



AI Evals for Engineers & PMs is a popular, hands‑on Maven course led by Hamel Husain and Shreya Shankar. The course’s goal is simple: “teach a systematic workflow for evaluating and improving LLM applications.”
During the last cohort of the course, several guest lecturers were invited to speak and assign homeworks based on their open source offerings – including the Arize Phoenix team.
The Recipe Bot homework series, which we integrated Phoenix into, is a pragmatic example of the evaluation loop the course teaches you from start to finish – starting with prompt design and iteration on through synthetic‑data‑driven error analysis, LLM‑as‑judge evaluators, retrieval testing for RAG, and state‑level error analysis.
This blog includes all of the course homeworks from the last class, with each lesson broken down into steps each with its own video and notebook.
Repos for all of the homeworks are available here.
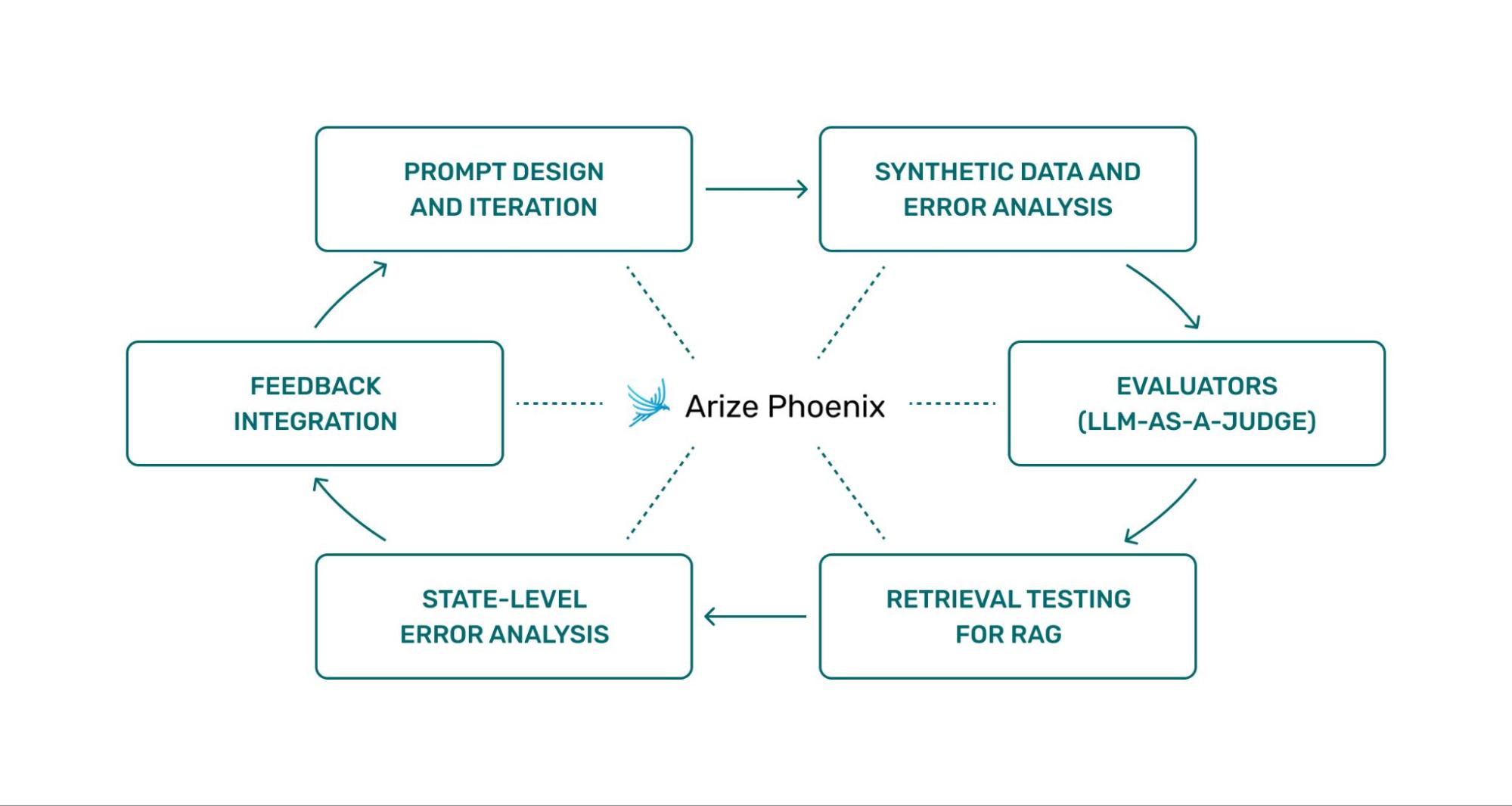
Step 1: Prompt Design and Iteration
The opening stage of the course focuses on prompt design.
In our homework on the recipe bot, a placeholder instruction is replaced with a structured system prompt that encodes explicit responsibilities, formatting rules, and response style. Expanding the query dataset from a handful of examples to a more diverse set creates the first opportunity to observe variability: some responses produce structured step-by-step recipes, others revert to loosely formatted paragraphs.
Example query sets:
| Initial Queries (seed) | Expanded queries (added for diversity) |
| Give me a dessert recipe with chocolate | Quick vegan breakfast with fewer than 5 ingredients |
| I have chicken and rice, what can I cook | Quick recipe suitable for a beginner cook. |
| Suggest a vegan breakfast recipe. | Advanced American lunch with strict Whole30 compliance |
Phoenix is used to log each prompt revision with version metadata and associated model parameters. Batched evaluations are run across the query set, with latency, token usage, and cost tracked automatically. Outputs from multiple prompt versions are then compared side by side in the Phoenix UI.
This allows you to quantify the impact of incremental edits—whether adding constraints reduced variance in formatting, or whether introducing stylistic guidelines improved consistency at the cost of additional tokens.
The workflow treats prompt iteration not as trial-and-error in an isolated notebook, but as a repeatable experimental loop: design, run, measure, and compare.
Step 2: Synthetic Data and Error Analysis
Next, we move onto synthetic data and error analysis.
After stabilizing the baseline prompt for the recipe bot, we stress test with controlled variation.
By defining categorical dimensions—such as dietary restriction, cuisine type, meal type, and skill level—that together span hundreds of possible query combinations, we then sample a subset and convert it into natural language requests through llm_generate. This produces diverse queries like “advanced vegan American lunch” or “gluten-free Mexican dinner,” each structured to probe the system along a distinct axis.
Example query sets with annotations:
| Initial Queries (seed) | Expanded queries (synthetic) | Example annotation (error analysis) |
| Give me a dessert recipe with chocolate | Quick vegan breakfast with fewer than 5 ingredients | Includes heavy cream → violates vegan constraint |
| I have chicken and rice, what can I cook | Gluten-free Mexican dinner suitable for beginners | Recipe contains flour tortilla → not gluten-free |
| Suggest a vegan breakfast recipe. | Advanced American lunch with strict Whole30 compliance | Recipe used unsweetened dried fruit → not compliant with Whole30 |
Responses to these synthetic inputs can then be logged and inspected in Phoenix. Annotations are entered as free-text explanations of observed issues: violations of dietary constraints, missing steps in instructions, inconsistent tone, or overgeneralized answers. By exporting the annotations and clustering them, you can construct a taxonomy of failure modes. Rather than labeling outputs as simply correct or incorrect, you can identify recurring categories of breakdown.
Phoenix reduces overhead in this process by handling orchestration for data generation, capturing results as structured records, and linking annotations directly to traces. Once exported, the annotations form a dataset that can be used in downstream evaluation pipelines, providing both examples of errors and a principled way to classify them.
Step 3: Evaluators with LLM-as-a-Judge
With a failure taxonomy in place, the course next moves onto introducing evaluators. The objective here is to move from human annotation of errors to automated judgment using an LLM-as-a-judge.
For the recipe bot, the initial target criterion is dietary compliance: determining whether generated recipes respected constraints such as vegan, gluten-free, or Whole30.
A subset of traces is labeled with ground truth outcomes. These are stratified into train, validation, and test splits to ensure balanced representation of both passes and fails. Evaluator prompts are then written to classify outputs as pass or fail and to return an explanation. Early versions prove unreliable, often overlooking borderline cases—for instance, accepting honey in vegan recipes or failing to catch flour in diabetic-friendly requests.
| Initial Queries (seed) | Expanded queries (synthetic) | Example annotation (error analysis) | LLM-as-a-Judge output |
| Give me a dessert recipe with chocolate | Quick vegan breakfast with fewer than 5 ingredients | Includes heavy cream → violates vegan constraint | Pass (missed violation) |
| I have chicken and rice, what can I cook | Gluten-free Mexican dinner suitable for beginners | Recipe contains flour tortilla → not gluten-free | Fail (correct) |
| Suggest a vegan breakfast recipe. | Advanced American lunch with strict Whole30 compliance | Recipe used unsweetened dried fruit → not compliant with Whole30 | Pass (missed violation) |
Phoenix provides the infrastructure for iteration. Evaluator prompts can be executed against the dev set, with results logged alongside ground truths. Metrics such as balanced accuracy, true positive rate, true negative rate, and confusion matrices are computed automatically. Inspecting false positives and false negatives in the Phoenix UI highlights specific weaknesses, guiding prompt revisions. Refinements include explicit definitions of dietary categories, constraints on optional ingredients, and the addition of few-shot examples to handle known edge cases.
As evaluators improve, they are scaled to the full dataset of traces. Phoenix experiments preserve both the raw evaluator outputs and the derived metrics, enabling reproducibility and comparison across iterations. This exercise demonstrates how evaluators can evolve from brittle first drafts into dependable tools through systematic experimentation.
Step 4: Retrieval Evaluation for RAG
To mirror course material around retrieval augmented generation (RAG), we next move into a workflow that incorporates retrieval to extend the recipe bot into a RAG system.
A BM25 index is built over a corpus of recipes, and the query style shifts from open-ended requests to targeted fact-seeking prompts such as bake times, oven temperatures, or marinating steps. These queries require the retriever to surface precise evidence for downstream generation.
Each retrieval call is traced in Phoenix as a span containing the query, the ranked documents, token matches, and BM25 scores. This instrumentation exposes whether the correct recipe appears in the candidate set and at what rank. For example, “How long should a gingerbread castle bake for?” returns the expected recipe at rank one, while other prompts bury the relevant recipe deeper in the ranking or miss it altogether.
Phoenix experiments compute standard information retrieval metrics: Recall@K measures whether the correct recipe appeared in the top K results, while Mean Reciprocal Rank quantified its average position. Because retrieval performance directly shapes generation quality, these metrics serve as an upstream proxy for end-to-end accuracy.
To complement coverage metrics, Phoenix evaluators judge document relevance directly. For each retrieved document, an LLM classifier produces a binary relevance label with an optional explanation. This captures cases where the retriever surfaces documents containing overlapping tokens but irrelevant content. Combining recall, rank, and document relevance creates a more complete view of retrieval behavior: whether the correct evidence is retrieved, how high it appears, and whether the remaining documents are genuinely useful.
Step 5: State-Level Diagnostics with Evals
Again mirroring the course, the final stage for the recipe bot decomposes it into a multi-step pipeline with seven distinct states: request parsing, tool planning, recipe search, web search, argument generation, retrieval, and response composition. Each state has a clear contract, and failures in early stages could propagate downstream.
Phoenix traces the complete execution path for every query, recording inputs and outputs at each state. Evaluators are then attached at the state level, each defined with explicit pass/fail criteria. For instance, in a request for an oatmeal breakfast, both parsing and planning correctly capture the requirement, but the “generate recipe args” state drops the oatmeal filter. That omission prevents the retriever from selecting the right recipes – and as a result, the composed response excludes oatmeal entirely. The evaluator flags this state as failed, with an explanation identifying the missing filter.
Aggregated across many traces, the evaluations reveal systematic weaknesses. Failures concentrate heavily in web search, with moderate incidence in parsing and planning, while response composition shows relatively few issues. Phoenix surfaces these distributions directly in the UI, allowing you to quantify reliability at the level of individual pipeline components rather than treating the system as a black box.
Explanations are not limited to error tagging. They are passed through an LLM again to synthesize recurring failure patterns, propose adjustments to prompts or arguments, and even generate candidate unit tests. This creates an iterative loop: traces are collected, evaluators judge outputs, explanations identify weaknesses, and those explanations then inform targeted modifications to the pipeline. The result is a closed feedback cycle where diagnostics and repair are tightly coupled.
Recap
The sequence of assignments trace the evaluation lifecycle for an LLM-powered system. At every step, Phoenix serves as the substrate for LLM logging, tracing, dataset versioning, and experiment management. Prompt variants, synthetic datasets, evaluator iterations, retrieval experiments, and state-level diagnostics are all captured as structured artifacts. This continuity allows you to move from isolated debugging to reproducible workflows that could scale with the complexity of the system.
If you enjoyed this tutorial, please star Arize Phoenix on GitHub!