



The current ecosystem around LLMs, semantic search and vector storage makes it easy to prototype but difficult to move into production. Ingesting large volumes of data specifically for embedding and upload to a vector database like Weaviate with high throughput and high reliability is difficult. Engineering teams should offload this responsibility to a vector embedding pipeline like VectorFlow. We can use LlamaIndex to query our corpus of data. Once the data has been embedded, uploaded and queried, an observability and evaluation system like Arize AI’s Phoenix needs to be in place to ensure quality remains high.
This tutorial will show you how to embed a large volume of data, upload it to a vector database, run top K similarity searches against it, and monitor it in production using VectorFlow, Arize Phoenix, Weaviate and LlamaIndex. All of these tools are open source. You can follow along and run the code in this Google Colab.
The Code
Let’s first download our dataset – a collection of movie reviews. Open a terminal and run the following:
mkdir vectorflow-arize-tutorial
cd vectorflow-arize-tutorial
wget http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
tar -xzf aclImdb_v1.tar.gzNow let’s install all our python dependencies:
pip install -q "arize-phoenix[experimental]" gcsfs llama-index weaviate-client vectorflow-client openaiWe will need a working instance of Weaviate somewhere to store our vectors. You can create a free sandbox instance on Weaviate Cloud Services. Lets create a Weaviate class to hold the vectors:
# For using Weaviate Cloud Service
import weaviate
import json
import os
weaviate_url = "https://your-endpoit"
os.environ['WEAVIATE_URL'] = weaviate_url
weaviate_key = "your-key-goes-here"
os.environ['WEAVIATE_KEY'] = weaviate_key
client = weaviate.Client(
url = os.getenv("WEAVIATE_URL"),
auth_client_secret=weaviate.AuthApiKey(api_key=os.getenv("WEAVIATE_KEY")),
)
class_obj = {
"class": "Vectorflow",
"vectorizer": "none", # we will use VectorFlow for this since its more performant
}
client.schema.create_class(class_obj)
response = client.schema.get("Vectorflow")Now that our vector database is set up, let’s ingest our movie reviews.
How to Use VectorFlow
Vector Flow is containerized to run with Docker and can be run in one command after pulling the repo. Docker is not supported by Colab, but VectorFlow has a free, managed version of VectorFlow you can try here that we will use for this colab.
Let’s ingest the first 100 movie reviews from our dataset. We have to set our Open AI API key to generate ADA embeddings. Then we can use the VectorFlow Client python package via pip to upload the documents for chunking, embedding and insertion into Weaviate.
Note that we need to configure our VectorFlow instance to point at our Weaviate class that we just created in the Weaviate cloud and we need to pass all the relevant API keys.
from vectorflow_client.vectorflow import Vectorflow
from vectorflow_client.vector_db_type_client import VectorDBTypeClient
open_ai_key = "" #@param {type:"string"}
os.environ['OPENAI_API_KEY'] = open_ai_key
vectorflow = Vectorflow()
# set API keys
vectorflow.internal_api_key = "SWITCHINGKEYS1234567890"
vectorflow.embedding_api_key = open_ai_key
vectorflow.vector_db_key = weaviate_key
# configure upload to weaviate
vectorflow.vector_db_metadata.vector_db_type = VectorDBTypeClient.WEAVIATE
vectorflow.vector_db_metadata.index_name = "Vectorflow"
vectorflow.vector_db_metadata.environment = weaviate_url
base_url = "https://vectorflowembeddings.online"
src_dir = 'aclImdb/test/pos'
paths = [os.path.join(src_dir, filename) for filename in os.listdir(src_dir)]
response = vectorflow.upload(paths[:100], base_url=base_url)
response_json = response.json()
print(f"successfully uploaded {len(response_json['successful_uploads'])} files")Please wait a minute or two for the files to upload. For a higher throughput dedicated endpoint of VectorFlow, please contact the VectorFlow team.
Next we need to query Weaviate to return all the embedding-source text pairs so that we can upload them to Phoenix later so we can visualize them.
class_name = "Vectorflow"
class_properties = ["source_data", "source_document"]
cursor = None
batch_size = 128
def get_batch_with_cursor(client, class_name, class_properties, batch_size, cursor=None):
query = (
client.query.get(class_name, class_properties)
# Optionally retrieve the vector embedding by adding `vector` to the _additional fields
.with_additional(["id vector"])
.with_limit(batch_size)
)
if cursor is not None:
return query.with_after(cursor).do()
else:
return query.do()
embeddings_text_list = []
# loop through the class, grab a batch on each loop, and setting the cursor equal to the last id grabbed so that they are grabbed in order
while True:
results = get_batch_with_cursor(client, class_name, class_properties, batch_size, cursor)
# If empty, we're finished
if len(results["data"]
["Get"]
[class_name]) == 0:
break
embeddings_text_list.extend(results["data"]
["Get"]
[class_name])
# Update the cursor to the id of the last retrieved object
cursor = results["data"]
["Get"]
[class_name]
[-1]
["_additional"]
["id"]
print(f"retrieved {len(embeddings_text_list)} items from Weaviate class {class_name}")Next we should ask some questions about the movie reviews we ingested using Llama Index. First let’s create a Weaviate Vector Store in LlamaIndex then we will ask it some questions about the movie reviews.
from llama_index.vector_stores import WeaviateVectorStore
from llama_index import VectorStoreIndex
from langchain.chat_models import ChatOpenAI
from llama_index import LLMPredictor, ServiceContext
from llama_index.callbacks import CallbackManager, OpenInferenceCallbackHandler
from llama_index.embeddings.openai import OpenAIEmbedding
callback_handler = OpenInferenceCallbackHandler()
service_context = ServiceContext.from_defaults(
llm_predictor=LLMPredictor(llm=ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)),
embed_model=OpenAIEmbedding(model="text-embedding-ada-002"),
callback_manager=CallbackManager(handlers=[callback_handler]),
)
vector_store = WeaviateVectorStore(weaviate_client=client, index_name="Vectorflow", text_key="source_data", text_field="source_data")
index = VectorStoreIndex.from_vector_store(vector_store, service_context=service_context,)
query_engine = index.as_query_engine()
queries = [
"What does the text say about sci fi channel?",
"What horror films are review?",
"Do any specific studios recieve criticism or praise?",
"Tell me about Michael Davis"
]
for query in queries:
response = query_engine.query(query)
print(response)We want to feed our queries into a dataframe so we can overlay them against our corpus when we visualize them with Phoenix:
from llama_index.callbacks.open_inference_callback import as_dataframe
query_data_buffer = callback_handler.flush_query_data_buffer()
query_df = as_dataframe(query_data_buffer)Visualization & Analyzing with Arize Phoenix
Now that we have ingested our corpus and queried it, let’s use Phoenix to visualize the data. We need to transform our source text chunks and the raw embeddings from our movie review corpus into a pandas dataframe.
import pandas as pd
import numpy as np
def storage_context_to_dataframe(embeddings_text_list) -> pd.DataFrame:
document_ids = []
document_texts = []
document_embeddings = []
for text_embedding_dict in embeddings_text_list:
document_ids.append(text_embedding_dict['_additional']
['id']) # use node hash as the document ID
document_texts.append(text_embedding_dict['source_data'])
document_embeddings.append(np.array(text_embedding_dict['_additional']
['vector']))
return pd.DataFrame(
{
"document_id": document_ids,
"text": document_texts,
"text_vector": document_embeddings,
}
)
database_df = storage_context_to_dataframe(embeddings_text_list)
database_df = database_df.drop_duplicates(subset=["text"])
database_df.head()Before we can upload this into Phoenix, should we calculate the centroids and adjust our data because we want to line up the embedding spaces for chunk and for queries. This is necessary because mathematically what is happening is the Queries contain things that make them similar, such as all having a “?” / all being a one sentence question. The UMAP picks this up, we are removing this bias out of embedding space (centroid represents in embedding space what is the core common idea across all the query embeddings), so the questions can be aligned on top of the chunks more easily.
database_centroid = database_df["text_vector"].mean()
database_df["text_vector"] = database_df["text_vector"].apply(lambda x: x - database_centroid)
# use numpy because pandas does not support averaging a list of lists, and this column contains a list of floats in each cell
query_centroid = np.mean(query_df[":feature.[float].embedding:prompt"].apply(np.array).to_list(), axis=0)
query_df[":feature.[float].embedding:prompt"] = query_df[":feature.[float].embedding:prompt"].apply(
lambda x: x - query_centroid
)Now we can create the Phoenix schema and dataset objects needed for using the system:
import phoenix as px
database_schema = px.Schema(
prediction_id_column_name="document_id",
prompt_column_names=px.EmbeddingColumnNames(
vector_column_name="text_vector",
raw_data_column_name="text",
),
)
database_ds = px.Dataset(
dataframe=database_df,
schema=database_schema,
name="database",
)Lastly we need to define our query dataset. Because the query dataframe is in OpenInference format, Phoenix is able to infer the meaning of each column without a user-defined schema by using the phoenix.Dataset.from_open_inference class method.
query_ds = px.Dataset.from_open_inference(query_df)Finally we are ready to launch Phoenix. Please be aware that it takes a minute or two for all the data to load into the visualization tool.
Using this tool we can now visualize our raw data and our queries in vector space to see how they relate to each other. This will allow you to get a sense of what some queries contain more context than others.
session = px.launch_app(primary=query_ds, corpus=database_ds)The query embeddings are represented by light blue dots and the corpus by dark gray. You can use this visualization to help identify problematic queries and holes in your dataset.
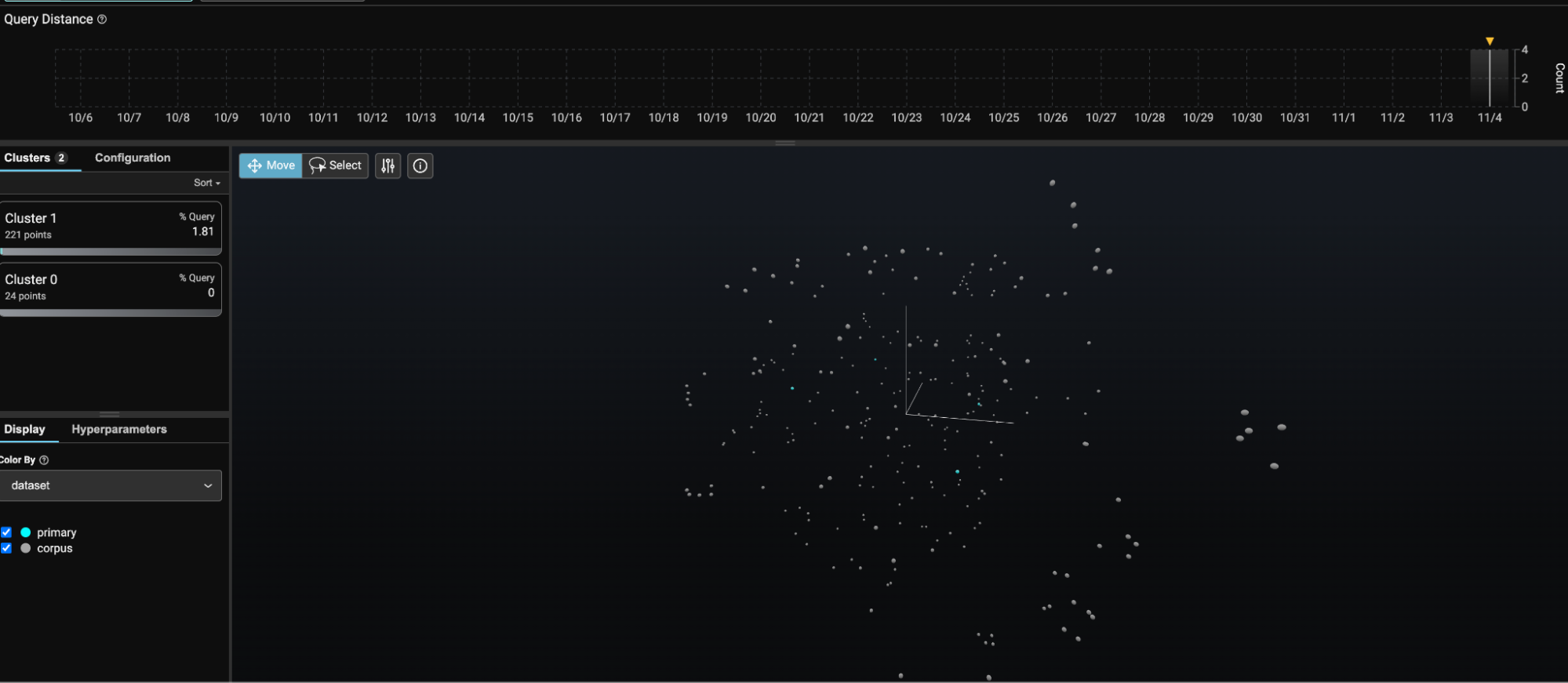
If you click on the query dot for “What does the text say about sci fi channel?” and zoom in a little on the neighboring area, you can see that there are no chunks from the corpus particularly close to this.

When the similarity search is performed, the only datapoints it finds have limited semantic similarity, which helps explain why the query for “What does the text say about sci fi channel?” has a response that states, “The text does not provide any information about the Sci Fi Channel”. This could be due to missing information in the corpus or from a misconfiguration of chunking. By default VectorFlow uses 256 token-length chunks with 128-token-length overlap. Using Phoenix, we can easily inspect our chunks to see if that split makes sense.

As seen in the screenshot above, some of the chunks are broken down into small bits that are not semantically meaningful in the context of movie reviews. Given the size of Open AI ADA’s context window, we can easily increase the chunk size to 1024. We can leverage vectorflow to seamlessly re-embed all the data:
vectorflow.embeddings_metadata.chunk_size = 1024
response = vectorflow.upload(paths[:100], base_url=base_url)Then we can use LlamaIndex to query the corpus again and Phoenix to help us evaluate. With this process largely automated, we can rapidly test different configurations including different chunking strategies and open source embeddings models to determine what gives us the best RAG search results!
Questions?
Feel free to reach out in the VectorFlow Discord or the Arize Community.