



When evaluating AI applications, we often look at things like tool calls, parameters, or individual model responses. While this span-level evaluation is useful, it doesn’t always capture the bigger picture of a user’s experience. That’s where session-level evaluations come in.
In this post, we’ll walk through how to run session-level evaluations using the Arize Python SDK. We’ll cover what sessions are, why they matter, and how you can implement them in your own workflow.
You can try it yourself by running our notebook tutorial and signing up for a free Arize AX account. We also have a video walkthrough below that covers this concept by building and evaluating an AI tutor.
What Does a Session Mean In the Context of AI and Agent Engineering?
A session is a collection of related traces tied together by a session ID. Instead of evaluating a single tool call or LLM output, sessions give you a holistic view of multi-turn interactions.
Think of a chatbot:
- Each user message and chatbot response can be represented as a trace.
- Every span within those traces is tagged with the same session ID.
- Together, these traces form a session, representing the entire conversation.
This grouping allows us to ask questions like:
- Did the chatbot help the user reach their goal?
- Was the information accurate across the conversation?
- Did the user show signs of frustration?

Getting Started
How To Set Up Sessions in Code
When instrumenting your code you’ll want to attach session or user IDs to your spans. This allows Arize to handle the collection and concatenation of spans into sessions.
You can do this with OpenInference Instrumentation and span attributes:
- using_session: Group spans by a session ID.
- using_user: Group all traces from a specific user ID.
- using_attributes: Combine both spans based on session and/or user IDs.
Preparing Data for Evaluation
Arize AX’s Export Client allows you to pull spans into a DataFrame.
From there, you can:
- Collapse spans into a single row per session using the session ID.
- Separate user messages from AI messages.
- Sort everything by time to preserve conversational flow.
This prepares the data for evaluation templates.
Running Session-Level Evaluations
With your session DataFrame ready, you can evaluate across conversations using LLM-as-a-judge templates.
Some common evaluation types include:
- Session Correctness – Checks whether responses are factual, conceptually accurate, and relevant to the user’s question.
- Session Frustration – Detects whether the user expressed confusion or dissatisfaction.
- Session Goal Achievement – Evaluates whether the user reached their intended outcome by the end of the session.
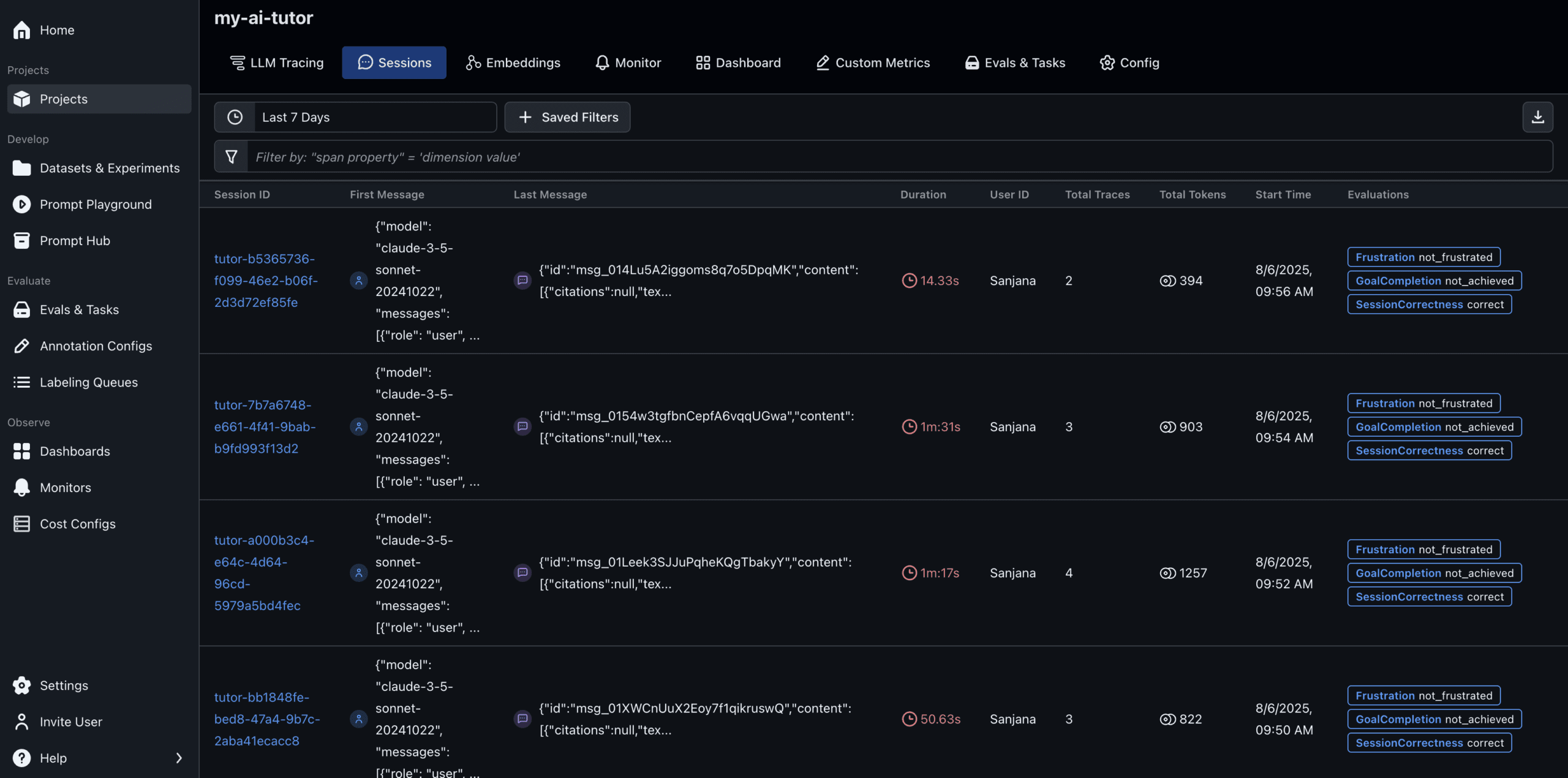
Logging Evaluations Back to Arize AX
After running evaluations in code, you can log results back to Arize for visualization and further analysis.
Arize attaches evaluation results to each session, making it easy to explore:
- Which sessions were unsuccessful
- Where users expressed frustration
- How the model performed across multiple turns
From here, you can filter sessions by outcome to further your development process.
Why Session-Level Evaluations Matter
Span-level checks help you debug at the micro level, but session-level evaluations capture the user’s end-to-end experience. By combining both span and session evaluations, you get a more complete view of your AI system’s performance.
With Arize and the Python SDK, it’s straightforward to group spans into sessions, run evaluations, and log results back to the UI for analysis.