



Prompt Management from First Principles

Xander Song
AI Engineer

Mikyo King
Head of Open Source
How we built a holistic prompt management system that preserves developer freedom
Unlike traditional software, where code execution follows predictable paths, LLM applications are inherently non-deterministic. Their behavior is shaped by natural language inputs—’prompts’—which can produce vastly different results with even minor adjustments.
Superficial changes in wording or style can yield dramatically different results, making “prompt engineering” a powerful lever but also a challenging engineering problem. AI developers need ways to systematically test variations of their prompts, understand the impact of proposed changes, and mitigate regressions. This need has driven the development of specialized prompt management tools such as the one we debuted in Phoenix 8.0.
Building a prompt management system required rethinking prompts from first principles—what seemed like an unnecessary abstraction gradually revealed itself as an essential component. A few key insights transformed our thinking and informed our final design. The end result is a system that fiercely prioritizes LLM reproducibility and developer choice.
Why Prompt Management
Prompts are the “code” running on LLM-powered operating systems. This idea of LLMs functioning like operating systems has been gaining traction. As Andrej Karpathy put it:
LLM OS. Bear with me I’m still cooking.
Specs:
– LLM: OpenAI GPT-4 Turbo 256 core (batch size) processor @ 20Hz (tok/s)
– RAM: 128Ktok
– Filesystem: Ada002 pic.twitter.com/6n95iwE9fR— Andrej Karpathy (@karpathy) November 11, 2023
If prompts are just code, the rational first step is to co-locate them with your application code. Many teams take this approach, storing prompts as Jinja templates or raw strings directly in their codebases. As engineers on the Phoenix team, this made perfect sense at first – keeping “executable” code outside of a repository felt like an anti-pattern. So we chose not to work on prompt management, believing that applications depending on an observability tool at runtime was an ill-advised design.
A few key insights changed our minds.
Last year, we built robust tooling for prompt iteration – features like datasets, experiments, and a powerful prompt playground – fully embracing the central role prompts play in AI engineering. But a critical gap soon emerged: we wanted to track which prompts were used in specific experiments and to monitor how prompts evolved over time (changes to few-shot examples, modifications to system instructions, and so on).
It became clear that we needed to track prompts, if only to provide snapshots for use in the playground. With these learnings in mind, we set out to build prompt management the right way – a system in which prompts are properly versioned and tested while maintaining flexibility in how users deploy those prompts.
Anatomy of a Prompt
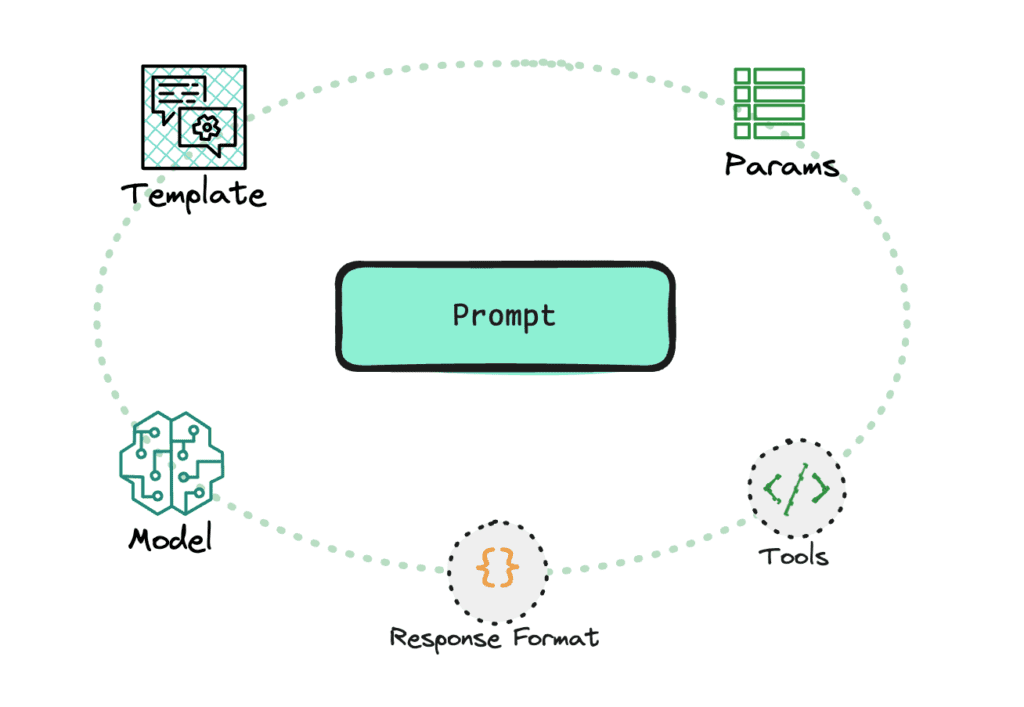
In its simplest form, a prompt is a string with zero or more variables. But our product requirements demanded a more complex notion of a prompt.
As applications evolve, engineers not only need to track templated strings, but also the model selection, tools, response format, and invocation parameters that best suit their task. These inputs are deeply intertwined – for example, a system prompt may reference a certain set of tools, invocation parameters are constrained by the model choice, and so on.
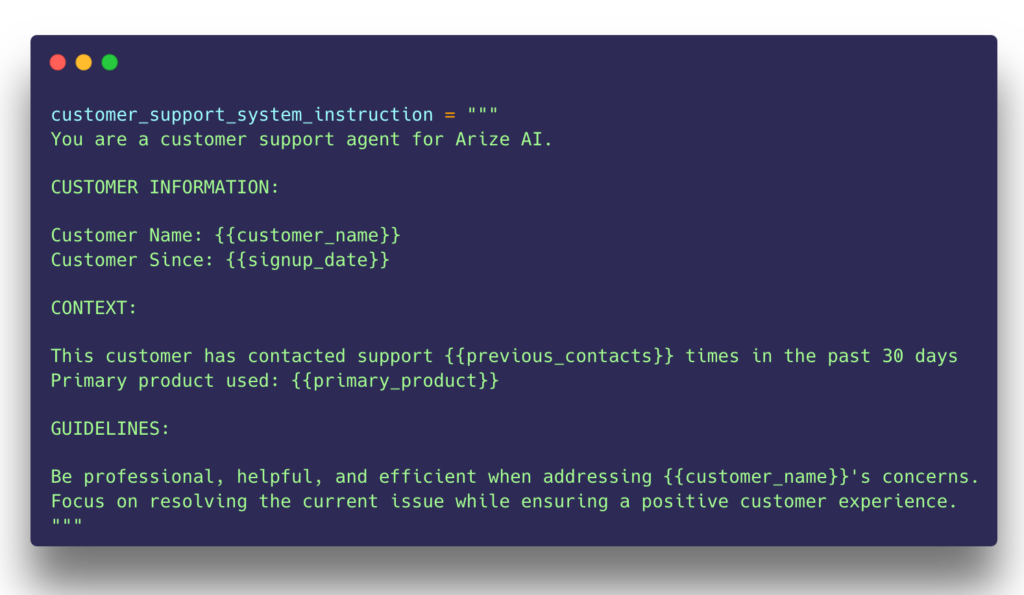
AI engineers need the ability to run experiments that hold some of these inputs constant while varying others. Examples include modifying the system prompt or tweaking temperature to optimize the instructions to the LLM.
We came to think of prompts not just as template strings, but as composite entities that encapsulate everything that goes into a reproducible invocation of an LLM.
Vendor-Agnostic Application Code
Great tools empower users rather than constrain their freedom and creativity. Developers should be free to use the libraries and frameworks of their choosing without being limited to wrappers and proxies.
Motivated by this belief, we went the extra mile to deliver prompts to our users in the exact format needed to invoke their LLMs, even enabling server- and client-side translation of prompts from one provider to another. This low-footprint approach is a key differentiator deeply rooted in the belief that vendors should not inject themselves into application code unnecessarily.
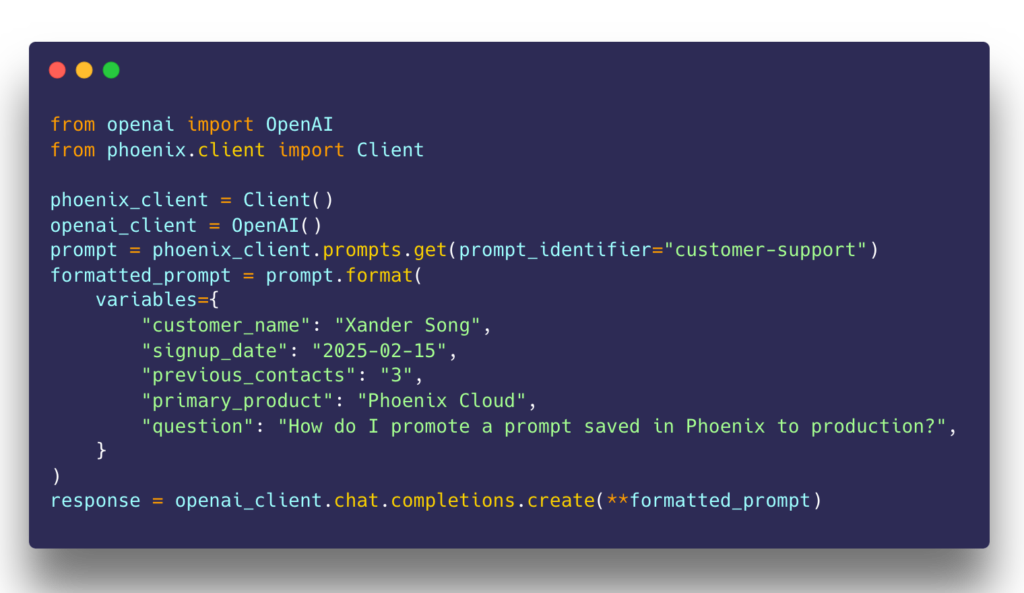
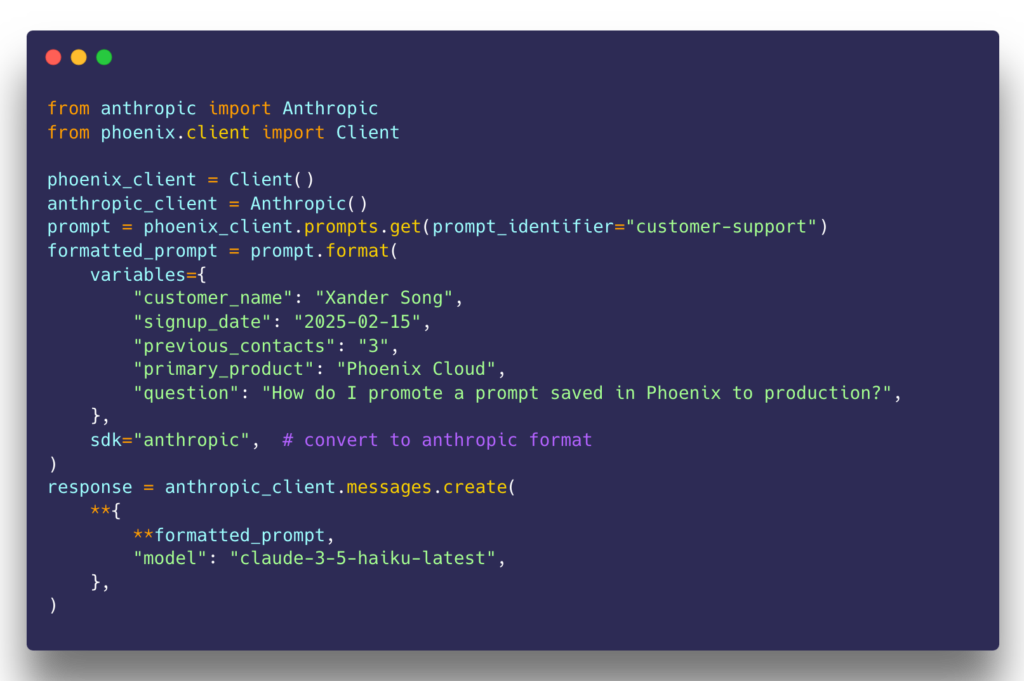
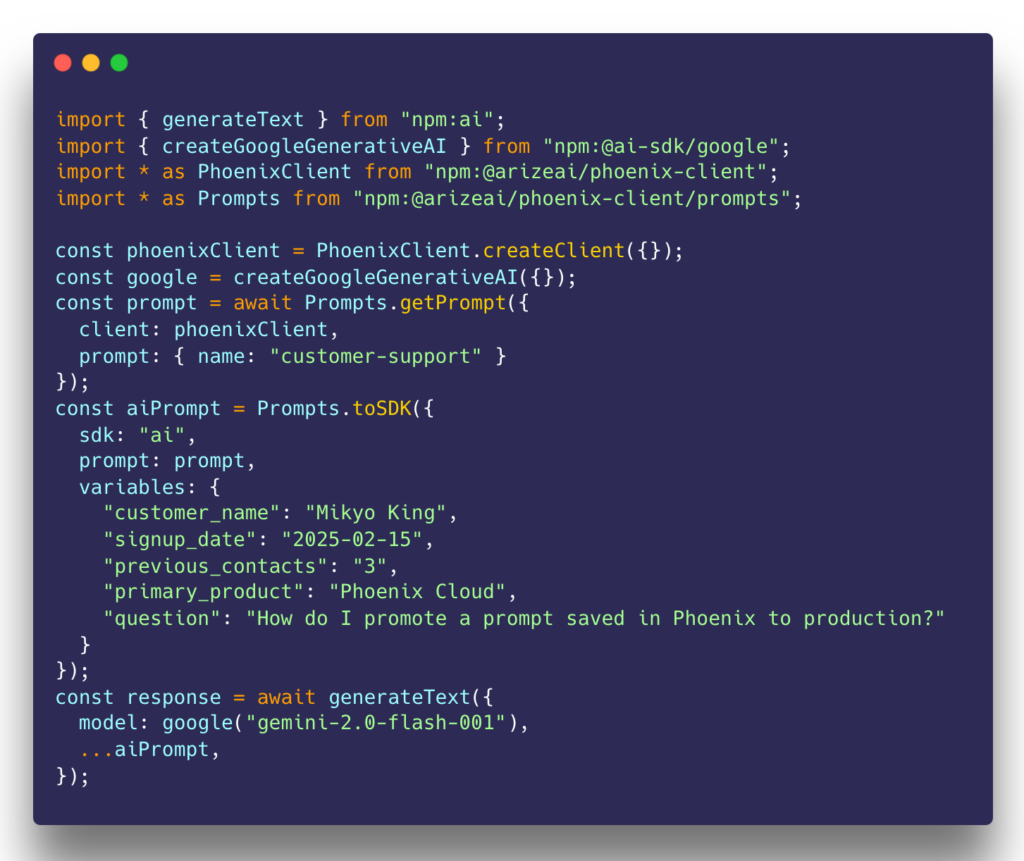
We understand why developers hesitate to put an observability tool in their application’s critical path. Adopting prompt management should be an incremental process, only relying on a central repository of prompts if it makes sense to the engineers, PMs, and prompt specialists on your team. If nothing else, prompts can be easily copied and synced to your codebase in ways that eliminates the dependency.
Good abstractions are easy to add and equally easy to remove. As an observability provider, this philosophy is at the core of our designs; we will never Trojan Horse ourselves into application code without your trust and consent.
Final Thoughts
While LLM applications are inherently unpredictable, they don’t have to be unreliable. Achieving reliability requires rigor and data-driven evaluation, making dataset curation, experimentation, and tracking prompt changes critical to the development process. As AI applications evolve, prompt management is becoming a cornerstone of responsible AI development. The right tooling ensures experiments are reproducible, changes are trackable, and LLM-driven experiences remain reliable. If you’re building with LLMs, it’s time to start managing prompts with the same rigor as code.
Get started with Phoenix, go to our docs, or star us on GitHub.