


Enterprises face a critical challenge in keeping their LLM models accurate and reliable over time. Traditional model improvement approaches are slow, manual, and reactive, making it difficult to scale and adapt to evolving data patterns. The Arize integration of NVIDIA NeMo empowers AI teams with an automated, self-improving AI data flywheel to enhance LLM performance.
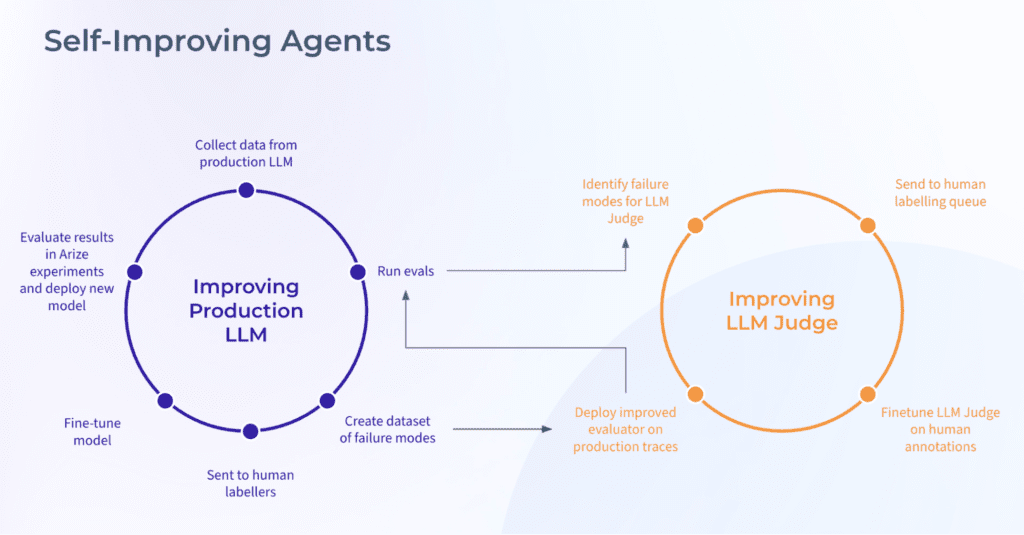
The powerful Arize solution automatically identifies production LLM failure modes through online evaluations, routes challenging cases for human annotation, and continuously refines models through targeted fine-tuning and validation against golden datasets—enabling enterprises to maintain optimal LLM performance through a streamlined human-in-the-loop workflow. By leveraging Arize’s AI-driven evaluation tools and datasets, alongside NVIDIA NeMo for model training, evaluation, and guardrailing, organizations can continuously improve and deploy state-of-the-art LLMs at scale.
Additionally, the same iterative loop can be applied to improve the accuracy and reliability of LLM-based Judge evaluators. In this workflow, examples with low-confidence evaluations are automatically aggregated and routed to human annotators, who provide correct labels. These annotated examples then drive targeted fine-tuning, ensuring continuous enhancement of Judge evaluator quality and consistency, enabling Judges to continuously improve alongside the production application. Over time, less and less human intervention is needed.
How it Works
- Identify Failure Modes: Automatically detect and log failure cases using Arize Online Evaluations, which supports both LLM-as-a-Judge and code evaluators.
- Targeted Annotation: Route critical examples through Arize’s labeling queue for expert human validation, only adding human-in-the-loop workflows when needed.
- Train Smarter: Arize automatically kicks off fine-tuning jobs using NeMo Customizer as new examples are added to the dataset, where the NVIDIA training configs can be fully configured in the Arize UI.
- Benchmark for Excellence: After fine-tuning, evaluations are automatically run on Arize golden datasets built from production data, as well as public benchmarks using NeMo Evaluator. This provides a final check that the fine-tuned model has improved before it is deployed.
- Assess Results: Evaluation results can be analyzed in further detail on the Arize Experiments page, where the model output, evaluation labels and aggregate metrics are displayed. This includes both custom datasets in Arize and academic benchmarks from NVIDIA’s eval harness.
- Enforce in Real Time: Once the fine-tuned LLM Judge meets performance standards, it is deployed in Arize online evals and NeMo Guardrails for real-time enforcement. Any unsafe or undesired outputs are blocked before reaching users, with every guardrails activation traced and logged in Arize for full observability.
Why it Matters
The Arize + NVIDIA NeMo integration eliminates bottlenecks in generative AI development, providing a no-code solution that empowers domain experts—regardless of coding ability—to actively drive model improvement workflows. This continuous, automated loop enables models to progressively enhance their performance without manual dataset curation or training job configuration by ML specialists. Human involvement is streamlined to efficient annotation tasks, significantly reducing the costs typically associated with model development. As a result, organizations can effortlessly scale their AI model improvement processes, consistently delivering more reliable and accurate generative AI applications at reduced operational cost.
Learn More
Attending NVIDIA’s GTC conference? Meet the Arize team!