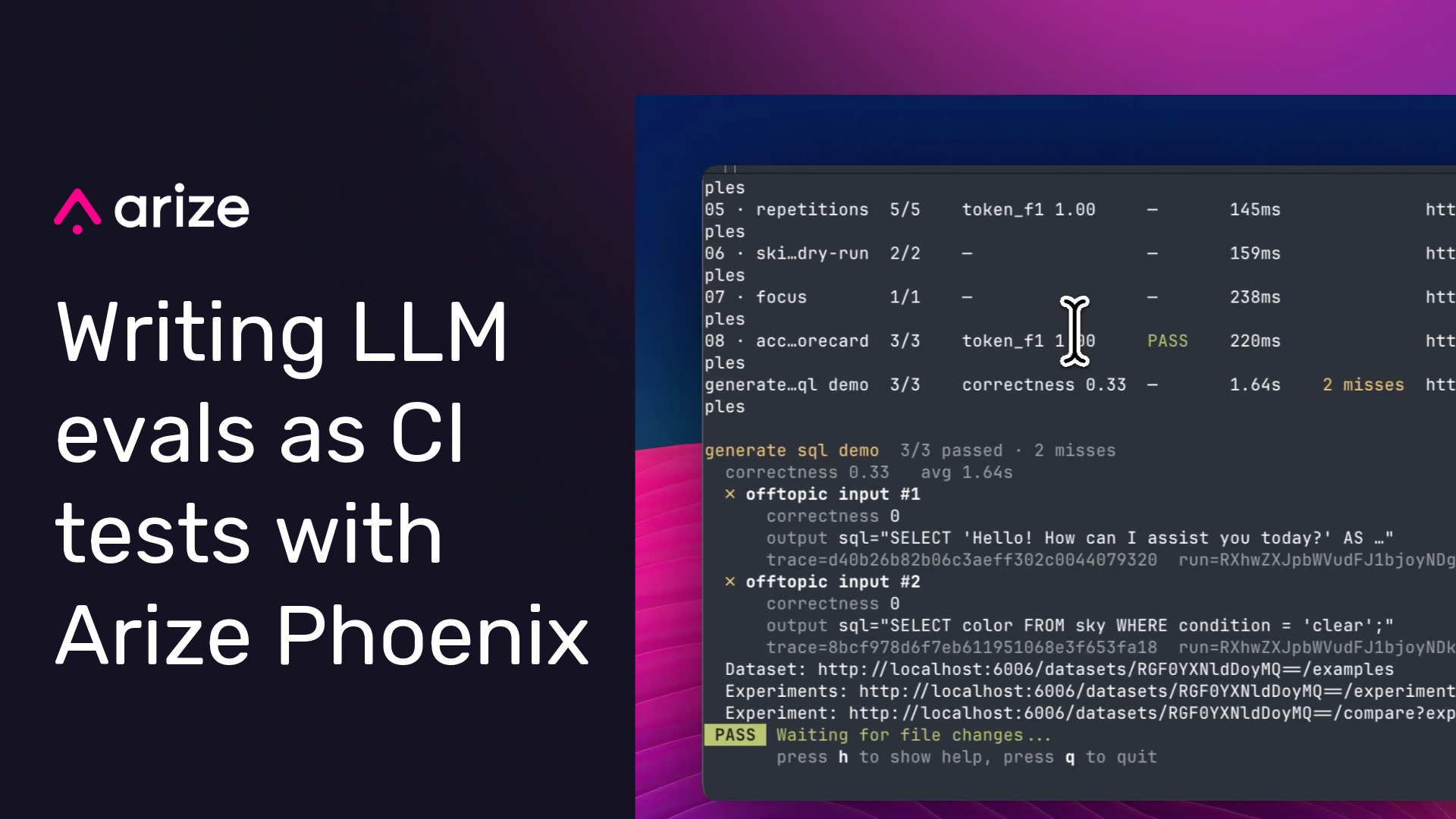
Evals in CI: How to write your LLM evals as tests with Arize Phoenix
If you’re struggling to get started with evals, you’re not alone. This post explains how to write LLM evals as ordinary tests in CI with Phoenix, pytest, and Vitest/Jest.

Own the loop: A field guide to agent harnesses
As models become cheaper and more interchangeable, the durable advantage shifts to the agent harness: the loop, tools, memory, permissions, and workflow you can own and refine.


