






ML Infrastructure Tools for Production (Part 1)

Aparna Dhinakaran
Co-founder & Chief Product Officer
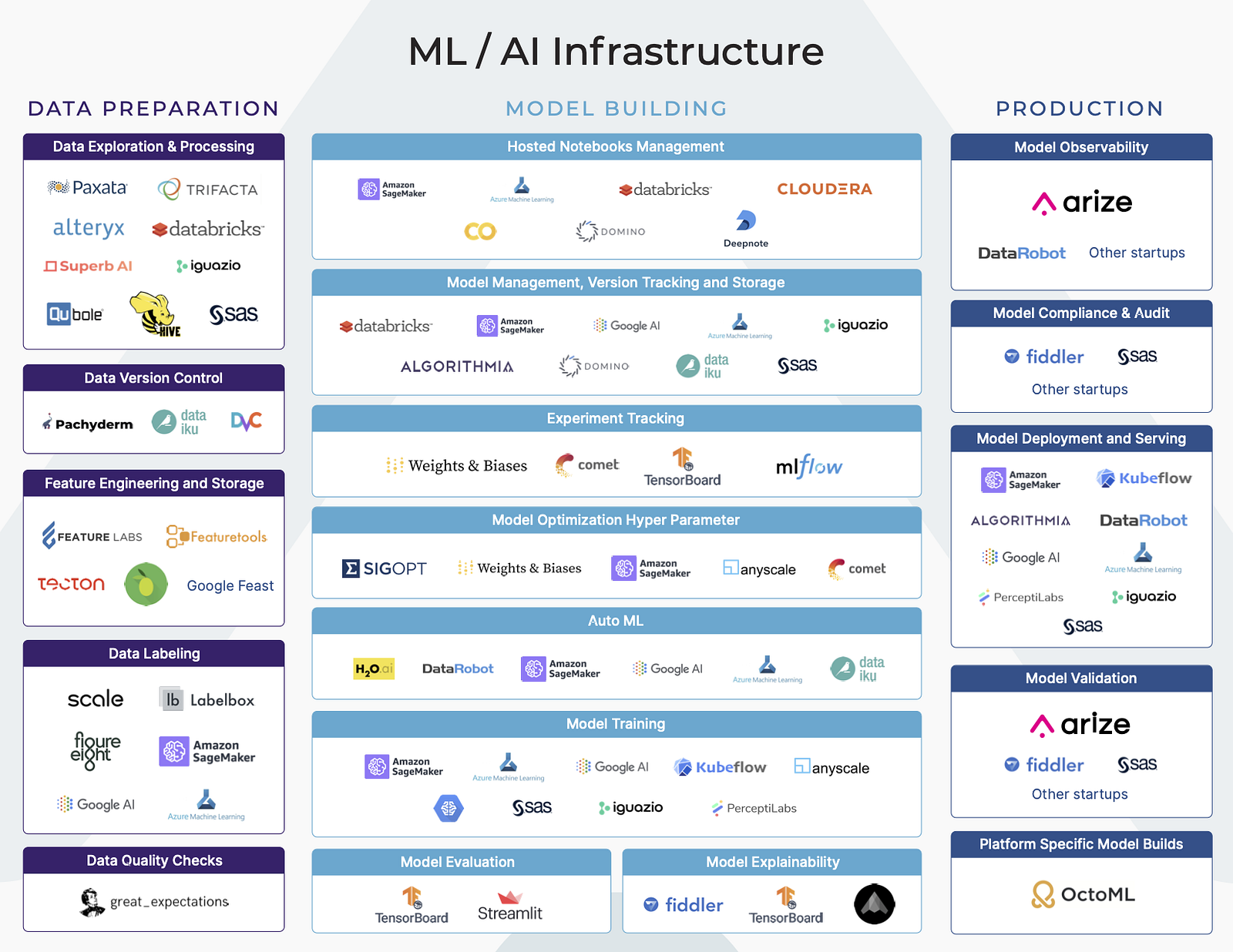
Machine Learning (ML) is being adopted by businesses in almost every industry. Many businesses are looking towards ML Infrastructure platforms to propel their movement of leveraging AI in their business. Understanding the various platforms and offerings can be a challenge. The ML Infrastructure space is crowded, confusing, and complex. There are a number of platforms and tools spanning a variety of functions across the model building workflow.
To understand the ecosystem, we broadly segment the machine learning workflow into three stages — data preparation, model building, and production. Understanding what the goals and challenges of each stage of the workflow can help make an informed decision on what ML Infrastructure platforms out there are best suited for your business’ needs.
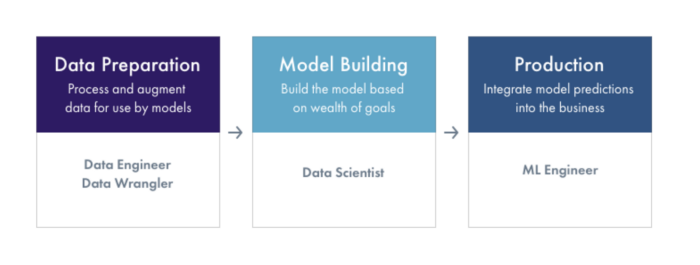
Each of these stages of the Machine Learning workflow (Data Preparation, Model Building and Production) have a number of vertical functions. Some platforms cover functions across the ML workflow, while other platforms focus on single functions (ex: experiment tracking or hyperparameter tuning).
In our last posts, we dived in deeper into the Data Prep and Model Building parts of the ML workflow. In this post, we will dive deeper into Production.
What is Production?
Launching a model into production can feel like crossing the finish line after a marathon. In most real-world environments, it can take a long time to get the data ready, model trained, and finally done with the research process. Then there’s the arduous process of putting the model into production which can involve complex deployment pipelines and serving infrastructures. The final stage of standing a model up in production involves checking the model is ready for production, packaging the model for deployment, deploying the model to a serving environment and monitoring the model & data in production.
The production environment is by far, the most important, and surprisingly, least discussed part of the Model Lifecycle. This is where the model touches the business. It’s where the decisions the model makes actually improve outcomes or cause issues for customers. Training environments, where data scientists spend most of their time and thought, consist of just a sample of what the model will see in the real world.
Research to Production
One unique challenge in the operationalizing of Machine Learning is the movement from a research environment to a true production engineering environment. A Jupyter Notebook, the most common home of model development, is ostensibly a research environment. In a well controlled software development environment an engineer has version control, test coverage analysis, integration testing, tests that run at code check-ins, code reviews, and reproducibility. While there are many solutions trying to bring pieces of the software engineering workflow to Jupyter notebooks, these notebooks are first and foremost a research environment designed for rapid and flexible experimentation. This coupled with the fact that not all data scientists are software engineers by training, but have backgrounds that span many fields such as chemical engineering, physicists, and statisticians — you have what is one of the core problems in production ML:
The core challenge in Production ML is uplifting a model from a research environment to a software engineering environment while still delivering the results of research.
In this blog post, we will highlight core areas that are needed to uplift research into production with consistency, reproducibility, and observability that we expect of software engineering.
Model Validation
Note: Model validation is NOT to be confused with the validation data set.
Quick Recap on Datasets: Models are built and evaluated using multiple datasets. The training data set is used to fit the parameters of the model. The validation data set is used to evaluate the model while tuning hyperparameters. The test set is used to evaluate the unbiased performance of the final model by presenting a dataset that wasn’t used to tune hyperparameters or used in any way in training.
What is Model Validation?
You’re a data scientist and you’ve built a well-performing model on your test set that addresses your business goals. Now, how do you validate that your model will work in a production environment?
Model validation is critical to delivering models that work in production. Models are not linear code. They are built from historical training data and deployed in complex systems that rely on real-time input data. The goal of model validation is to test model assumptions and demonstrate how well a model is likely to work under a large set of different environments. These model validation results should be saved and referenced to compare model performance when deployed in production environments.
Models can be deployed to production environments in a variety of different ways, there are a number of places where translation from research to production can introduce errors. In some cases, migrating a model from research to production can literally involve translating a Python based Jupyter notebook to Java production code. While we will cover in depth on model storage, deployment and serving in the next section, it is important to note that some operationalization approaches insert additional risk that research results do not match production results. Platforms such as Algorithmia, SageMaker, Databricks and Anyscale are building platforms that are trying to allow research code to directly move to production without rewriting code.
In the Software Development Lifecycle, unit testing, integration testing, benchmarking, build checks,etc help ensure that the software is considered with different inputs and validated before deploying into production. In the Model Development Lifecycle, model validation is a set of common & reproducible tests that are run prior to the model going into production.
Current State of Model Validation in Industry
Model validation is varied across machine learning teams in the industry today. In less regulated use cases/industries or less mature data science organizations, the model validation process involves just the data scientist who built the model. The data scientist might submit a code review for their model built on a Jupyter notebook to the broader team. Another data scientist on the team might catch any modelling issues. Additionally model testing might consist of a very simple set of hold out tests that are part of the model development process.
More mature machine learning teams have built out a wealth of tests that run both at code check-in and prior to model deployment. These tests might include feature checks, data quality checks, model performance by slice, model stress tests and backtesting. In the case of backtesting, the production ready model is fed prior historical production data, ideally testing the model on a large set of unseen data points.
In regulated industries such as fintech and banking, the validation process can be very involved and can be even longer than the actual model building process. There are separate teams for model risk management focused on assessing the risk of the model and it’s outputs. Model Validation is a separate team whose job it is to break the model. It’s an internal auditing function that is designed to stress and find situations where the model breaks. A parallel to the software engineering world would be the QA team and code review process.
Model Validation Checks
Regardless of the industry, there are certain checks to do prior to deploying the model in production. These checks include (but are not limited to):
- Model evaluation tests (Accuracy, RMSE, etc…) both overall and by slice
- Prediction distribution checks to compare model output vs previous versions
- Feature distribution checks to compare highly important features to previous tests
- Feature importance analysis to compare changes in features models are using for decisions
- Sensitivity analysis to random & extreme input noise
- Model Stress Testing
- Bias & Discrimination
- Labeling Error and Feature Quality Checks
- Data Leakage Checks (includes Time Travel)
- Over-fitting & Under-fitting Checks
- Backtesting on historical data to compare and benchmark performance
- Feature pipeline tests that ensure no feature broke between research and production
ML Infrastructure tools that are focused on model validation provide an ability to perform these checks or analyze data from checks — in a repeatable, and reproducible fashion. They enable an organization to reduce the time to operationalize their models and deliver models with the same confidence they deliver software.
Example ML Infrastructure Platforms that enable Model Validation: Arize AI, SAS (finance), Other Startups
Model Compliance and Audit
In the most regulated industries, there can be an additional compliance and audit stage where models are reviewed by internal auditors or even external auditors. ML Infrastructure tools that are focused on compliance and audit teams often focus on maintaining a model inventory, model approval and documentation surrounding the model. They work with model governance to enforce policies on who has access to what models, what tier of validation a model has to go through, and aligning incentives across the organization.
Example ML Infrastructure: SAS Model Validation Solutions
Continuous Delivery
In organizations that are setup for continuous delivery and continuous integration, a subset of the validation checks above are run when:
- Code is checked in — Continuous Integration
- A new model is ready for production -Continuous Delivery
The continuous integration tests can be run as code is checked in and are typically structured more as unit tests. A larger set of validation tests that are broader and may include backtesting are typically run when the model is ready for production. The continuous delivery validation of a model becomes even more important as teams are trying to continually retrain or auto-retrain based on model drift metrics.
A number of tools such as ML Flow enable the model management workflow that integrates with CI/CD tests and records artifacts.These tools integrate into Github to enable pulling/storing the correct model and storing results initiated by GitHub actions.
Example ML Infrastructure Platforms that Enable Continuous Delivery: Databricks, ML Flow, CML
Up Next
There are so many under discussed and extremely important topics on operationalizing AI that we will be diving into!Up next, we will be continuing deeper into Production ML and discuss model deployment, model serving, and model observability.
Contact Us
If this blog post caught your attention and you’re eager to learn more, follow us on Twitter and Medium! If you’d like to hear more about what we’re doing at Arize AI, reach out to us at contacts@arize.com. If you’re interested in joining a fun, rockstar engineering crew to help make models successful in production, reach out to us at jobs@arize.com!