






This piece is co-authored by Ilya Reznik (Medium; Contact)
Introduction
While technology makes it very easy to share information, it also makes it easy to share all sorts of information in unintended ways. Case in point: personally identifying information (PII) can surface in software systems in unexpected ways. Whether it is logging or storing data for further training, ML systems have a lot of room for this issue to come up.
People ask us over and over again on what is the best way to be respectful to customer privacy by identifying and removing PII automatically, so we decided to write this article to share how we were able to do it with some customers recently.
Enter Microsoft Presidio
Presidio is a Microsoft open source project released in 2018 aiming to ensure the proper management and governance of sensitive data.
Under the hood, Presidio has many mechanisms to identify PII. Entity Recognition, regular expressions, rule-based logic, and checksum with relevant context in multiple languages. Still not enough for you? The framework also provides options for connecting to external PII detection models.
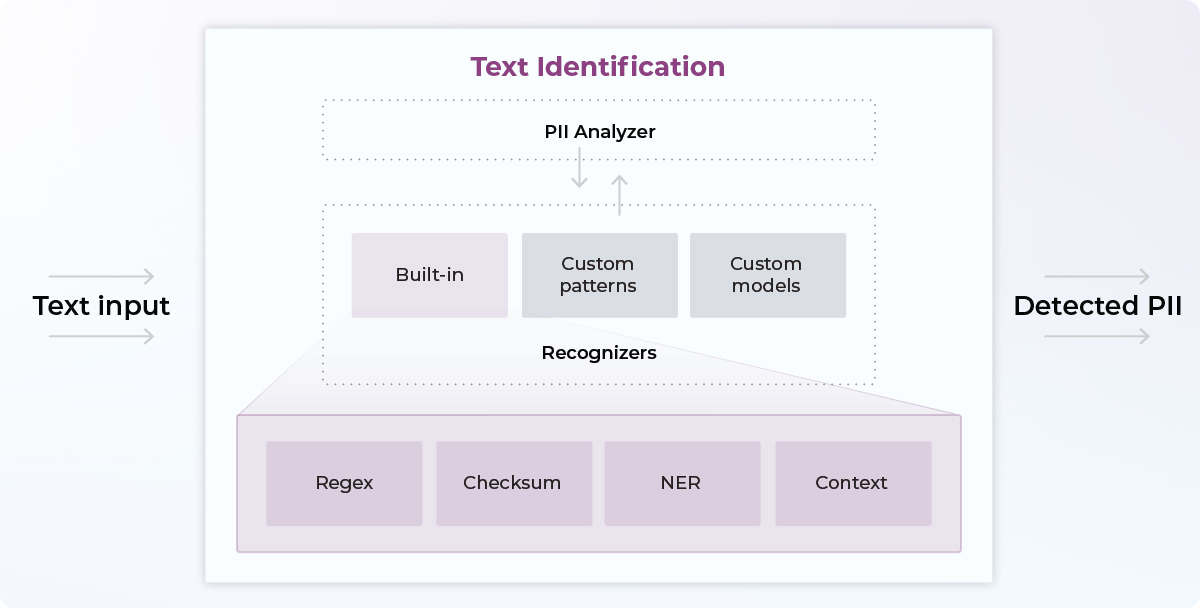
Two of the main components are ‘AnalyzerEngine’ and ‘AnonymizerEngine’.
- AnalyzerEngine scans the text and identifies PII like names, email addresses, phone numbers, etc. The component has support for multiple languages. It can also be customized further with custom code.
- AnonymizerEngine replaces already-identified PII with “anonymized values.” For example it will replace (555) 555-5555 with [Phone]. These replacement values can obviously be customized.
How To Anonymize Conversations In a Chatbot System
Here is then how we used those components to help our customers anonymize their conversations in a chatbot system.
First import necessary dependencies and initialize the analyzer and anonymizer:
from presidio_analyzer import AnalyzerEngine
from presidio_anonymizer import AnonymizerEngine
analyzer = AnalyzerEngine()
anonymizer = AnonymizerEngine()Then we create a function that both finds the important PII and redacts it. In this case we are looking for phone number, email address, and name:
def anonymize_text(text, _analyzer, _anonymizer):
results = _analyzer.analyze(
text=text,
entities=["PHONE_NUMBER", "EMAIL_ADDRESS", "PERSON"],
language='en'
)
anonymized_text = _anonymizer.anonymize(
text=text,
analyzer_results=results
)
return anonymized_text.textAll that’s left to do is to run that function on each row of our pandas dataframe and create a new column with anonymized data:
convo_to_eval_sample['anonymized_convo'] = convo_to_eval_sample['conversation'].apply(
lambda text: anonymize_text(text, analyzer, anonymizer)
)Conclusion
We find Presidio to be a well-designed framework that significantly reduces the burdens of PII removal. As we are seeing more NLP use cases requiring customer inputs of raw text, the need to proactively remove the PII is becoming more pronounced in ML applications. We recommend this approach as an easy starting point for anyone facing the same problem.