



Co-authored by Prasad Kona, Lead Partner Solutions Architect at Databricks
Building production-ready AI agents that can reliably handle complex tasks remains one of the biggest challenges in generative AI today. While frameworks make it easier to create sophisticated agents, ensuring they perform reliably in production requires robust observability, evaluation, and deployment infrastructure.
This technical blog demonstrates how Databricks Mosaic AI Agent Framework and Arize AI’s observability platform work together to streamline the entire agent lifecycle. We’ll walk through building a LangGraph tool-calling agent that can execute Python code, adding comprehensive tracing with Arize, evaluating agent quality using LLM-as-a-Judge, and deploying to production with built-in monitoring and alerting. By the end, you’ll have a complete blueprint for creating production ready high-quality agents.
Databricks and Arize form a Powerful Combination
Databricks Mosaic AI Agent Framework is a comprehensive platform for building and deploying AI agents at enterprise scale. It provides:
- Flexible Development: Build sophisticated multi-step agents with state management and tool orchestration in no-code and code options
- Unity Catalog Integration: Leverage existing data assets and functions as agent tools.
- MLflow-based Lifecycle Management: Version, track, and deploy agents with confidence
- Enterprise Security: Built-in authentication, authorization, and secure tool execution
- Scalable Serving: Auto-scaling endpoints with support for streaming responses
Arize AI is the leading observability and evaluation platform for AI applications. Arize AI delivers comprehensive observability tools specifically designed for AI applications. The platform is available in two versions:
- Arize AX: An enterprise solution offering advanced monitoring, evaluation, tracing, and optimization capabilities
- Arize Phoenix: An open-source platform making tracing and evaluation accessible to all developers
For the technical implementation, we will be focusing on Arize AX.
The combination of Databricks Mosaic AI and Arize AI provides three key advantages:
- End-to-End Visibility: Monitor your agent’s complete decision-making process, from receiving user requests to tool execution and final response generation
- Automated Quality Assessment: Apply consistent evaluation methodologies across development and production to measure and understand agent performance
- Data-Driven Optimization: Run structured experiments to compare different agent configurations and identify optimal settings
Technical Implementation Guide
Let’s walk through building a complete AI agent that can execute Python code, with observability and quality evaluation built in with Arize AX. This blog will follow steps outlined in the provided Databricks notebook.
Prerequisites
Before we begin, you’ll need:
- An Arize AX account (sign up free)
- A Databricks workspace with access to Mosaic AI
- Access to Unity Catalog for tool integration
Step 1: Install Dependencies
First, install the necessary libraries for LangGraph, Databricks integration, and Arize tracing:
%pip install -U -qqqq mlflow databricks-langchain databricks-agents langgraph==0.3.4 arize-otel openinference.instrumentation.langchain
dbutils.library.restartPython()
Step 2: Configure Arize Environment Variables
# Reading secure keys from secrets
ARIZE_API_KEY = dbutils.secrets.get(scope="your-scope", key="ARIZE_API_KEY")
ARIZE_SPACE_ID = dbutils.secrets.get(scope="your-scope", key="ARIZE_SPACE_ID")
# Setting as environment variables
import os
os.environ["ARIZE_API_KEY"] = ARIZE_API_KEY
os.environ["ARIZE_SPACE_ID"] = ARIZE_SPACE_ID
Step 3: Define the Agent
Here’s the complete agent code with Arize auto-instrumentation tracing built-in. The agent uses LangGraph for orchestration and includes the Unity Catalog system.ai.python_exec function for code execution:
%%writefile agent.py
from typing import Any, Generator, Optional, Sequence, Union
import mlflow
from databricks_langchain import ChatDatabricks, UCFunctionToolkit
from langchain_core.language_models import LanguageModelLike
from langchain_core.runnables import RunnableConfig, RunnableLambda
from langgraph.graph import END, StateGraph
from mlflow.langchain.chat_agent_langgraph import ChatAgentState, ChatAgentToolNode
from mlflow.pyfunc import ChatAgent
import os
# Arize Tracing Setup
from arize.otel import register
from openinference.instrumentation.langchain import LangChainInstrumentor
model_config = mlflow.models.ModelConfig(development_config="chain_config.yaml")
# Register tracer provider to send traces to Arize
tracer_provider = register(
space_id = os.getenv("ARIZE_SPACE_ID"),
api_key = os.getenv("ARIZE_API_KEY"),
project_name = model_config.get("ARIZE_PROJECT_NAME"),
)
# Auto-instrument LangChain
LangChainInstrumentor().instrument(tracer_provider=tracer_provider)
# Define LLM and tools
LLM_ENDPOINT_NAME = model_config.get("LLM_ENDPOINT_NAME")
llm = ChatDatabricks(endpoint=LLM_ENDPOINT_NAME)
system_prompt = """You are a helpful assistant. Take the user's request and where
applicable, use the appropriate tool if necessary to accomplish the task."""
# Add Unity Catalog tools - including Python code execution
tools = []
uc_tool_names = ["system.ai.python_exec"]
uc_toolkit = UCFunctionToolkit(function_names=uc_tool_names)
tools.extend(uc_toolkit.tools)
# Define the agent logic
def create_tool_calling_agent(
model: LanguageModelLike,
tools: Union[ToolNode, Sequence[BaseTool]],
system_prompt: Optional[str] = None,
) -> CompiledGraph:
model = model.bind_tools(tools)
def should_continue(state: ChatAgentState):
messages = state["messages"]
last_message = messages[-1]
if last_message.get("tool_calls"):
return "continue"
else:
return "end"
# Create workflow
workflow = StateGraph(ChatAgentState)
workflow.add_node("agent", RunnableLambda(call_model))
workflow.add_node("tools", ChatAgentToolNode(tools))
workflow.set_entry_point("agent")
workflow.add_conditional_edges(
"agent",
should_continue,
{"continue": "tools", "end": END}
)
workflow.add_edge("tools", "agent")
return workflow.compile()
# Create and set the agent
agent = create_tool_calling_agent(llm, tools, system_prompt)
AGENT = LangGraphChatAgent(agent)
mlflow.models.set_model(AGENT)
Step 4: Log the agent as an MLflow model
Now we are ready to deploy the model to Databricks serving. Package the agent for deployment with all necessary dependencies and resources:
import mlflow
from agent import tools, LLM_ENDPOINT_NAME
from mlflow.models.resources import DatabricksFunction, DatabricksServingEndpoint
# Configure resources for automatic authentication
resources = [DatabricksServingEndpoint(endpoint_name=LLM_ENDPOINT_NAME)]
for tool in tools:
if isinstance(tool, UnityCatalogTool):
resources.append(DatabricksFunction(function_name=tool.uc_function_name))
# Log the agent
with mlflow.start_run():
logged_agent_info = mlflow.pyfunc.log_model(
artifact_path="agent",
python_model="agent.py",
model_config="chain_config.yaml",
extra_pip_requirements=["arize-otel", "openinference.instrumentation.langchain"],
resources=resources,
)
Step 5: Validate the agent before deployment
mlflow.models.predict(
model_uri=f"runs:/{logged_agent_info.run_id}/agent",
input_data={"messages": [{"role": "user", "content": "Hello!"}]},
env_manager="uv",
)
Step 6: Register the model to Unity Catalog and deploy the agent
# Register to Unity Catalog
mlflow.set_registry_uri("databricks-uc")
UC_MODEL_NAME = f"{catalog}.{schema}.{model_name}"
uc_registered_model_info = mlflow.register_model(
model_uri=logged_agent_info.model_uri, name=UC_MODEL_NAME
)
# Deploy with Arize environment variables
from databricks import agents
agents.deploy(
UC_MODEL_NAME,
uc_registered_model_info.version,
scale_to_zero_enabled=True,
environment_vars={
"ARIZE_API_KEY": "{{secrets/your-scope/ARIZE_API_KEY}}",
"ARIZE_SPACE_ID": "{{secrets/your-scope/ARIZE_SPACE_ID}}",
}
)
Step 7: Configure LLM-as-a-Judge Evaluations in Arize AX
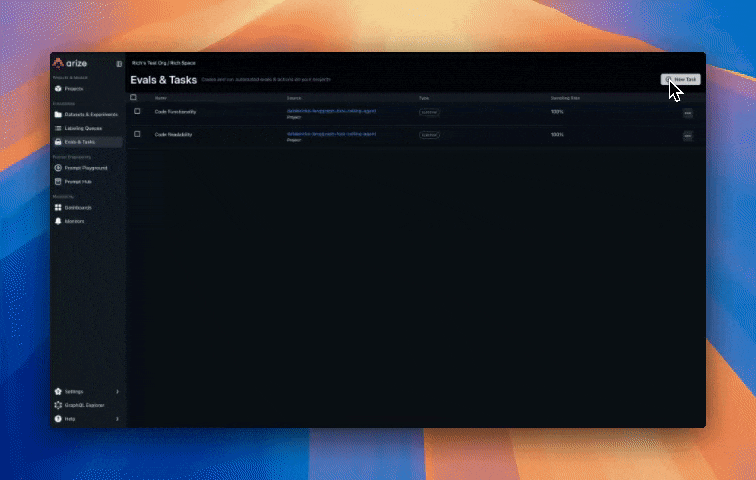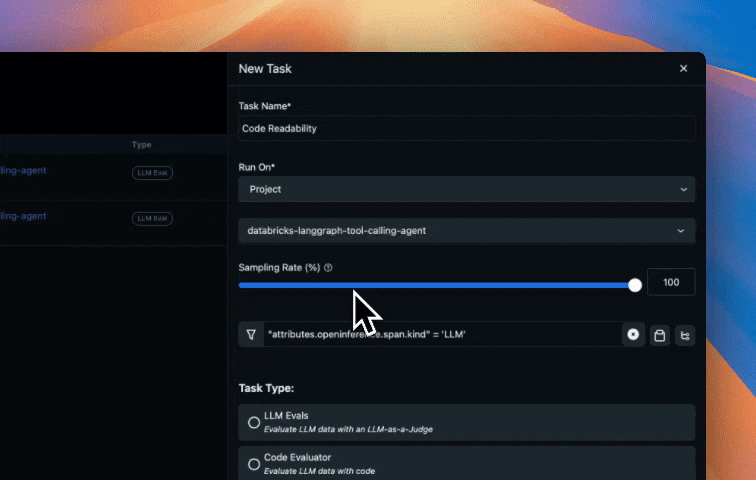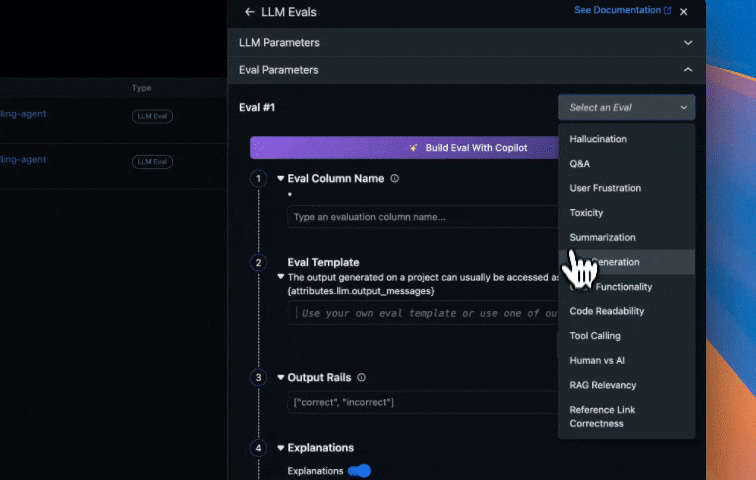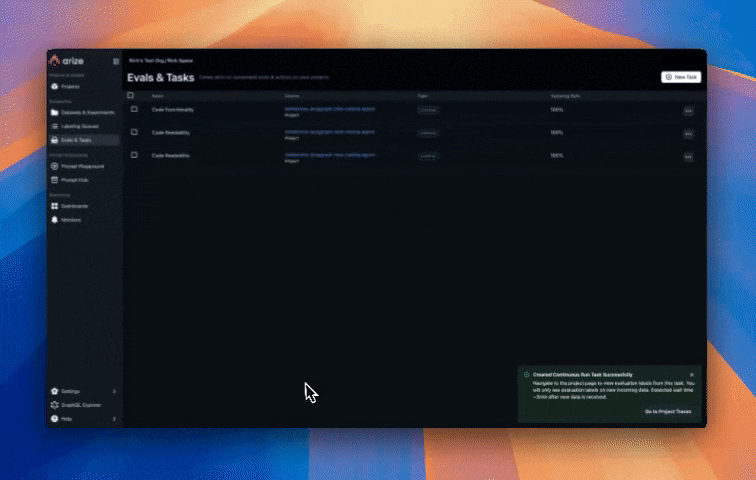
Arize’s online evaluations can be set up in a few clicks to automatically run LLM-as-a-Judge based evaluations directly on the traces collected in the Arize platform from our Agent runs. This provides continuous quality evaluation and monitoring without manual intervention. This approach scales to millions of interactions, enabling data-driven improvements to your agent’s performance. Create evals from prebuilt evaluations, have our CoPilot build an eval for you, or create a custom eval. In our example, we use one of our prebuilt evaluations for assessing code generation quality that the agent produces, specifically:
- Code Correctness: Does the generated code solve the user’s problem accurately?
- Code Readability: Is the code clean, well-structured, and maintainable?
Configure online evaluations in Arize AX
Step 8: Call the agent. Test with different user questions
There are several methods we can use to call our newly deployed agent in Databricks.
REST API Calls: You can invoke your deployed agent through HTTP POST requests to the model serving endpoint. This method provides programmatic access, allowing you to integrate the agent into applications or automated workflows by sending JSON payloads with your input data and receiving structured responses.
Model Serving UI: Databricks provides a built-in web interface where you can directly test your deployed agent. Simply navigate to the serving endpoint in the Databricks workspace, use the “Test” tab to input sample data, and see real-time responses without writing any code.
Databricks AI Playground: This interactive environment lets you experiment with your agent in a conversational interface. You can test different prompts, observe the agent’s behavior, and refine your interactions before implementing them in production scenarios.
We now illustrate how we can now test the agent via REST API:
# Test #1 - Basic question (no code generation)
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{"prompt": "What is a lakehouse?", "max_tokens": 64}' \
https://.databricks.com/serving-endpoints//invocations
# Test 2 - Math question (code generation)
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{"prompt": "What is 5*5 in python?", "max_tokens": 64}' \
https://.databricks.com/serving-endpoints//invocations
We can now illustrate how we can now test the agent using openai sdk:
from openai import OpenAI
import os
# In a Databricks notebook you can use this:
DATABRICKS_HOSTNAME = dbutils.notebook.entry_point.getDbutils().notebook().getContext().browserHostName().get()
DATABRICKS_TOKEN = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()
serving_endpoint_name = ""
client = OpenAI(
api_key=DATABRICKS_TOKEN,
base_url=f"https://{DATABRICKS_HOSTNAME}/serving-endpoints"
)
chat_completion = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are an AI assistant"
},
{
"role": "user",
"content": "Write a python function that takes a list of numbers and returns the sum of the numbers."
}
],
model=serving_endpoint_name,
max_tokens=256
)
print(chat_completion.choices[0].message.content) if chat_completion and chat_completion.choices else print(chat_completion)
Step 9: View the agent traces and evaluation results in Arize
When you run your agent, traces are automatically sent to Arize. In the Arize platform, you can see agent execution details, tool invocations, latency breakdown by component, token usage and costs, errors and metadata captured for each span and function call. Additionally, evaluation labels are captured for every trace based on the code correctness and code readability evals we setup earlier.
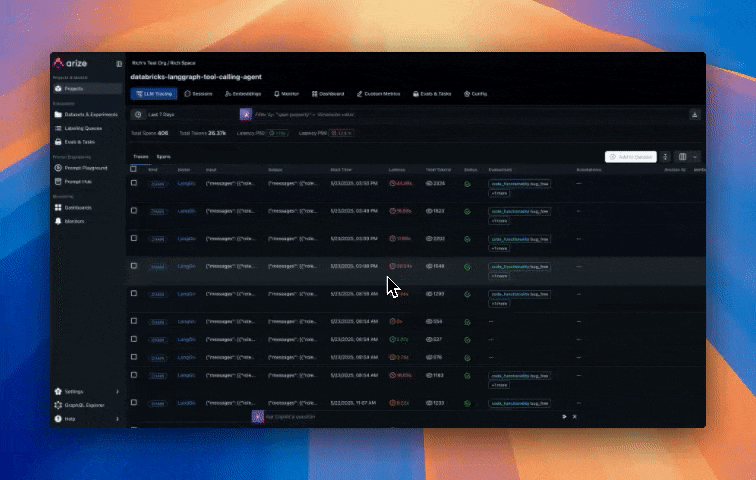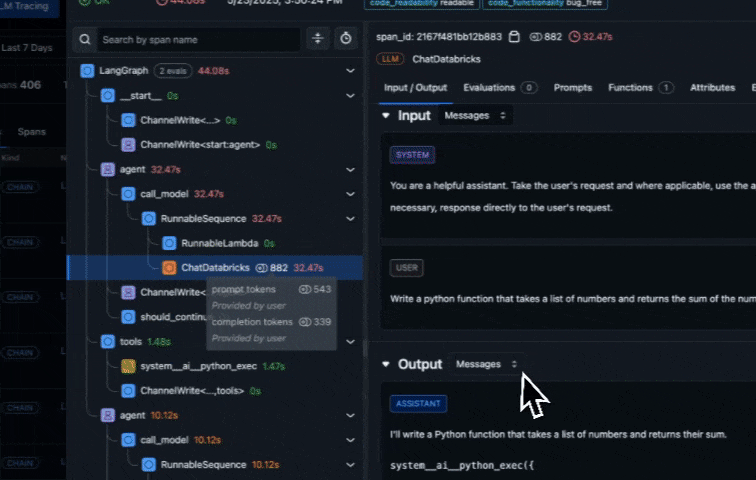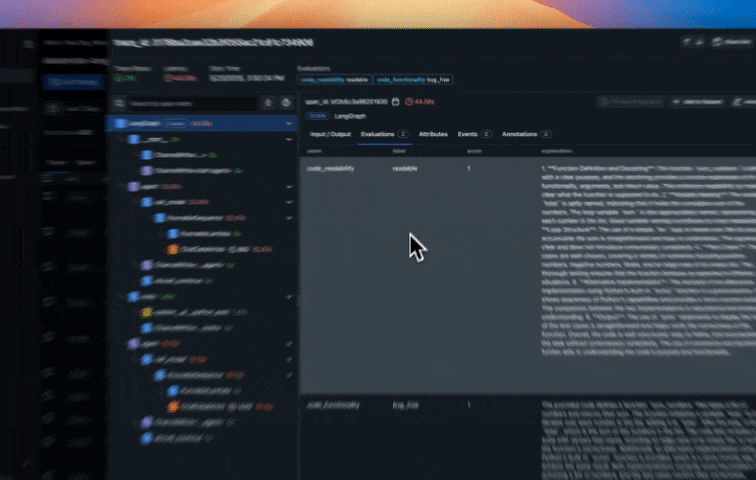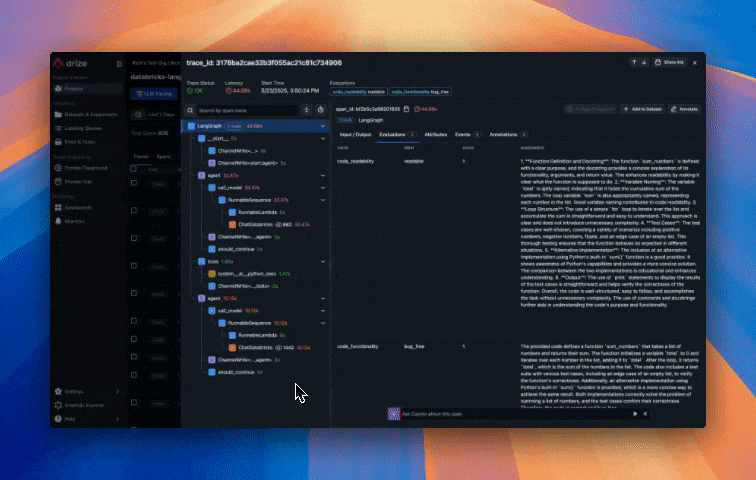
Step 10: Monitoring, alerting and KPI dashboards in Arize AX
Turn any trace attribute and evaluation label into custom metrics. Build KPI driven dashboards and monitors that proactively alert you when any degradation in performance or quality of your agent occurs.
Next Steps
With the foundation established, consider these advanced implementation options:
- Expand Agent Capabilities: Extend your agent by attaching custom tools and additional capabilities such as an external datasource in Databricks Mosaic AI.
- Enhance Evaluation Framework: Develop more sophisticated evaluation metrics tailored to your specific use case.
- Implement Experimentation Workflows: Running controlled experiments: Design and execute A/B tests to measure the impact of agent changes in a structured way
- Optimize Prompt Engineering: Utilize Arize’s prompt playground module to systematically improve agent instructions (learn more about prompt optimization)
- Generating curated datasets: Build high-quality datasets based on real user interactions for targeted testing and evaluation
- Leverage Arize’s AI Copilot: Use AI-powered assistance to analyze complex patterns in your agent’s behavior and recommend specific improvements
Set up CI/CD evaluation pipelines: Automate the evaluation process to continuously assess agent performance as you deploy new versions
Conclusion
Building high-quality AI agents requires more than just good prompts and models—it demands robust infrastructure for deployment, monitoring, and continuous improvement. By combining Databricks Mosaic AI Agent Framework with Arize’s observability platform, you get:
- Complete Visibility: Every agent decision and tool call is traced
- Automated Quality Assurance: Evaluations automatically run in real-time on production traces at scale
- Enterprise-Ready Deployment: Secure, scalable hosting with built-in monitoring
- Continuous Improvement: Data-driven insights for ongoing optimization
Ready to build your own high-quality agents? Start with the example notebook, sign up for free trials of both platforms, and transform your AI applications from experimental prototypes to production-ready systems.