



In our most recent AI research paper community reading, we had the privilege of hosting Peter Belcak – an AI Researcher working on the reliability and efficiency of agentic systems at NVIDIA – who walked us through his new paper making the rounds in AI circles titled “Small Language Models are the Future of Agentic AI.”
The paper posits that small language models (SLMs) are sufficiently powerful, inherently more suitable, and necessarily more economical for many invocations in agentic systems, and are therefore the future of agentic AI. The authors’ argumentation is grounded in the current level of capabilities exhibited by SLMs, the common architectures of agentic systems, and the economy of LM deployment. The authors further argue that in situations where general-purpose conversational abilities are essential, heterogeneous agentic systems (i.e., agents invoking multiple different models) are the natural choice. They discuss the potential barriers for the adoption of SLMs in agentic systems and outline a general LLM-to-SLM agent conversion algorithm.
▶️ Watch
Dive In
- Read the paper
- Sign up to participate in future AI researcher discussions
Listen
Key Takeaways From the Paper
- SLMs (<10B params) are sometimes “good enough” for many nodes in an agent graph, especially tool-calling, structured reasoning, and code-orchestrated steps—sometimes matching or beating larger LLMs for those narrow tasks. This is the position paper thesis.
- SLMs can be far cheaper and faster to run (often on the order of 10–30× lower inference cost per token in real systems) and much cheaper to fine-tune for a specialized role—enabling sustainable, margin-friendly deployment.
- Think heterogeneous systems: reserve a strong generalist LLM for the “decide/plan” moments and deploy SLMs everywhere you can for the repetitive language errands.
- Practical workflow: start with a large model to map the task; then replace hot spots with specialized SLMs, fine-tune iteratively, and monitor outcomes.
Highlights from the Talk
This transcript was lightly edited for brevity.
Peter Belcak: The paper I’m presenting is a group effort from the Deep Learning Efficiency Research Group at NVIDIA Research, and the ideas reflect work across the team. The paper—Small Language Models Are the Future of Agentic AI—is a position piece: it brings together observations and evidence we’ve accumulated rather than introducing a single new benchmark or method. We argue three pillars: (1) small language models are already powerful enough for many errands agents ask for; (2) they are inherently more suitable for agentic systems; and (3) they are more economical. Combine these and you get our position that SLMs are the future of agentic AI.
Economic & Hardware Motivations
Peter Belcak: Two motivations drove this work. First, from enterprise customers: many have already captured large portions of their markets, so they’re now optimizing margins. They want solutions that deliver the same or better outcomes at lower cost and latency. Second, the field of agentic AI has stabilized enough that people are converging on tried-and-tested patterns—even if they don’t always call them that—so we can reason concretely about where smaller models fit.
On the hardware side, specialized inference chips and optimized runtimes change the calculus. When you design for efficiency and can utilize a GPU fully, SLM inference can be dramatically cheaper per token than LLM inference. Fine-tuning SLMs is also comparatively inexpensive, which lets you iterate several times toward your quality target instead of paying for one enormous training pass on a large model.
What Counts as a “Small” Language Model?
Peter Belcak: We’re comfortable calling models below roughly 10B parameters “small” for the purposes of agentic use. There’s nuance by architecture and deployment constraints, but sub-10B is a useful working range for most cases we discuss.

Agent Architecture: Decision Layer vs. Code Orchestration
Peter Belcak: When many people say “agent,” they picture the LM doing everything—deciding what tools to call, when to call them, and how to stitch context together. In production, especially where processes are well-established, a lot of orchestration is actually code. A rigorous process runs; the LM is invoked at targeted points for language errands (classification, extraction, rewriting, summarization, routine Q&A) or to generate natural interactions. We separate:
-
Decision/Planning (“LM agency”): moments that truly benefit from generalist reasoning.
-
Code agency/orchestration: deterministic or well-bounded steps guided by software, where the LM performs focused sub-tasks.
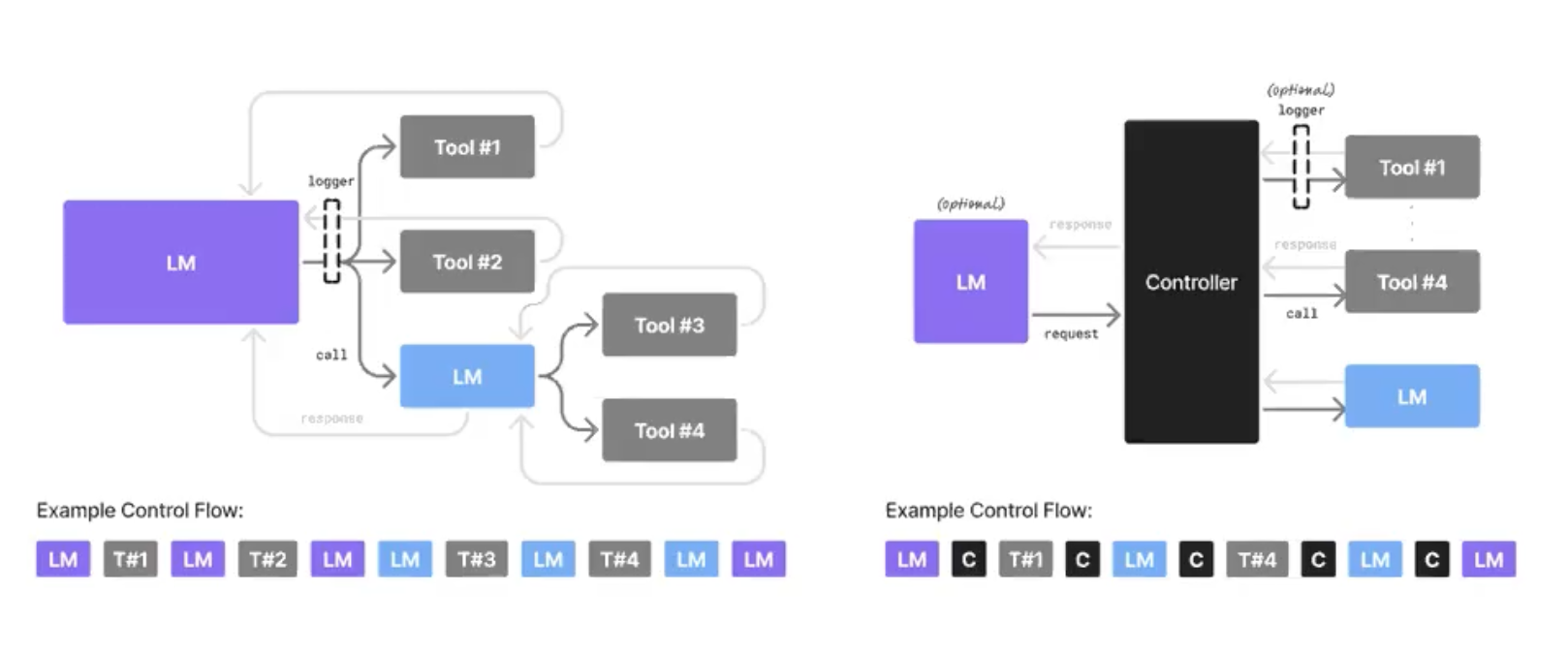
Where SLMs Win in the Agent Graph & Benchmarks
Peter Belcak: Concretely, there are “spots” in your agent graph where 2–9B models can match or beat larger models on subsets of general benchmarks and task suites—especially tool-calling, structured extraction, templated generation, and short-context reasoning that benefits from light fine-tuning. The common pattern today is: pick a general LLM, then focus on a few capabilities. We suggest flipping that: identify jobs to be done and slot in SLMs that excel at those jobs, then fine-tune.
Cost, Fine-Tuning & Deployment Considerations
Peter Belcak: Rule of thumb: when you can keep a GPU saturated, SLM inference cost per token can be an order of magnitude (often 10–30×) lower than LLMs. Exact numbers vary with batching, hardware, and mixture-of-experts vs. dense model details, but the broad economics are clear. Similarly, SLM fine-tuning is cheap—you can run several short cycles to reach your target quality. With LLMs, general fine-tuning quickly becomes expensive, pushing teams toward prompt-only adaptation that may not deliver stable improvements for narrow tasks.
Edge & On-Device Use Cases
Peter Belcak: SLMs open the door to edge and on-device deployments across sensors, cameras, PCs, and phones—places where a large model is impractical. Conversational agents and other light-duty language components can run locally with better privacy and latency, while your back end reserves heavy tasks for a larger model if and when needed.
A Practical Workflow: Start Large, Specialize Small
Peter Belcak: A pragmatic approach we’ve seen work:
-
Prototype with a strong generalist to map the task and surface failure modes.
-
Replace hot spots with specialized SLMs fine-tuned on your domain data.
-
Iterate—cheaply—on the SLMs until you hit quality and latency targets.
-
Keep a heterogeneous stack: SLMs for the common errands; LLMs reserved for the truly hard generalist moments.
Questions About Small Language Models Are the Future of Agentic AI
What size range qualifies as a “small” language model?
Peter Belcak: Below ~10B parameters is a good working definition for agentic use. Architecture and deployment constraints matter, but sub-10B covers most cases discussed in the position paper.
Do SLMs need to run fully on-device (phone/laptop/edge) to “count”?
Peter Belcak: No. “Small” is about capability and efficiency, not a requirement to be phone-only. That said, many SLMs can run locally on consumer-grade hardware, which is part of their appeal for privacy and latency.
How do you mitigate bias or safety issues with SLMs?
Peter Belcak: Two levers: (1) Data—use properly sanitized, verified data for post-training and evaluation; (2) System design—don’t rely solely on the model. Surround it with retrieval, tools, checks, and guardrails so the overall system mitigates model shortcomings.
Are SLMs good at tool-calling and compatible with emerging protocols?
Peter Belcak: Yes—many SLMs are strong at tool-calling and structured outputs, which is exactly where agents spend time. You’d still want good prompting and schema-aware evaluation; from there it’s standard tool execution within your stack.
Is there empirical evidence behind the position, or is it just an essay?
Peter Belcak: It’s a position paper that synthesizes observations, results, and references across systems work. The companion NVIDIA Research page and blog post summarize the stance and link materials; see the arXiv paper for references.