





Feast and Arize Supercharge Feature Management and Model Monitoring for MLOps

Aparna Dhinakaran
Co-founder & Chief Product Officer
Arize AI and Feast partner to enhance the ML model lifecycle. Empower online/offline feature transformation and serving through Feast’s feature store and detect and resolve data inconsistencies through Arize’s ML observability platform.
Check out our example Feast/Arize integration tutorial for an interactive demo!
Arize and Feast are aimed at different parts of the machine learning (ML) lifecycle. Feast is an open-source feature store — a data system for transforming, managing and serving machine learning features to models in production. Arize is a comprehensive observability platform to monitor and visualize model performance, understand drift and data quality issues, and share insights for continuous improvement as an evaluation (or inference) store.
In this blog post, we will introduce Arize AI and Feast, showcase how they work together as part of your modern ML stack, and demonstrate how they enable better feature management, feature consistency, model monitoring, and ML observability in an end-to-end ML model lifecycle.
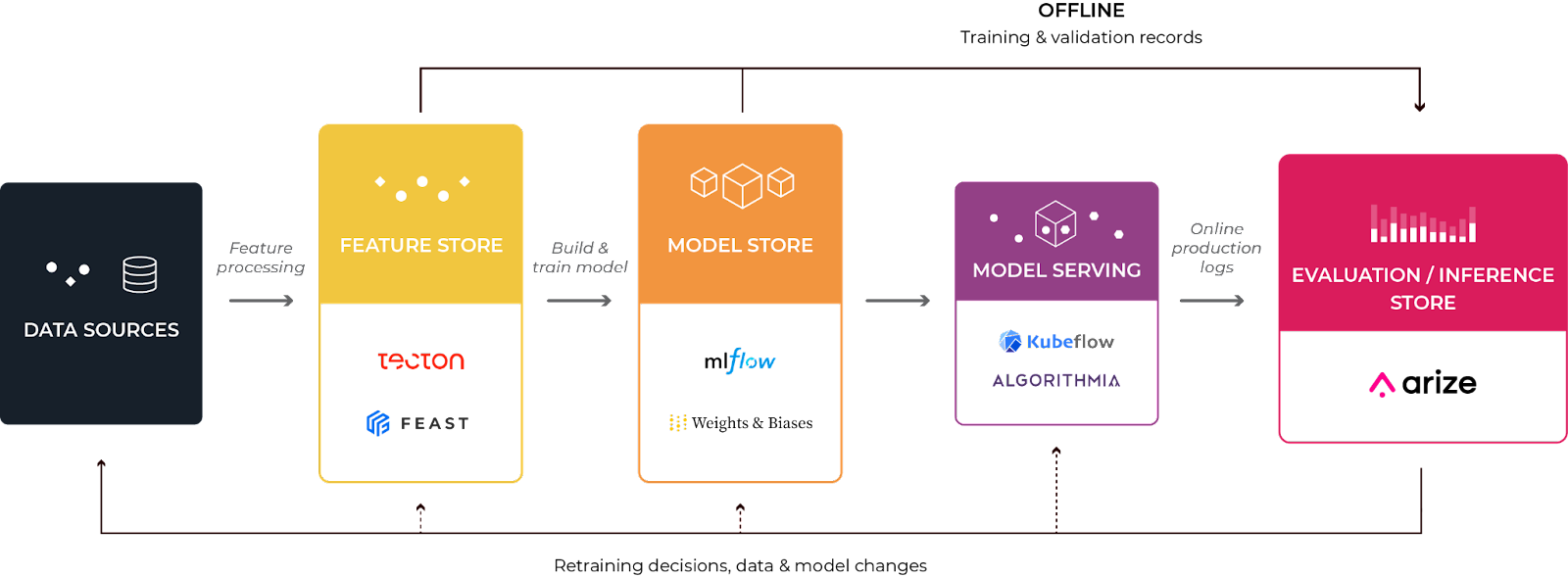
The Emerging Canonical ML Stack
At a rapid pace, ML teams are investing in moving ML projects from falling off at proof of concepts to powering crucial pieces of technology that people rely on daily. This trend, which tackles the operational aspects of productionalizing machine learning, is widely known as MLOps. Getting machine learning to work in production is not the same as getting it to work in notebooks. The challenge of deploying machine learning to production for operational purposes (e.g. recommender systems, fraud detection, personalization, etc.) introduces new requirements for our data tools. In this process, many teams have found themselves realizing that a different toolchain is needed for machine learning, just as there is a toolchain for software.
The truth is that we are still in the early innings of defining what the right tooling suite will look like for building, deploying, and iterating on machine learning models. However, we are beginning to see a standardization of the ML stack as more teams are adopting feature stores, model stores, and ML observability solutions. As this stack matures, similar to what happened in the software toolchain, deeper integrations across platforms will occur. Today, we’ll dive into one such integration between the leading feature store — Feast, from Tecton — and the leading ML observability solution, Arize.
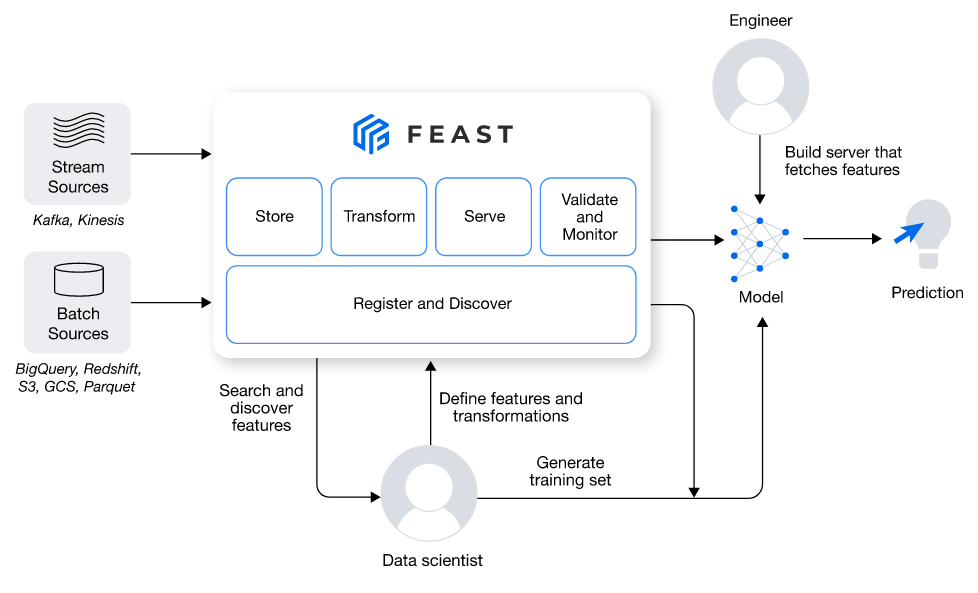
What is Feast?
Transforming data into actionable features for an ML algorithm is complex and time-consuming. It requires transforming historical data and serving it for model training, as well as transforming fresh data and serving it online, at low latency, to support real-time predictions. Having more than one unified set of features for data retrieval across offline training and online serving can lead to data inconsistencies and model training-serving skew.
Feature stores empower data scientists to curate their feature data, serve it for training and online inference, and reuse and share features across teams and projects to recover countless hours of development time. Feast introduces feature reuse through a centralized registry, enabling multiple teams to contribute, reuse, and recycle features. Feast also provides a data access layer to abstract feature storage from feature retrieval. This provides a consistent means of referencing feature data, ensuring models remain stable across training and serving.
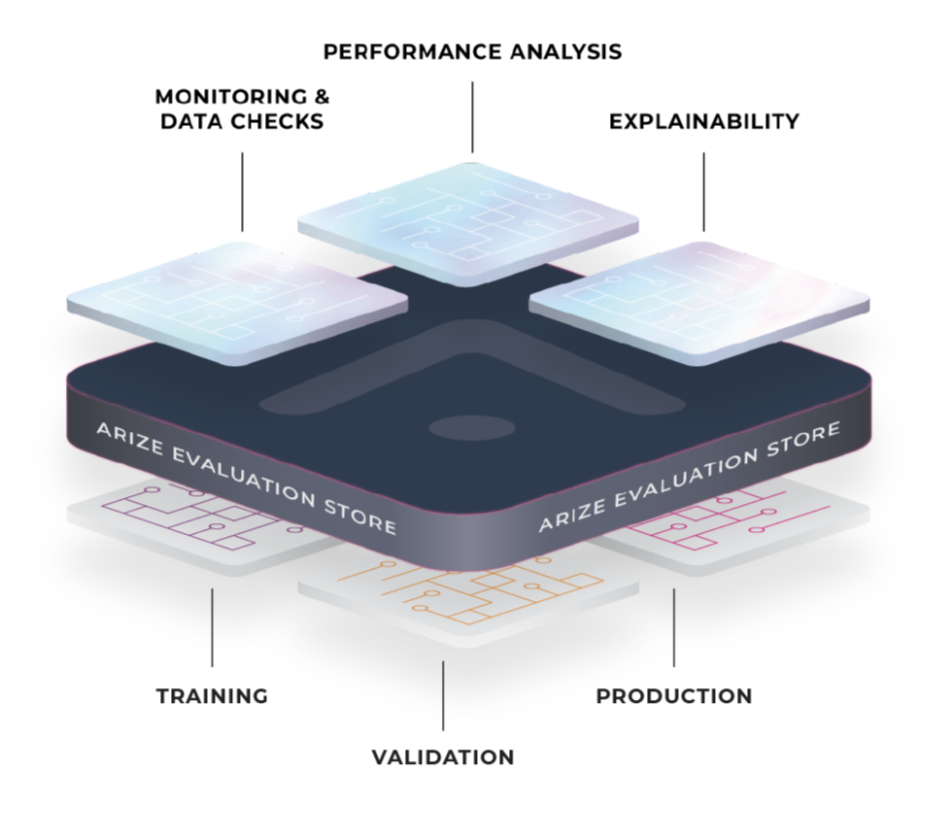
What is Arize?
Countless development hours are spent producing ML models that intend to increase revenue, cut costs, and improve user experience. However, once the model is finally deployed into production, most companies lack the right tools and infrastructure to adequately monitor model performance and data quality issues.
ML Observability platforms empower ML engineers and data scientists to validate performance pre-deployment and continuously monitor model performance and data into production. Arize provides a scalable and flexible evaluation store to harness, through intelligent indexing, inferences and ground truth data across model versions and environments (training, validation, production). This allows for an analytics platform equipped to surface model performance metrics, and combinations of features and values for monitoring, troubleshooting, and resolving issues in production. Arize also supports fully customizable performance dashboards for A/B testing model versions, comparing offline and online datasets, and narrowing in on specific cohorts of predictions in a dynamic interface.
Complexities of ML-Based Systems
In traditional software systems, ensuring code and infrastructure health is critical to the technical success of the software application. As pointed out in the widely read ML Test Score paper from Google, code isn’t the only important component to ensure success of ML-based systems, the model and data must also be monitored.
Machine learning models operate on data and their performance correlates to data quality and how closely the data they use to make predictions resembles the data they were initially trained on. Before launch, there must be data tests to validate the quality of data used to build the model. Post launch, there must be ongoing data quality and drift monitoring. Being able to detect bad data —empty/null/missing values, type mismatches, and changes in cardinality —is key to maintaining your model’s performance.
Because variations to the data a model is exposed to ultimately affects its response, skew tests are an important tool to ensure that the data that the model sees in training is similar to what the model sees in serving. We’ll dive in deeper to how Arize and Feast tackle training-serving skew.
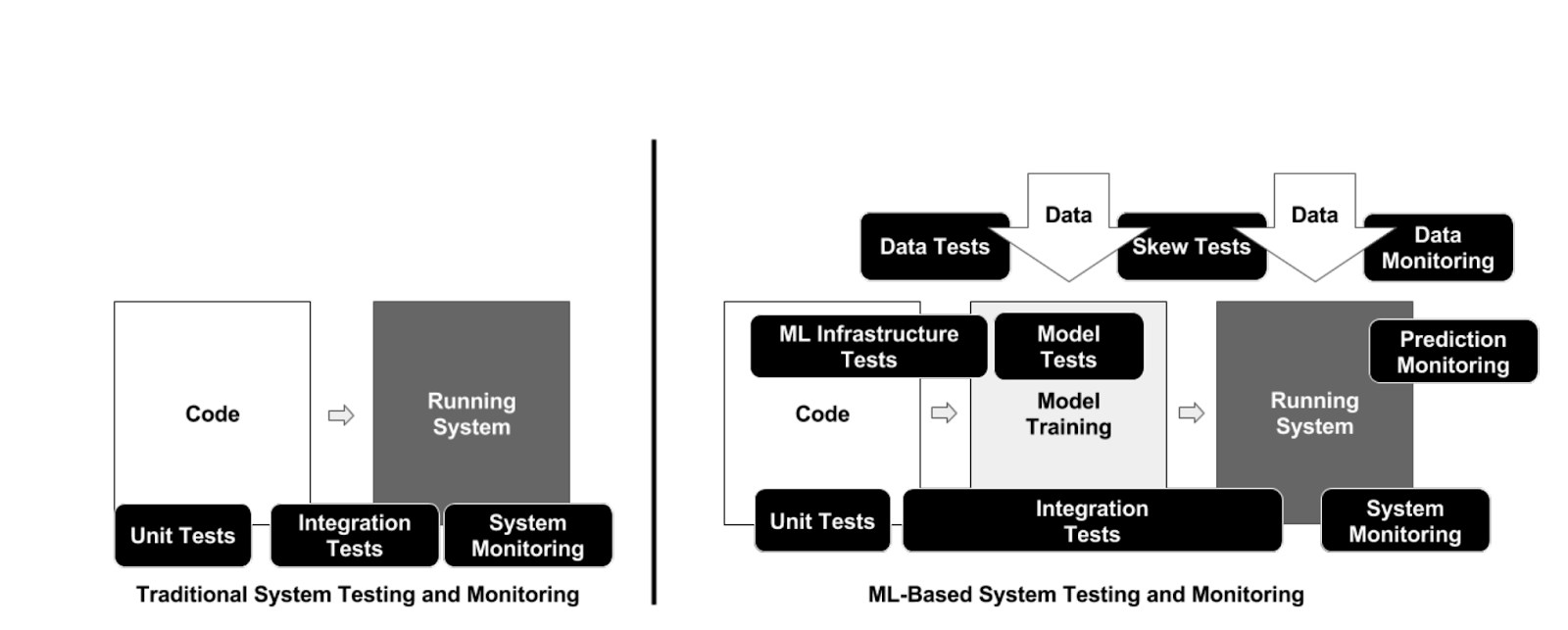
Figure from ML Test Score Paper
Tackling Training/Serving Skew with Arize and Feast
Training-Serving skew is a common pain point faced across teams productionalizing machine learning systems.
What is Training-Serving Skew?
Let’s get the definition from Martin Zinkevich’s Best Practices for ML Engineering:
Training-serving skew is a difference between performance during training and performance during serving. This skew can be caused by:
-
- A discrepancy between how you handle data in the training and serving pipelines.
- A change in the data between when you train and when you serve.
- A feedback loop between your model and your algorithm.
Great machine learning models need great features. Models require a consistent view of features across training and serving, meaning: the definitions of features used to train a model must exactly match the features provided in online serving; and feature transformations done during model training must match transformations applied during serving. When they don’t match, training-serving skew is introduced and can cause catastrophic and hard-to-debug model performance problems.
These data inconsistencies not only manifest in what the model uses for online inference, but are then also used to train the model on incorrect information. Ultimately, this impacts downstream performance of the model.
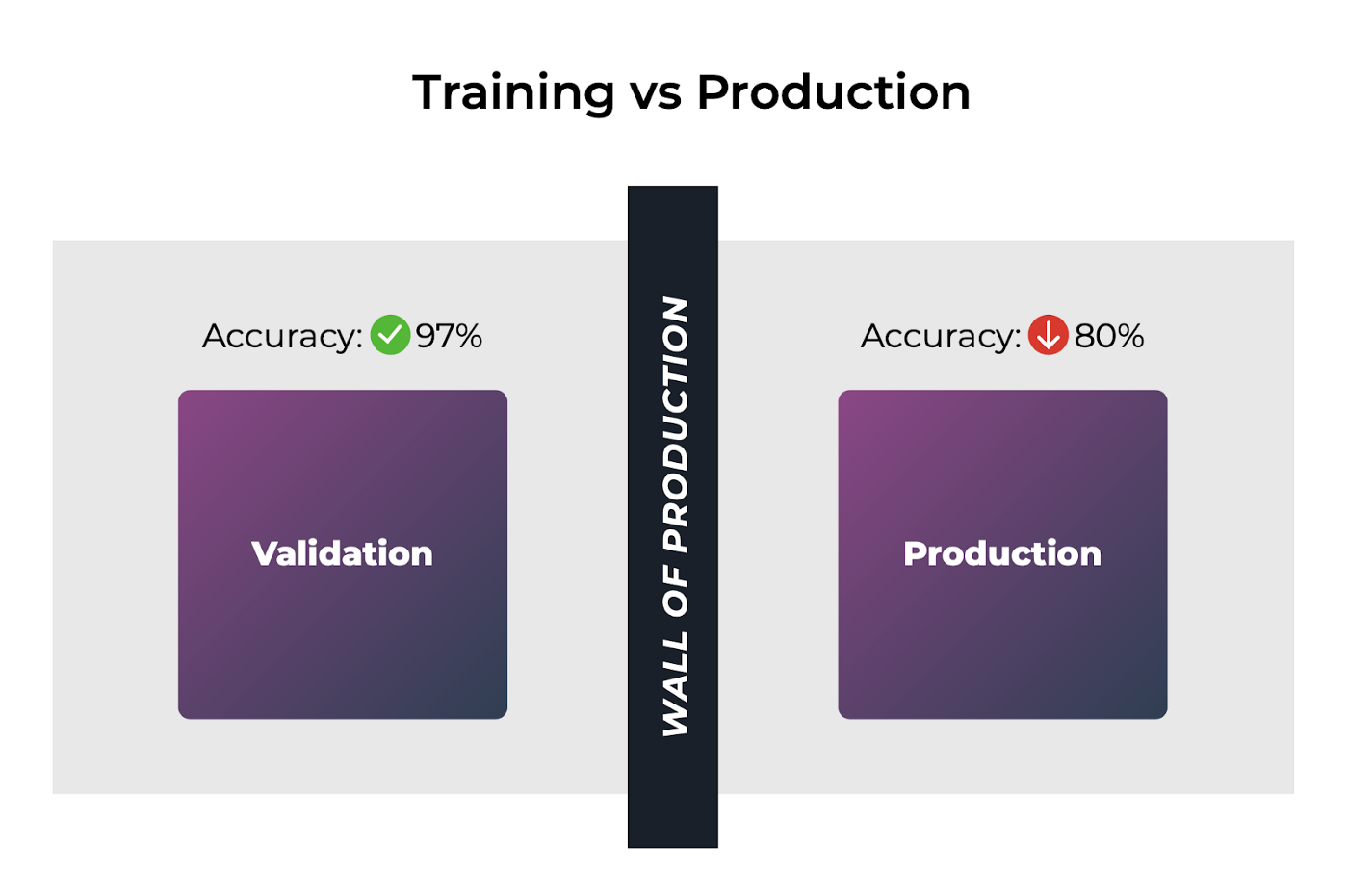
Training-Serving Skew Image by Arize AI
How Arize and Feast Tackle Training-Serving Skew
Feature stores serve as the “the interface between models and data.” Feast abstracts away the logic and processing used to generate a feature, providing users an easy way to access all features in an organization consistently across all environments in which they’re needed. Feast allows you to materialize online features for low-latency model serving and offline features for model training.
Feature stores help you get 80% of the way there, but there are still cases where skew can get introduced. Martin Zinkevich from Best Practices for ML Engineering says that “the best solution is to explicitly monitor it so that system and data changes don’t introduce skew unnoticed.” This is where Arize plugs in to surface these data inconsistencies.
Arize stores the logs of the offline features and the online features into its evaluation store. Online features served in production are joined with the corresponding offline features used for training the model, and they are evaluated for a 1-to-1 match. If there is a significant percentage of mismatched offline and online values, Arize has workflows to surface where the inconsistencies stem from and troubleshoot why they occurred. Check out the example below to see it in action.
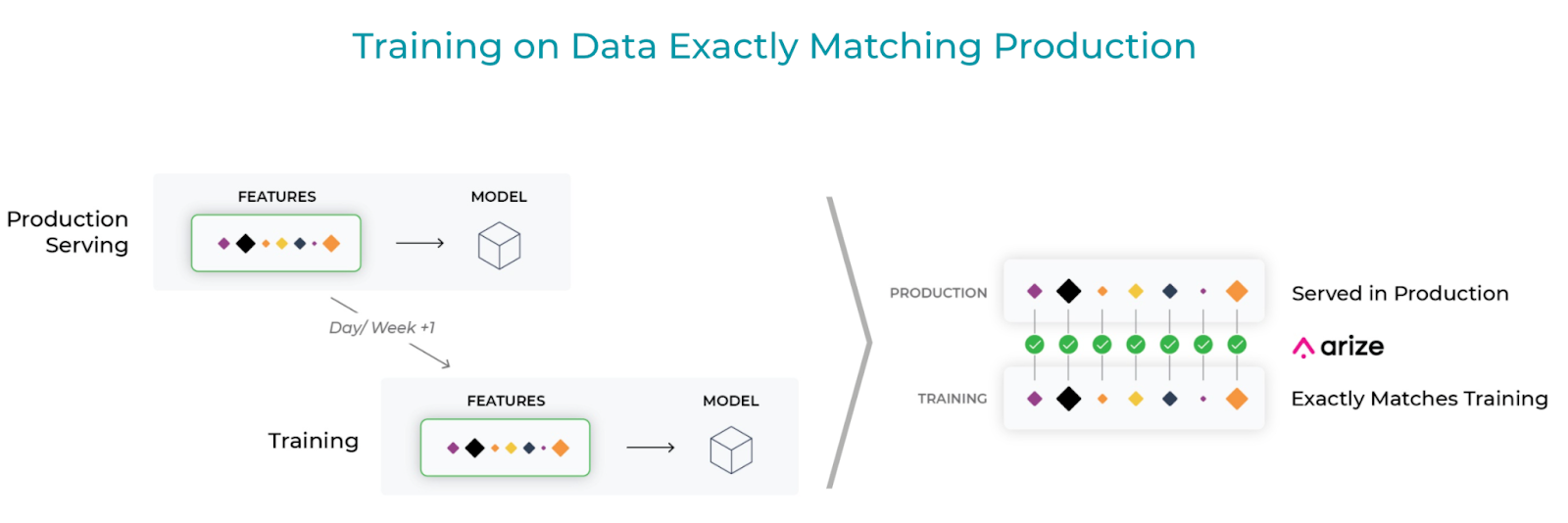
Image by Arize AI
Example Use Case: Fraud Model
Check out our Example Feast/Arize Integration Tutorial for an interactive demo!
To make this concrete, let’s dive into an example. Suppose you are building a transaction fraud model that predicts whether a payment by a customer will succeed. Two of your most important features are current_24_hr_cancels and avg_cancels referring to the most up-to-date information about cancellations occurring across transactions.
In this example, we will show how data inconsistencies can occur based on the arrival of new information. The online features are features served in production, usually “materialized” live in production for low latency. The offline features are features used in retraining models, often retrieved after those features are already served in production.
By using Feast, you are able to quickly deploy a centralized feature repository that serves feature values into production at low latency for your online fraud model. The online feature store is updated daily with offline features which are used to retrain models. However, there is typically a delay between getting the online features and when the data sources from which those features are updated.
For example, there could be a delay in the Parquet data source registering a cancellation for transactions. This delay causes discrepancies between online and offline environments for current_24_hr_cancels and avg_cancels, since these features are computed assuming the logs from our Parquet file are up-to-date.
In this tutorial, we will show how to catch this issue using Feast and Arize together: surfacing up the inconsistencies, their root cause, and what can be done to troubleshoot them.
Arize calculates for each feature what percent of feature values are consistent between offline and online values. The two features current_24hrs_cancels and average_cancels have a significant percentage of inconsistencies. Arize reveals a gradually increasing impact caused by the repeated delay between online feature values being served and the offline datasource, compounded over tens of thousands of data points.
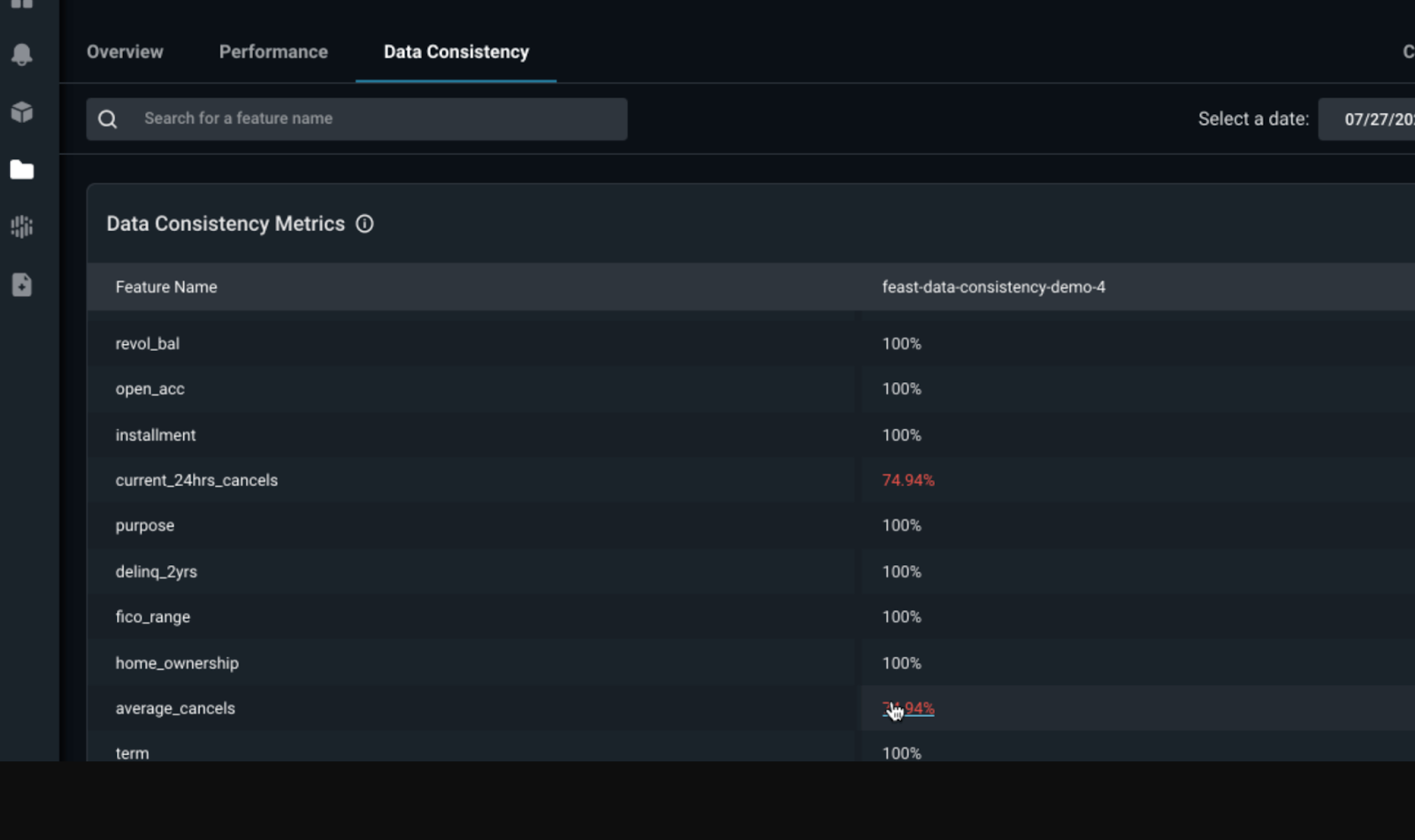
Data Consistency Image by Arize AI
Once these feature inconsistencies are detected, Arize surfaces through interactive distribution comparison and residual error charts where the online feature distribution mismatch with historical offline features occurs.
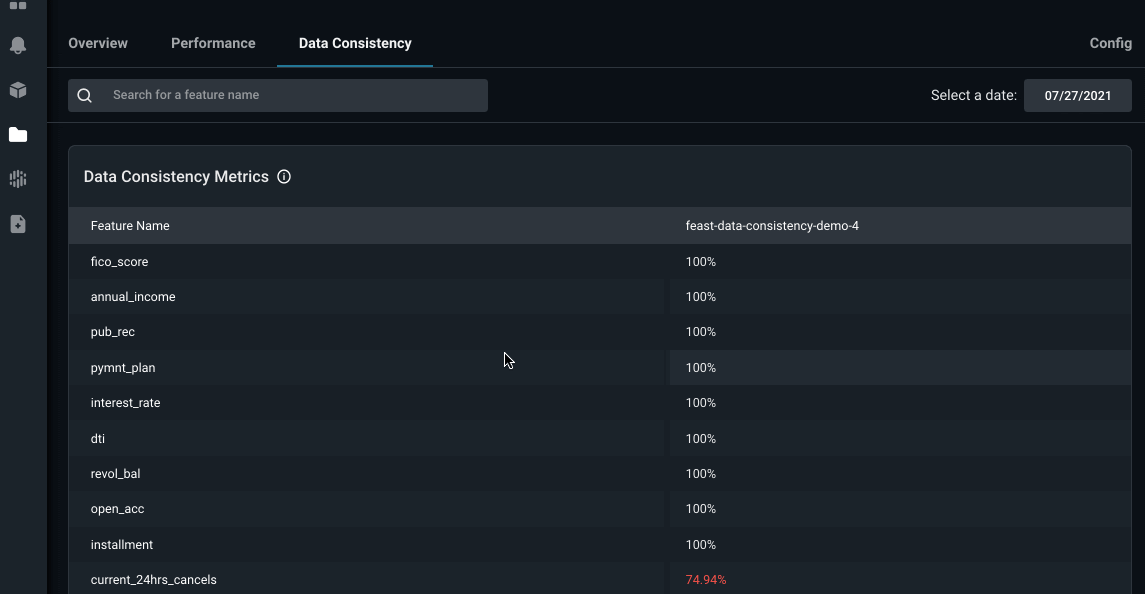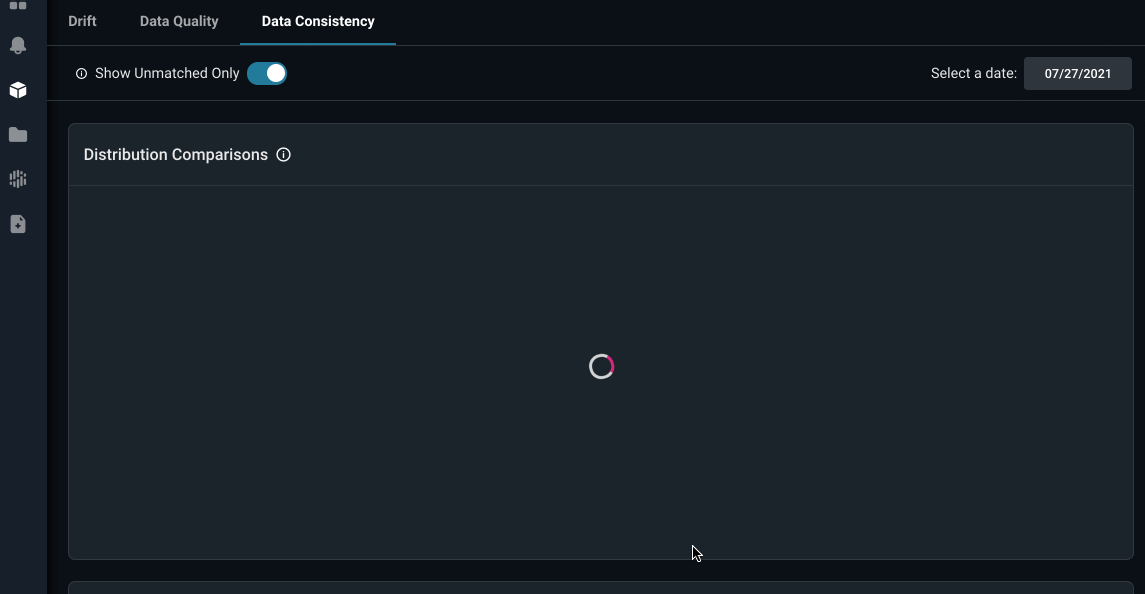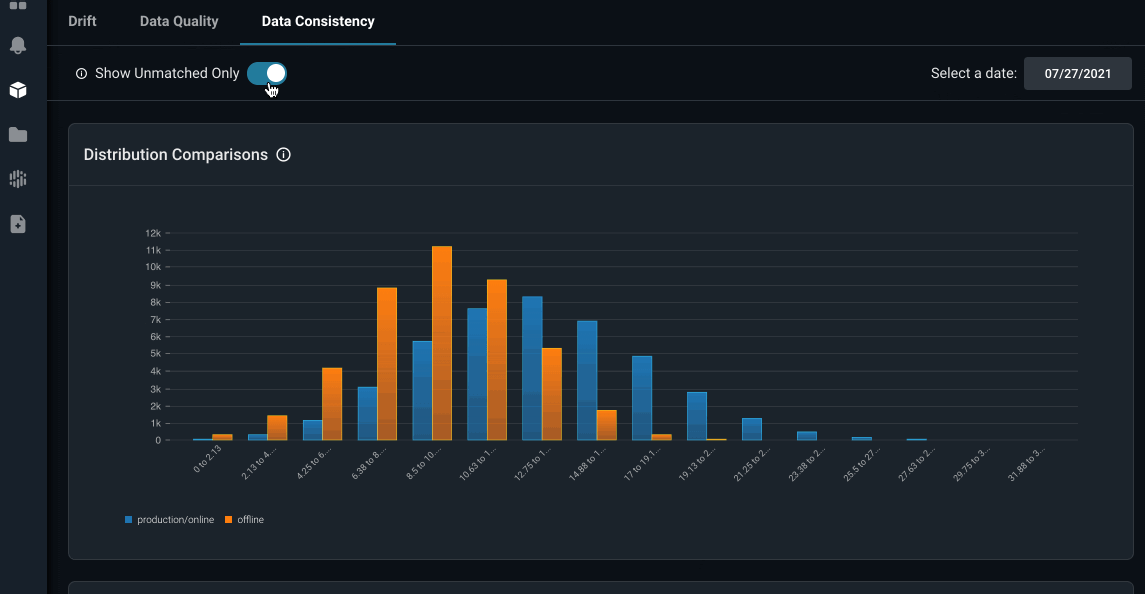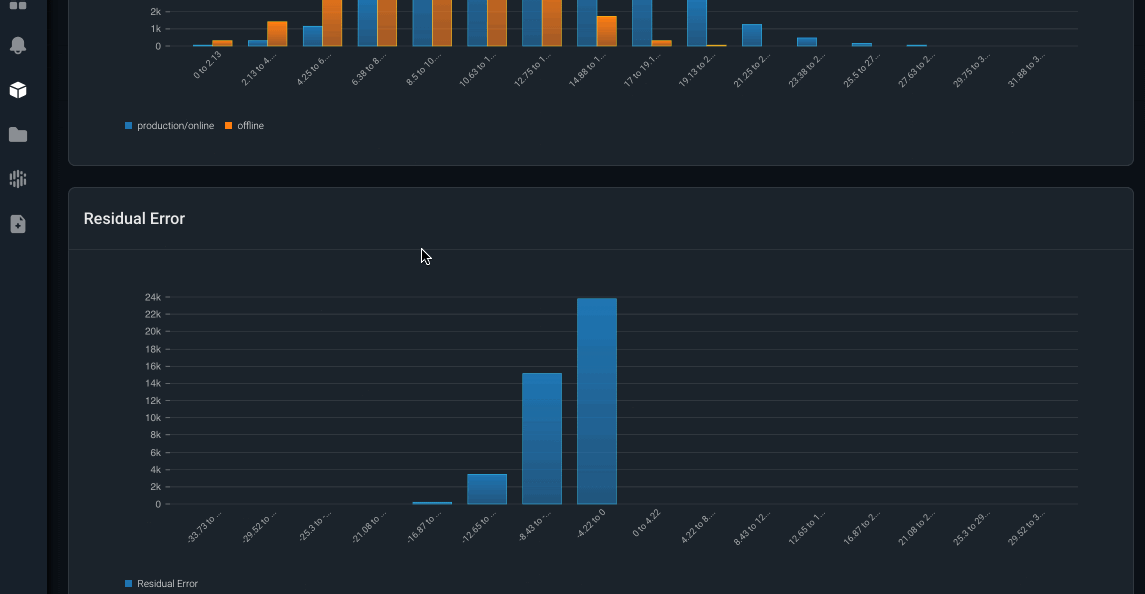
Image by Arize AI: Dashboard of distribution comparisons & residual error
Arize also surfaces a heatmap visualization to detect data inconsistency patterns. In this example, the x-axis is the value of the online feature average_cancels and the y-axis is the offline feature average_cancels. If they were perfectly matched all the time, we would see a diagonal line across this heatmap. However, there are a significant number of matched online-offline feature pairs that are not equal. We can see there is a trend where the online value for average_cancels is higher than the offline value. By surfacing this up, users can narrow down their troubleshooting to focus on what’s causing the increase in average_cancels in the online serving environment compared to the decrease in the offline environment.
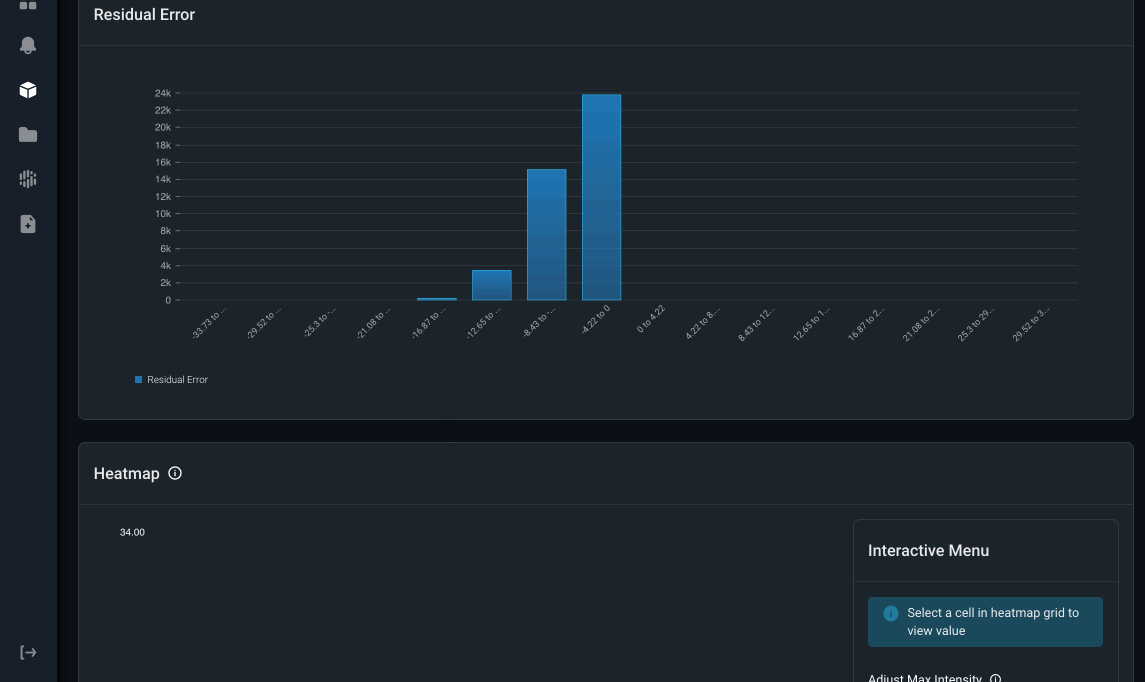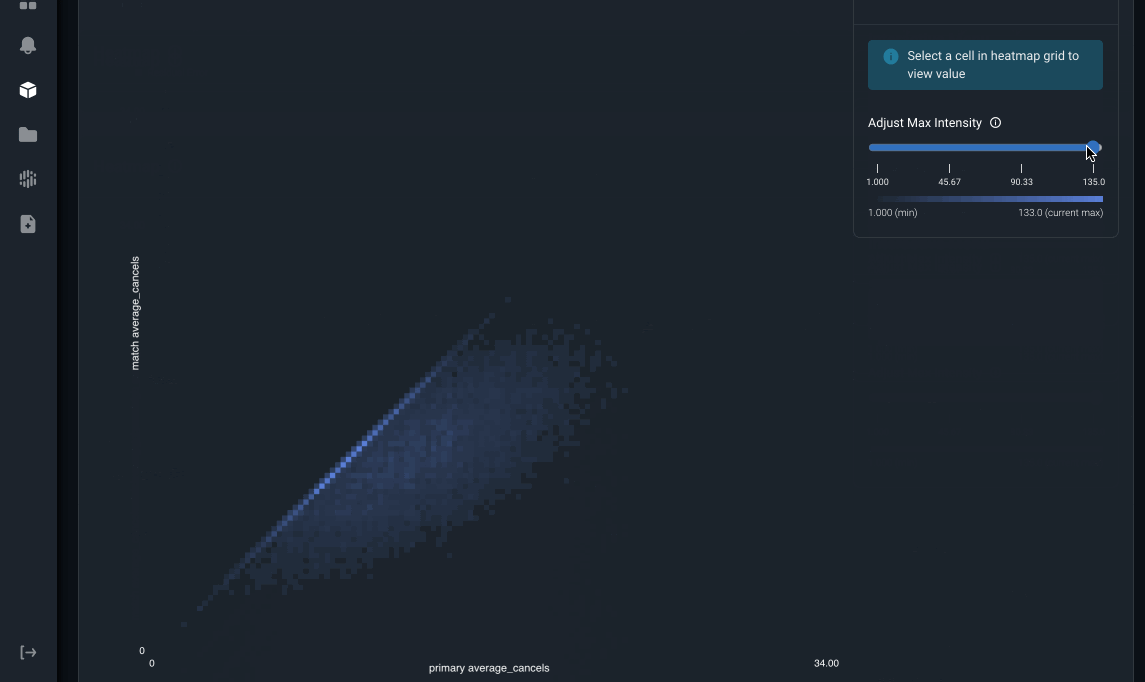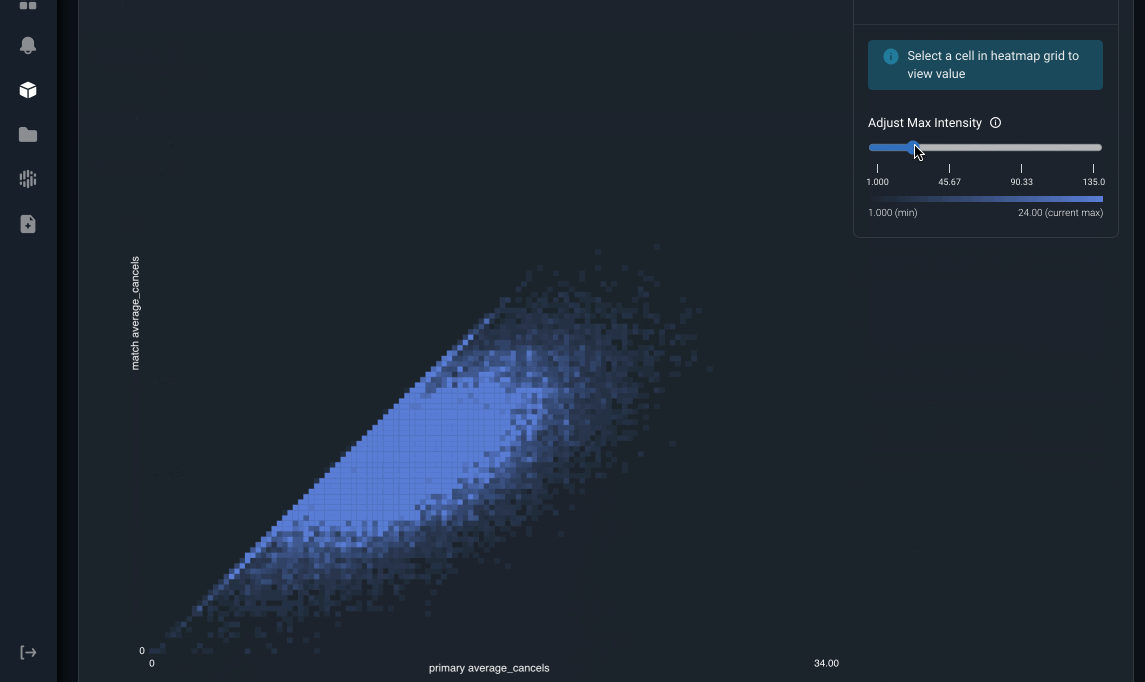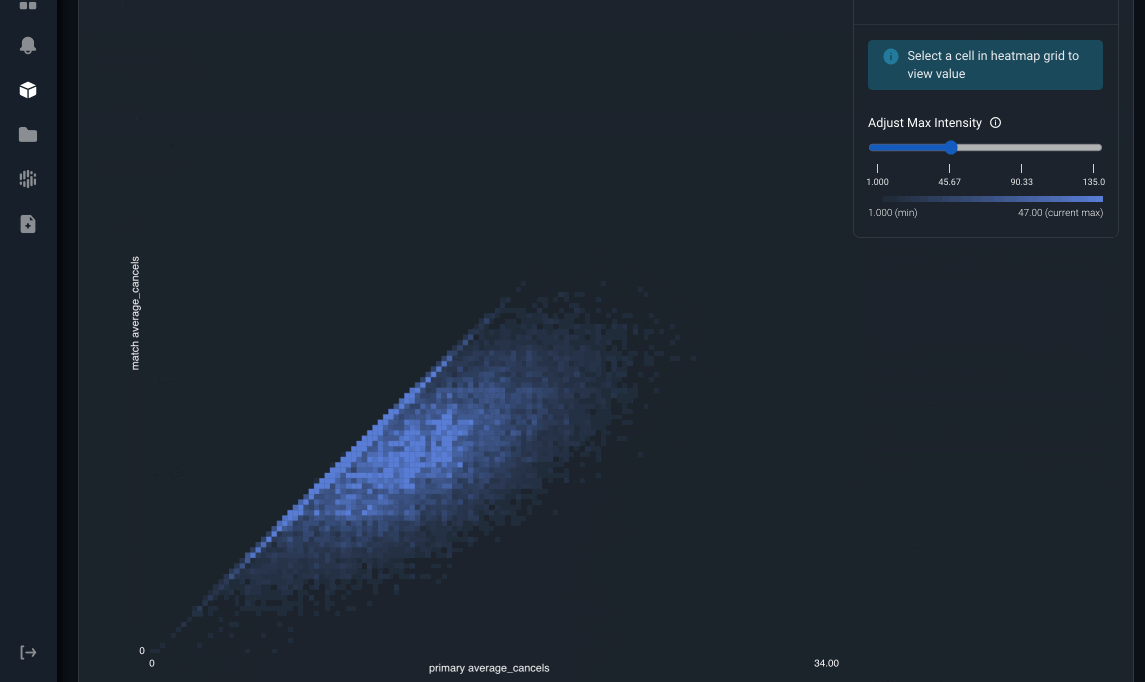
Image by Arize AI: Feature Heatmap
Mitigating online/offline feature inconsistencies through a feature store system and proactively monitoring such data consistency issues by leveraging an evaluation store can be the difference between countless hours of debugging a faulty model and a quick model improvement turnaround time. This ultimately reduces time to tackle training-serving skew for ML models.
Summary
The integration of a feature store and evaluation store as part of your ML development lifecycle can help improve productionization of features, mitigate data inconsistencies, and facilitate troubleshooting to resolve performance degradations.
The Feast feature store will prevent redundant feature implementations and mitigate common data inconsistencies through a central feature registry. Arize AI’s evaluation store provides proactive model monitoring and performance troubleshooting tools to create a tighter feedback loop for continuous model improvement.
For more information and a step-by-step guide on how to integrate Feast and Arize into your fraud detection model use-case, check out our interactive colab.