


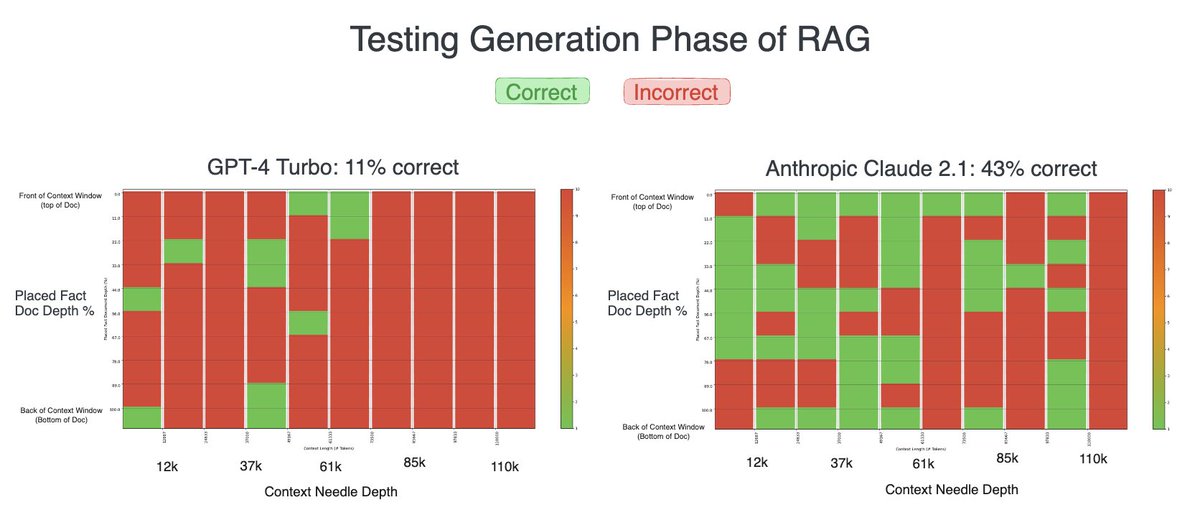
In retrieval-augmented generation (RAG), retrieval often steals the spotlight, while the generation stage receives less attention. To address this gap, we conducted a series of tests to see how different models handle the generation phase, and the results surprised us: Anthropic’s Claude outperformed OpenAI’s GPT-4 in generating responses. This outcome was unexpected, as GPT-4 usually has a strong lead in our evaluations. Interestingly, Claude’s verbose responses might have given it an edge in producing accurate outputs.
How Verbose Generation Boosted Performance

In our tests, Claude provided more detailed explanations before generating answers. This verbosity seemed to support accuracy, as the model “thought out loud” to reach conclusions. Inspired by this, we added a simple prompt modification for GPT-4: “Please explain yourself, then answer the question.” With this tweak, GPT-4’s accuracy improved dramatically, resulting in perfect responses. This raises a key question: Is verbosity a feature or a flaw?
Verbose responses may enable models to reinforce correct answers in their internal mechanisms by generating context that enhances understanding. Claude’s loquacious approach, much like a “talkative uncle,” actually helped in grounding responses through explicit reasoning.
Test Design: Examining Model Responses Across Tasks

Our tests covered various generation challenges beyond straightforward fact retrieval. Here’s an outline of the tasks and how each model performed:
- Simple String Concatenation: All models excelled, confirming that string manipulation is a strong suit.
- Money Formatting and Rounding: With the “explain yourself” prompt, GPT-4 showed marked improvements in accuracy within small context windows, though it encountered minor rounding errors in larger windows.
- Modulo Calculations and Percentage Changes: These required more complex operations, and results varied with context size, but LLMs generally performed well with these structured prompts.
Across these cases, the “explain your answer” approach reduced small errors, especially as the complexity of the generation task increased.
Implications for Model Evaluation: Are We Comparing Apples to Apples?
This experiment brings new insights into evaluating LLMs. Comparing a model like Claude, which favors detailed explanations, with a more concise model like GPT-4 may not be straightforward. Lengthier, explanation-rich responses could give models an edge by reinforcing correct answers. Going forward, measuring the average length of responses in evaluations could offer a clearer picture of how verbosity affects model accuracy and user experience.
The Role of Generation in RAG Applications
The generation stage of RAG is critical for production use cases that go beyond simple retrieval. Common real-world applications involve synthesizing data to produce meaningful responses, such as calculating revenue growth or formatting data in user-friendly ways. For instance, businesses may retrieve revenue data and generate a summarized report that highlights percentage growth—tasks that require a mix of retrieval and dynamic synthesis.
Testing and Results Summary

In addition to string manipulation, formatting, and arithmetic, we conducted specific synthesis tests, modifying our usual retrieval processes to assess:
- String Concatenation: Consistently strong performance across models.
- Dollar Formatting and Rounding: GPT-4’s accuracy improved with explanatory prompts, while rounding errors were minimal.
- Modulo Operations: More complex but within the grasp of both GPT-4 and Claude when prompts were structured effectively.
The LLMs generally excelled within shorter context windows, though small mistakes increased with context length.
Key Takeaways
- Verbose Responses Enhance Accuracy: Models like Claude may benefit from verbose explanations, reinforcing correct answers.
- Prompt Design Matters: Simple prompt modifications, such as asking GPT-4 to “explain yourself,” can significantly improve response accuracy.
- Generation is Crucial for RAG: For applications that synthesize data, model evaluations should consider generation accuracy alongside retrieval.
Our tests, run with Arize Phoenix, illustrate that generation is a vital stage in RAG workflows, especially for tasks requiring synthesis. For more on evaluating LLMs, check out our detailed guide here