
Arize AI Partners with Spell to Bring ML Observability to the Spell Platform

Krystal Kirkland
Software Engineer
This week we’re announcing our new partnership with Spell!
There is a vast difference between the offline environments where models are trained and production environments where they are served. This training/serving skew often leads to data science teams trying to troubleshoot their models performance once they are deployed. However, most machine learning teams have little to no telemetry about their models once they are deployed.
ML observability helps teams easily transition from research to production — maintaining the results delivered, and helping teams troubleshoot problems quickly — without eating up Data Science cycles. The ability to explain, understand and get answers quickly builds a necessary trust between research teams and end users.
Combining Spell model servers with Arize model observability lets you have the best of both worlds — easy-to-use autoscaling online model APIs, powerful model monitoring, explainability, and troubleshooting.
If you already are using Spell, the integration with Arize for Model Observability is easy. In this blog post we will showcase deploying a lightgbm churn prediction model on Spell that’s tracked and monitored using Arize.
Deploying a model server on Spell
To begin, we’ll need to train and save a model on Spell. We can do so using the following spell run command, which uses a training script from the spellml/examples GH repo:
$spell run \\ --github-url <https://github.com/spellml/examples> \\ --machine-type cpu \\ --mount public/tutorial/churn_data/:/mnt/churn_prediction/ \\ --pip arize — pip lightgbm \\ --python arize/train.py#replace $RUN_ID with the ID number of the run that just finished$spell model create churn-prediction runs/$RUN_ID
Next, we’ll need a model server script. This file will be used to serve the model and to log it to Arize. Here’s the one’s we’ll use:
` import os import uuid from asyncio import wrap_futureimport numpy as np import lightgbm as lgbfrom spell.serving import BasePredictor from arize.api import Clientclass PythonPredictor(BasePredictor): def __init__(self): self.model = lgb.Booster( model_file=”/model/churn_model/lgb_classifier.txt”) self.arize_client = Client(organization_key=os.environ[' ARIZE_ORG_KEY’], api_key=os.environ[‘ARIZE_API_KEY’]) self.model_id = ‘churn-model’ self.model_version = ‘0.0.1’async def predict(self, request): payload = request[‘payload’] #use np.round to squeeze to binary {0,1} results = list(np.round(self.model.predict(payload))) futures = [] for result in results: prediction_id = str(uuid.uuid4()) future = self.arize_client.log_prediction( model_id=self.model_id, model_version=self.model_version, prediction_id=prediction_id, prediction_label=bool(result) # {1,0} => {true,false}) future = wrap_future(future) # SO#34376938 futures.append(future)for future in futures: await future status_code = future.result().status_code if status_code != 200: raise IOError( f”Could not reach Arize! Got error code {status_code}.” ) response = {‘result’: results} return response `
The PythonPredictor class inherits from Spell’s BasePredictor class, which expects two functions: an __init__, which runs once at server initialization time, and a predict, which runs at model serving time.
In this example __init__ does two things: it loads the model artifact from disk, and it initializes the Arize Client we’ll use for observability logging. As a best practice, this client reads its authentication secrets (organization_key and api_key) from environment variables, which we’ll pass through to the server via Spell.
The predict method is what actually handles request-response flow. Spell will unpack the payload of the POST request and pass it to the request parameter. We then generate a model prediction (self.model.predict(payload)) and return it to the caller (return response).
However, before we return the response, we log the predicted value Arize first (makes a POST request to an Arize web endpoint) before returning to the caller:
future = self.arize_client.log_prediction(
model_id=self.model_id,
model_version=self.model_version,
prediction_id=prediction_id,
prediction_label=bool(result) # {1,0} => {true,false})
model_id and model_version identify this model to Arize (churn-model, version 0.0.1). prediction_id is a unique identifier for this specific prediction; the easiest way to create a UUID, which is what we did here (using uuid from Python stdlib).
The Arize API is asynchronous for performance, and returns a future as its result. In order to guarantee that the prediction actually gets logged, we need to ensure that this future resolves before the function exits and its contents gets garbage collected. To achieve this, we make the predict function asnyc, await every Arize request, and throw an error (which Spell will intercept and log) if the Spell server can’t reach the Arize server:
for future in futures:
await future
status_code = future.result().status_code
if status_code != 200:
raise IOError(
f”Could not reach Arize! Got error code {status_code}.”)
The demo repo also has a higher performance, fully async version of this script.
All that’s left now is deploying the server:
$ spell server serve \\ --node-group default \\ --min-pods 1 — max-pods 3 \\ --target-requests-per-second 100 \\ --pip lightgbm — pip arize \\ --env ARIZE_ORG_KEY=$ARIZE_ORG_KEY \\ --env ARIZE_API_KEY=$ARIZE_API_KEY \\churn-prediction:v1 serve_sync.py # or serve_async.py
At this point this model server should be up and running:
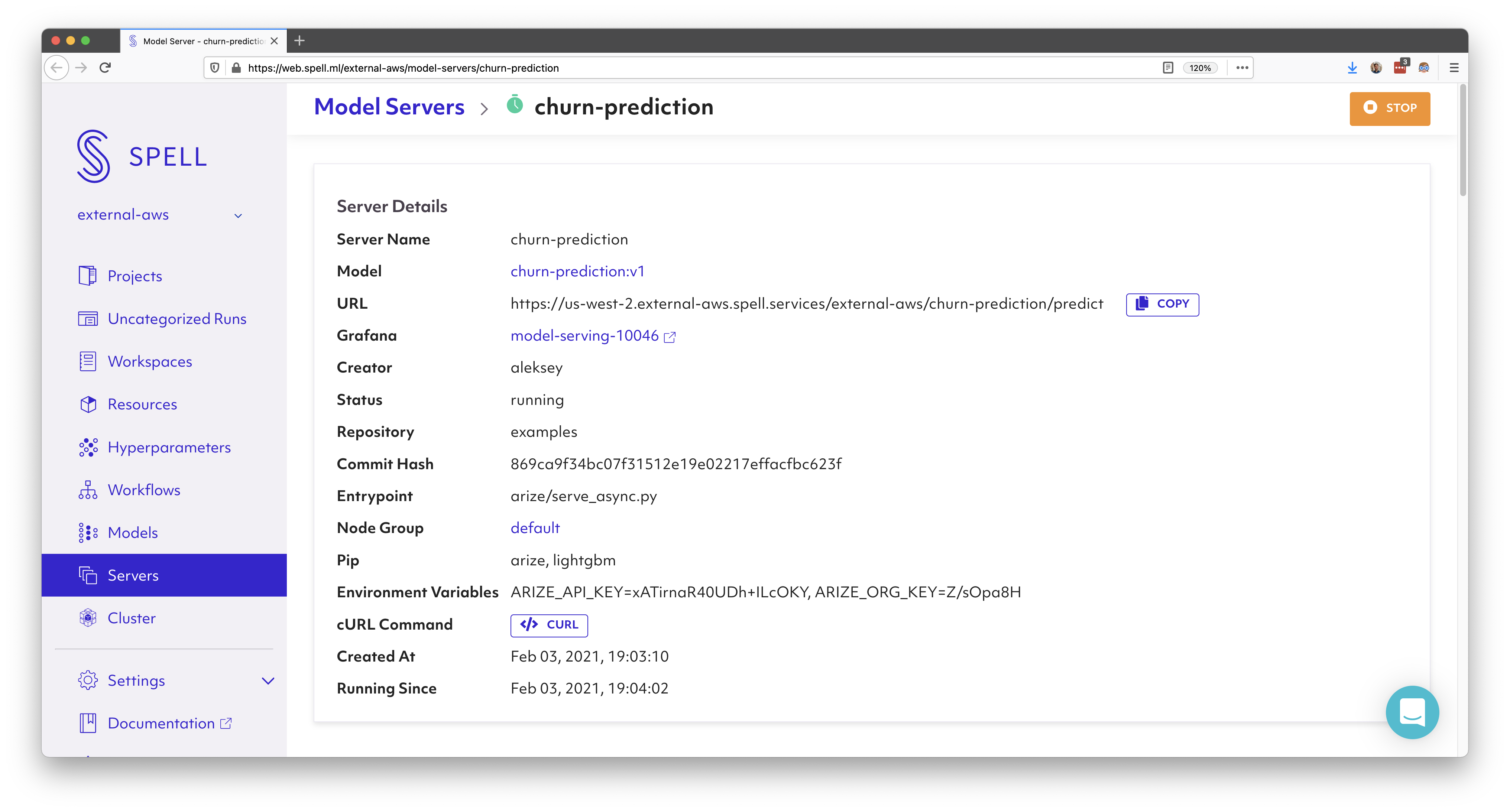
You can test everything works by running the following curl command (replacing the variables with the ones appropriate for your Spell cluster instance):
$ curl -X POST -d '@test_payload.txt' \\,
<.https://$REGION.$CLUSTER.spell.services/$ORGANIZATION/churn-
prediction/predict>
{"result":[1.0]}%
ML Observability with Arize
Once you’ve added this code snippet, your prediction events are logged to Arize and the platform discovers your model and sets up dashboards, monitors, and analytics for your predictions.
Default dashboards are set up to highlight important evaluation metrics and data metrics. Operational metrics from the Spell platform can also be sent to the Arize platform. The dashboards are customizable for your specific custom model metrics.
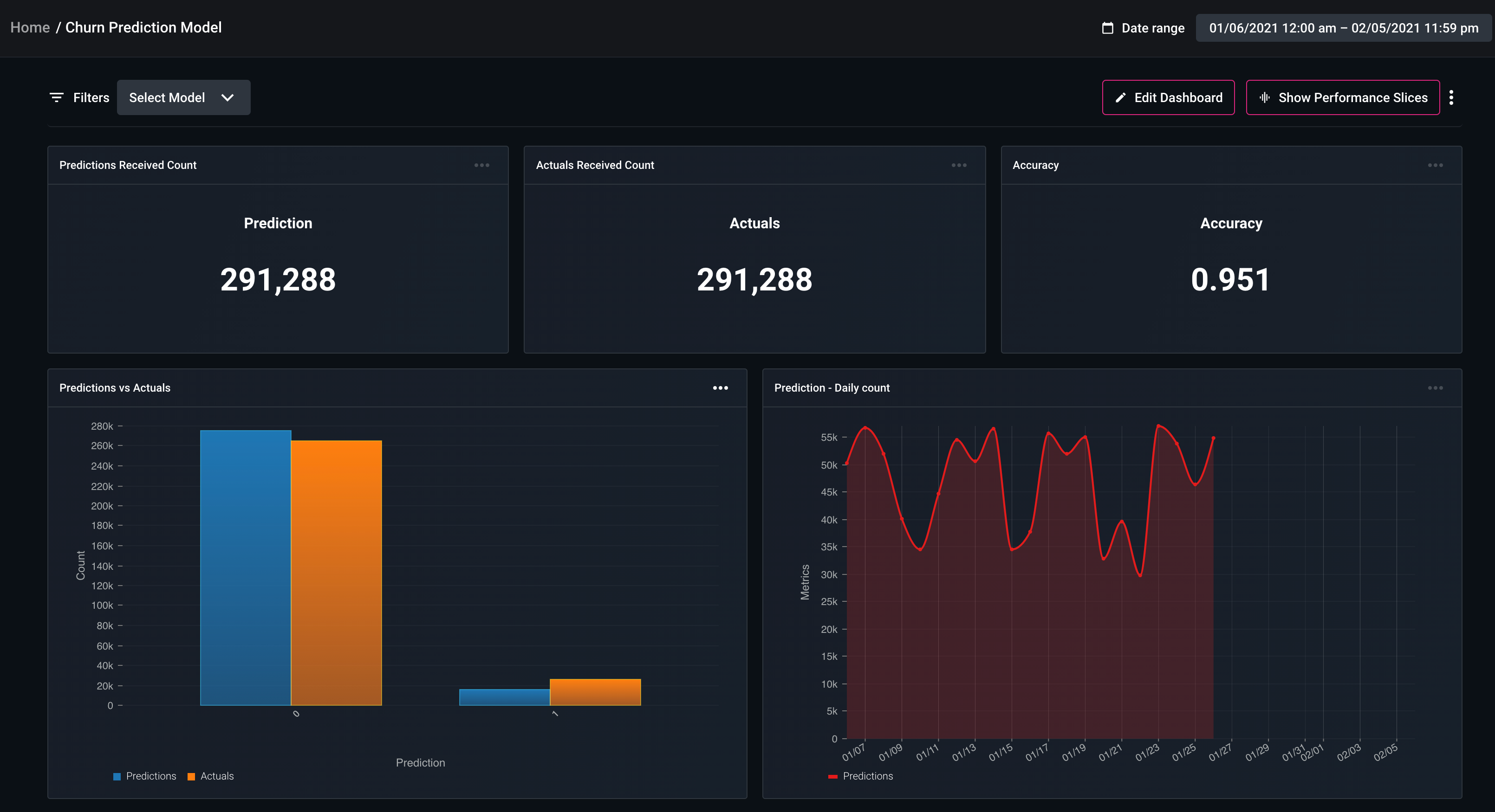
The Arize platform can log inferences across the entire ML Workflow — training, validation, and production. The platform sets up default dashboards for quick model analysis, but also has powerful tools for troubleshooting and analyzing prediction slices. The platform surfaces what data caused poor performance so it can be used for testing and retraining.
Monitoring your model with Arize
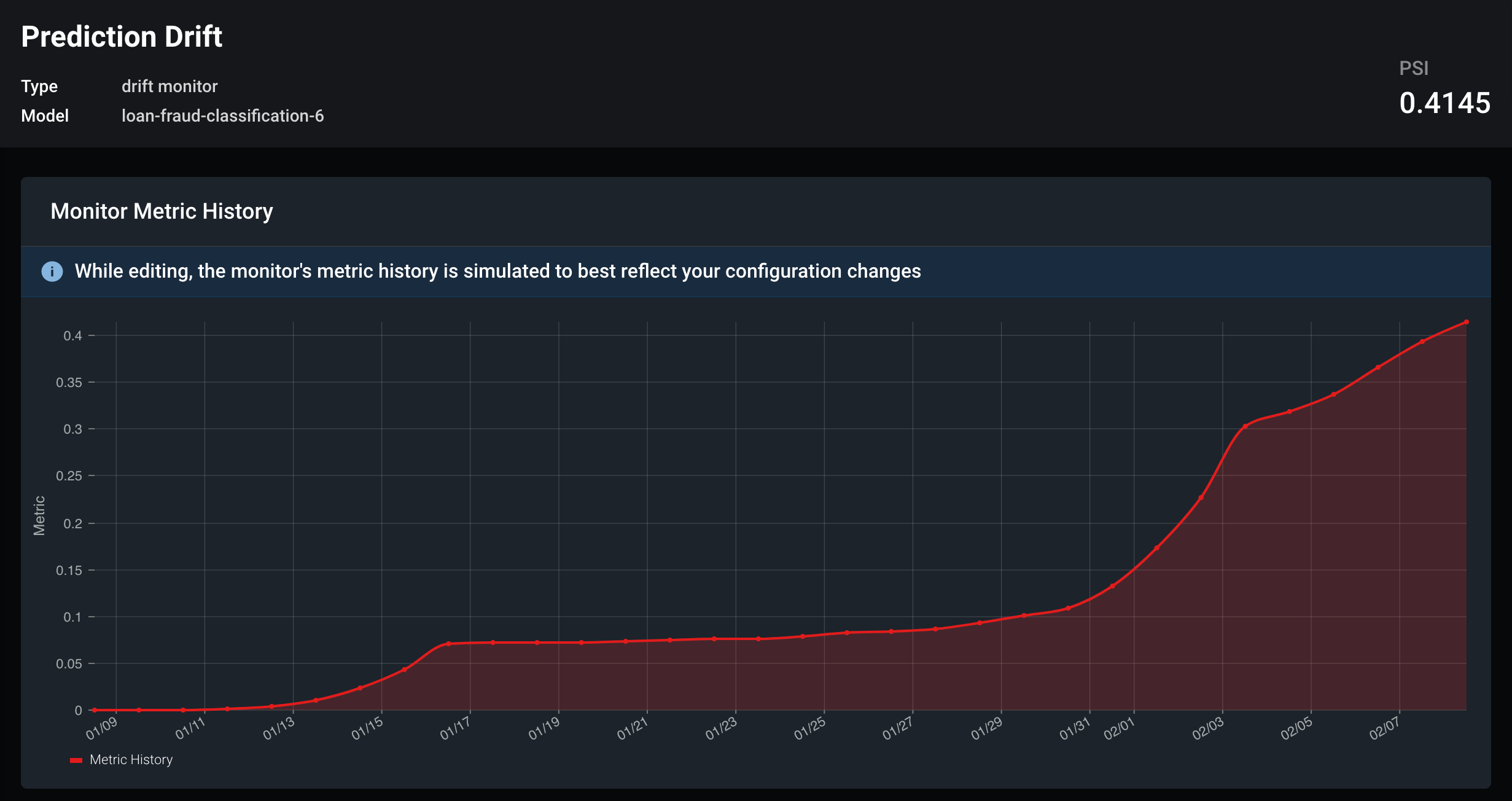
Models on Arize can be set up with drift, performance, and data quality monitors. Here is an example of a drift monitor setup on the predictions of a model. The PSI monitor can indicate when the predictions are drifting and the model needs to be revisited.
Getting Access to Spell and Arize
Through this partnership, the Spell and Arize platforms team up to make MLOps even easier. Spell users will have early access to Arize AI’s model observability platform. Arize users can leverage Spell as their powerful, iterative MLOps platform for building and managing machine learning projects.
About Arize
Arize AI is a Machine Learning Observabililty platform that helps ML practitioners successfully take models from research to production, with ease. Arize’s automated model monitoring and analytics platform help ML teams quickly detect issues the moment they emerge, troubleshoot why they happened, and improve overall model performance. By connecting offline training and validation datasets to online production data in a central inference store, ML teams are able to streamline model validation, drift detection, data quality checks, and model performance management.
Arize AI acts as the guardrail on deployed AI, providing transparency and introspection into historically black box systems to ensure more effective and responsible AI. To learn more about Arize or machine learning observability and monitoring, visit our blog and resource hub!
About Spell
Spell is the MLOps platform built to meet the unique challenges of operationalizing deep learning at scale. For engineers, it eliminates drudgery and enhances collaboration. For managers, it provides real-time project visibility and accountability. And for stakeholders, it reduces cost and shortens time to value.
Spell DLOps is comprehensive and inclusive, meeting the needs of the engineer, the team, and the enterprise for effective development, deployment, and management of deep learning models. Spell operates on public, private, and hybrid clouds, or on dedicated on-premises compute infrastructure. It easily integrates with existing workflows, frameworks, infrastructure, and datastores. Spell doesn’t force users to learn new deep learning tools and technologies; it makes existing ones easier to use.
To try the Spell platform, sign up here: spell.ml/get-started/
To request access to Arize, sign up here: https://arize.com/sign-in/