






Just fifty years ago, machine learning was a new idea. Today it’s an integral part of society, helping people do everything from driving cars and finding jobs to getting loans and receiving novel medical treatments.
When we think about what the next 50 years of ML will look like, it’s impossible to predict. New, unforseen advancements in everything from chips and infrastructure to data sources and model observability have the power to change the trajectory of the industry almost overnight.
That said, we do know that the long run is just a collection of short runs and in the current run, there is an emerging set of tools and capabilities that are becoming standards for nearly every ML initiative. We have written about the 3 most important ML tools: a feature Store, a model store, and an evaluation store. Click here for a deeper dive.
Beyond the tools that power ML initiatives, the roles that shape data teams are also rapidly evolving.
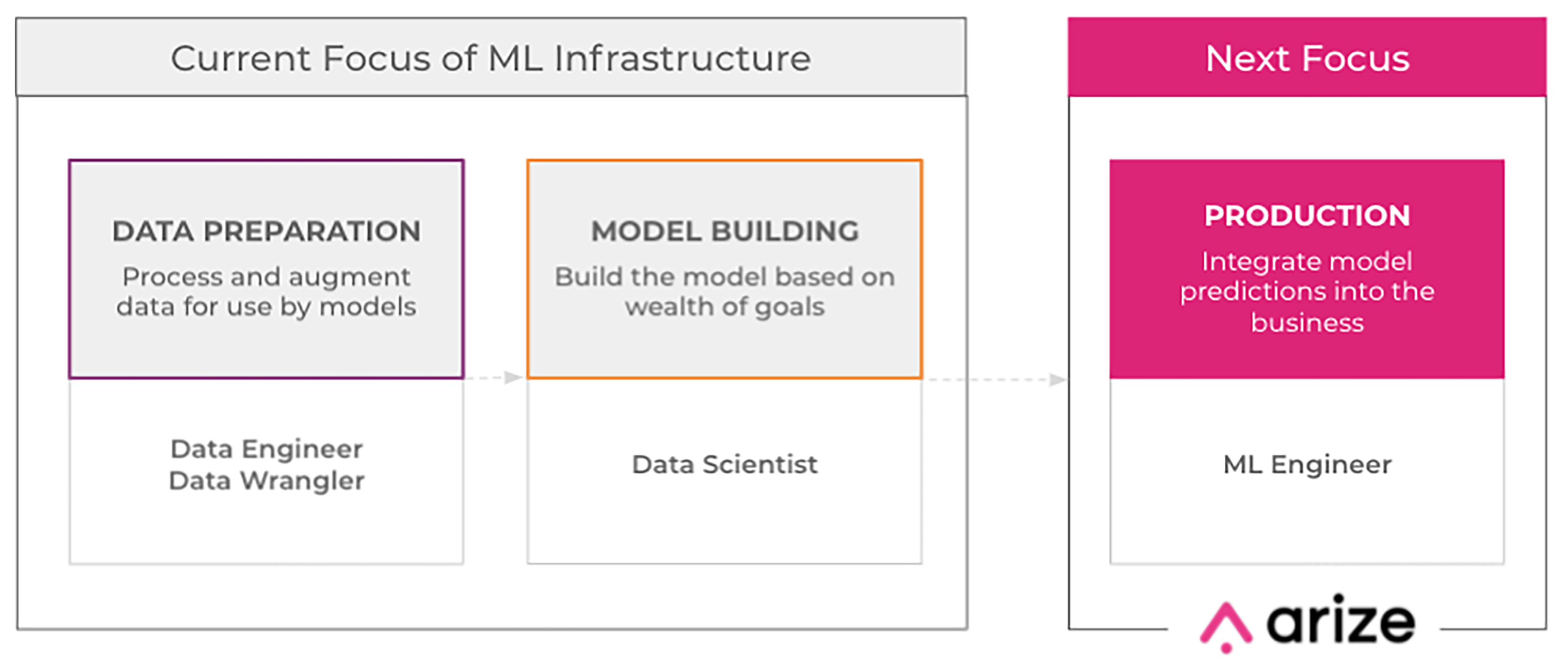
As we outline in our ML ecosystem whitepaper, the machine learning workflow can be broken into three stages — data preparation, model building, and production and at every step of the process, the skills and requirements are different:
- Model building is the domain of data scientists. They are highly trained experts in math and statistics and apply these disciplines to design, build and optimize models to solve specific business challenges.
- ML ops fall under a group of engineers that are responsible for a workflow that integrates the development and operational aspects of ML infrastructure.
In many ways, the relationship between data scientists and ML ops teams is similar to the left brain-right brain divide, with logic (the model) on one side and creativity (operations) on the other. We know that there are differences between the hemispheres which can impact the brain’s ability to solve important problems and that a thick band of neural fibers exists to enable information being processed on one side of the brain to be shared with the other side.
In ML, companies have identified the need for a new class of expertise that can, similar to these neural fibers, bridge the gap between the data scientists that build the models and the teams that operationalize them. Enter the ML engineer.
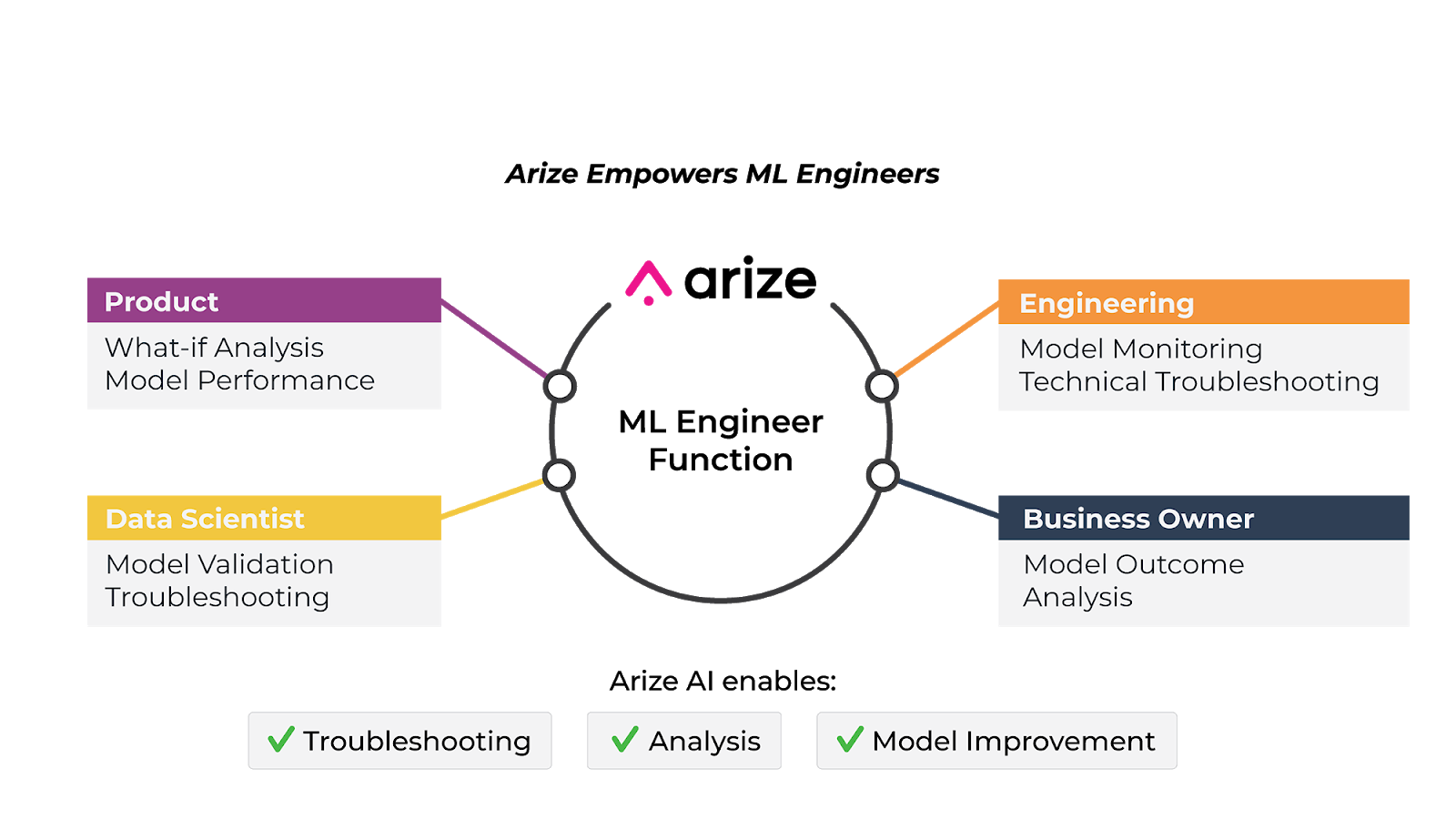 At the highest level, the ML engineer is responsible for getting models from research into the real world and ensuring they achieve business objectives. We spoke with several leading ML practitioners to understand how this evolving role is adapting to meet the needs of evolving ML initiatives. Let’s dig in:
At the highest level, the ML engineer is responsible for getting models from research into the real world and ensuring they achieve business objectives. We spoke with several leading ML practitioners to understand how this evolving role is adapting to meet the needs of evolving ML initiatives. Let’s dig in:
Rohan Iyengar, Uber

Rohan Iyengar is a software engineer at Uber focused on leveraging ML, AI, and data to solve challenging problems.
“At a company like Uber, you need specific knowledge of each model to understand if the success metrics that you have defined are being met once these models reach production,” says Iyengar. “This is where the role of an ML engineer comes in. When complexity is high, as is the case with Uber’s ML infrastructure, scale, reliability, and finding and observing the right metric are very involved. You need a role that can sit between the model builders and the operations teams to make sure you’re achieving your business goals.”
Harrison Chu
 Harrison Chu recently joined Arize from Lyft where he led the Dispatch & Matching team, a heavily cross-functional team of data scientists and engineers dedicated to implementing and optimizing systems to more efficiently match passengers and drivers.
Harrison Chu recently joined Arize from Lyft where he led the Dispatch & Matching team, a heavily cross-functional team of data scientists and engineers dedicated to implementing and optimizing systems to more efficiently match passengers and drivers.
“In my experience at Lyft and in prior ML roles, it became evident that the industry needs a new class of role that sits in-between data scientists that build pipelines and engineers that deploy the models so that the team can understand what the model is doing in the real world. Many organizations don’t have clear communication between the two hemispheres, so they never quite know the distinction between the offline artifact and the model in the production setting.”
Jason Xie, Adobe
 Jason Xie is a senior research scientist at Adobe where he works on ML solutions for the company’s video ad network with a self-service DSP (demand-side platform) which enables customers to buy and publish ads contextually based on complex algorithms.
Jason Xie is a senior research scientist at Adobe where he works on ML solutions for the company’s video ad network with a self-service DSP (demand-side platform) which enables customers to buy and publish ads contextually based on complex algorithms.
“In response to changing technology and privacy trends, we’ve been adapting our ML models for the future of privacy-safe advertising,” notes Xie. “One of the biggest challenges with this approach is that instead of the touchpoints a consumer encounters on their path to purchase, we are now exploring various new privacy safe protocols such as Google Chrome’s FLoC and Microsoft Edge’s PARAKEET, as the industry evolves. Ultimately, we believe this big shift will bring the most privacy-safe ecosystem to consumers but will require a fresh approach to ML.”
“In our case, ML engineers have become more important than ever because evolving approaches to ad serving require new layers of sophistication with respect to resolving issues once models are in production. At the end of the day, they sit in between the processing and serving of the models and making sure we’re solving clients’ business challenges.”
Today, companies spend millions of dollars developing and implementing ML models, only to see a myriad of unexpected performance degradation issues arise. Models that don’t perform after the code is shipped are painful to troubleshoot and negatively impact business operations and results.
In order to overcome these challenges, data teams need both the tools to observe their models in production and the teams that understand how to make them perform once they leave the lab. While the roles required to make ML initiatives successful will continue to change as new challenges emerge, for now, companies should invest in ML engineers to ensure that their investments pay off.