



LLM as a Judge Evaluation
Traditionally, evaluating LLM and generative AI systems has been slow, expensive, and subjective. Human annotators are expensive. LLM-as-a-Judge uses large language models themselves to evaluate outputs from other models.
What Is LLM-as-a-Judge?
LLM as a judge LLM as a judge refers to a family of AI evaluation methods using large language models to evaluate outputs from other models. Instead of relying solely on humans for model quality scoring, in other words, much of the work of testing multi-agent systems and AI applications for quality, accuracy, relevance, coherence, etc., can be offloaded to LLM judges.
In addition to enabling scalable, cost-effective automated evaluations, LLM judges often perform at roughly the same level as human reviewers.
This page covers why this technique is gaining in popularity, various subtleties involved in using it in different kinds of tasks, and where we think it’s heading in the future.

Why Use LLMs As Judges?
Lower AI evaluation costs top the list of LLM-as-a-judge benefits, but many are drawn to this approach because it’s the only known way to quickly and consistently scale assessments across thousands of generations.
Even better, LLMs-as-a-judge also shows high agreement with human preferences when used correctly — in some studies, matching human-human agreement rates.
The next few sections will discuss some of the different ways in which LLMs can be used as a critical part of an automated evaluation pipeline.
Online vs. Offline Evaluation
LLM-as-a-Judge can be used in two distinct evaluation settings:
- Offline Evaluation is ideal for experimentation, benchmarking, and model comparisons. It happens after inference and supports complex, detailed analyses with minimal latency constraints.
- Online Evaluation is used in real-time or production environments, like dashboards or live customer interactions. Such contexts require LLMs to make quick, consistent judgments, often with stricter constraints on latency, compute, and reliability. Understanding this distinction helps teams choose the right prompting strategy, model, and evaluation architecture for their use case.
Understanding this distinction helps teams choose the right prompting strategy, model, and evaluation architecture for their use case.
Trace vs. Span Level Evaluation
LLM-as-a-judge can be used for span-level scoring of individual steps in a workflow and trace-level LLM evaluations of an entire workflow end-to-end:
- Span-level evaluation focuses on individual steps within an LLM application (like a single model call, retrieval, or use of a tool), letting teams pinpoint where errors or hallucinations occur in a multi-step workflow.
- Trace-level evaluations examine the entire chain of operations triggered by a user request to judge whether the overall workflow achieved a correct and coherent end result.
Including Explanations in Evaluations
Rather than simply asking an LLM-as-a-judge to output a score or label, it can be valuable instead to require an explicit explanation or reasoning trace in addition. These chain-of-thought (COT) explanations tend to improve alignment with human judgements while increasing transparency because you can see the why behind a particular model decision.
Importantly, you should have the explanation produced before the final label or score, as this makes it easier to review the reasoning independently, thereby aiding in debugging, auditing, and so forth.
It’s also worth pointing out that explanations don’t always yield improvements, as there are many tasks for which a well-structured prompt already provides enough context for the judge, especially when the model has been optimized for reasoning. In such cases, explanations add costs associated with longer prompts and slower inference, so use discretion when deciding whether a model-generated explanation will actually help in a particular case.
Binary vs Multi-Categorical Scoring
When you use LLM-as-a-judge, you must decide on the format of the output, which often involves selecting between a simple binary verdict (e.g., pass/fail, yes/no) or a richer multi-categorical/numeric scoring scale (e.g., 1-5, letter grades). In our experience, binary outputs tend to produce more stable and reliable evaluations than more subtle numeric scoring. For this reason, many practitioners have gravitated towards binary or discrete categorical judgements, which force clearer, more reproducible decisions that make it easier to perform robust comparisons.
LLM-as-a-Judge vs. Code-based Evaluation
There’s a distinction between using LLM-as-a-judge and crafting code-based evaluations that is worth drawing out.
When evaluating model outputs, code-based evaluation involves writing deterministic scripts or tests (in Python or JavaScript, for example) that check whether the output meets specific, well-defined conditions (correct structure, including required fields, and so on). This approach is great when you have a clear “ground truth” determining whether an output is valid, and it incurs no additional token costs or latency, meaning you can run it cheaply and frequently, as needed.
That said, code-based evaluation usually falls short when the aspects you care about are more subjective, nuanced, or open-ended, such as the factual accuracy of a free-form text, the quality of its style, how safe or toxic it is, etc. For such evaluations, LLM-as-a-judge is likely the way to go.
Real-World Applications
Today, teams use LLM-as-a-Judge techniques to evaluate everything from LLM summarization to chatbots, retrieval to RAG pipelines, and even agentic systems. These evaluations are powering dashboards, tracking performance regressions, guiding fine-tuning, and informing go-to-market.
Some examples of what this looks like in practice:
- Evaluate chatbot answers vs. ground-truth
- Track hallucination rates across model versions
- Score retrieved document relevance in RAG pipelines
- Assess output toxicity or bias
- Diagnose failures of agentic tool-use behavior and planning
LLM as a Judge Evaluators
LLM as a judge is useful across a raft of use cases, including detecting hallucination, accuracy, relevancy, toxicity, and more. The Arize AI team has tested and assembled a list of simple evaluation templates that use an LLM-as-a-judge and achieve target precision and F-scores above 70%:
| Eval & Link to Docs (Prompt + Code) | Description |
| Hallucinations | Checks if outputs contain unsupported or incorrect information. |
| Question Answering | Assesses if responses fully and accurately answer user queries given reference data. |
| Retrieved Document Relevancy | Determines if provided documents are relevant to a given query or task. |
| Toxicity | Identifies racist, sexist, biased, or otherwise inappropriate content. |
| Summarization | Judges the accuracy and clarity of summaries relative to original texts. |
| Code Generation | Evaluates correctness of generated code relative to task instructions. |
| Human vs AI | Compares AI-generated text directly against human-written benchmarks. |
| Citation | Checks correctness and relevance of citations to original sources. |
| User Frustration | Detects user frustration signals within conversational AI contexts. |
Beyond Static Generations
The foregoing discusses LLM-as-a-judge generally, but the next few sections will discuss applying this technique in two emerging domains: agents and multi-modal models.
Agent Evaluation With LLM as a Judge
LLM judges aren’t just for evaluating static generations. They’re also being used to evaluate multi-step agent behavior — including planning, tool use, and reflection. In addition to offering custom evals, Arize supports templates for structured agent evaluation across dimensions like:
| Evaluation Type | Description | Evaluation Criteria |
| Agent Planning | Assesses the quality of an agent’s plan to accomplish a given task using available tools. | Does the plan include only valid and applicable tools for the task? Are the tools used sufficient to accomplish the task? Will the plan, as outlined, successfully achieve the desired outcome? Is this the shortest and most efficient plan to accomplish the task? |
| Agent Tool Selection | Evaluates whether the agent selects the appropriate tool(s) for a given input or question. | Does the selected tool align with the user’s intent? Is the tool capable of addressing the specific requirements of the task? Are there more suitable tools available that the agent overlooked? |
| Agent Parameter Extraction | Checks if the agent correctly extracts and utilizes parameters required for tool execution. | Are all necessary parameters accurately extracted from the input? Are the parameters formatted correctly for the tool’s requirements? Is there any missing or extraneous information in the parameters? |
| Agent Tool Calling | Determines if the agent’s tool invocation is appropriate and correctly structured. | Is the correct tool called for the task? Are the parameters passed to the tool accurate and complete? Does the tool call adhere to the expected syntax and structure? |
| Agent Path Evaluation | Analyzes the sequence of steps the agent takes to complete a task, focusing on efficiency and correctness. | Does the agent follow a logical and efficient sequence of actions? Are there unnecessary or redundant steps? Does the agent avoid loops or dead-ends in its reasoning? |
| Agent Reflection | Encourages the agent to self-assess its performance and make improvements. | Can the agent identify errors or suboptimal decisions in its process? Does the agent propose viable alternatives or corrections? Is the reflection process constructive and leads to better outcomes? |
Judging Multi-Modal Systems
As multi-modal large language models (MLLMs) like GPT-4V and Gemini have gained the ability to process text, images, charts, and video, traditional evaluation metrics have been found inadequate. BLEU scores or embedding distances, for example, simply can’t capture the semantic and contextual richness of multi-modal reasoning, such as how well a model links a caption to an image or interprets visual data in a dialogue.
Recent work on MLLM-as-a-judge introduces a new benchmark for evaluating these systems across scoring, pairwise comparison, and batch-ranking tasks. Studies show that while top models align closely with human preferences in pairwise comparisons, performance sometimes degrades on fine-grained scoring and reasoning tasks. LLM hallucination and inconsistency remain obstacles, but Arize will monitor this fast-moving space closely. One emerging technique that can help is prompt learning.
Custom LLM-as-a-Judge Evaluators: Why & How to Build Your Own
In specialized domains — such as medical research, finance, or agriculture — off-the-shelf evaluators often miss domain-specific criteria, so teams build custom LLM-as-a-Judge evaluators with datasets tailored to their tasks.
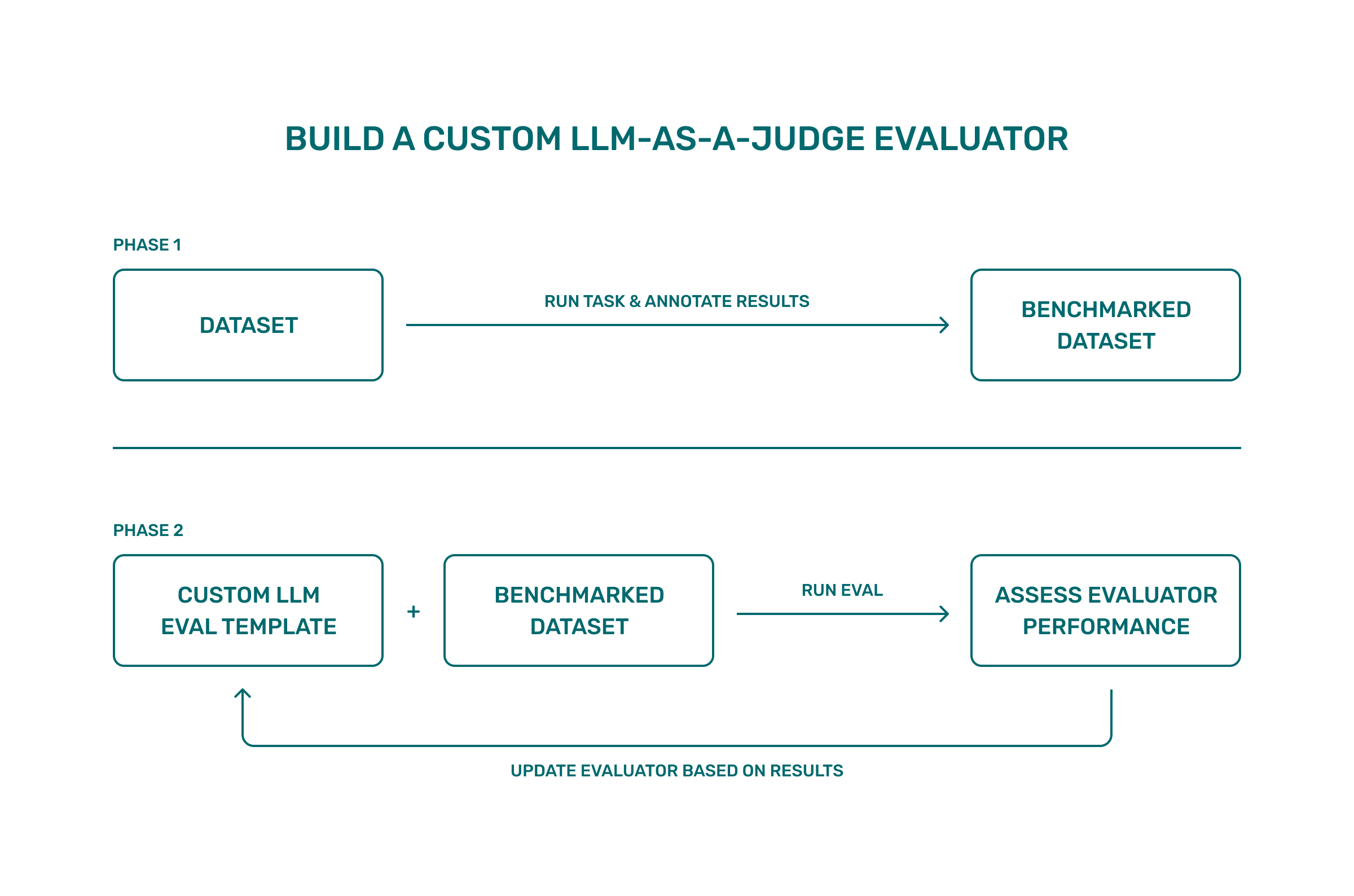
The approach is straightforward:
- Start with a small benchmark dataset built from realistic examples
- Add annotations with clear label definitions (for example: “accurate,” “almost accurate,” “inaccurate,” with a brief explanation of each)
- Use that as ground truth (more information on using human-annotated data can be found in the next section)
- Write an evaluation template that states the judging criteria plainly and constrains the judge to your label definitions. If the task mixes modalities, structure the prompt accordingly (e.g., text followed by an image)
- Run the judge on your dataset and compare its labels to your annotations to measure evaluator performance
- Then iterate:
- Examine cases where the judge disagrees
- Clarify the instructions or add a short, concrete example
- Re-run.
Many improvements come from making the label definitions explicit; the video below, for instance, walks you through the process of creating an image classification model that works on receipts. One way it could be improved would be to require that “total,” “itemized list,” and “category” all be correct to assign an ‘accurate’ label, which has the added benefit of keeping the task model and judge model separate.
| Phase | Inputs | What you do | Result |
|---|---|---|---|
| Build benchmark dataset | A small set of realistic outputs and references (e.g., receipt images with generated expense summaries) | Produce traces and annotate them using a categorical accuracy configuration with short explanations | A labeled benchmark dataset (inputs, outputs, labels, notes) |
| Create evaluation template | Fixed label definitions and the inputs the judge should see (e.g., text + image URL) | Write a structured evaluation template (prompt parts such as text → image → instructions) with unambiguous label definitions | A reusable template that restricts outputs to your labels |
| Run experiment | Benchmark dataset + template; a separate judge model | Apply the template to each example, then compare the judge’s label to the annotated label to compute evaluator performance | Baseline results with per-case outputs and rationales |
| Iterate on template | Disagreements between judge and annotations | Tighten instructions (e.g., require correct total, itemized list, and category for accurate), optionally add a brief example, then re-run | Better alignment between judge labels and annotations, reflected in updated scores |
For a deeper code walkthrough, see this Arize-Phoenix custom evals tutorial and companion Colab notebook.
How to Use Human-Annotated Data in Evaluations
Before moving on, we’ll briefly pause to dwell on the role that human-annotated data can play in building robust AI evaluation pipelines.
When you want reliable reference standards for a pipeline, human-annotated data plays a foundational role. By manually labeling a representative sample of outputs (or interactions, traces, or sessions), you establish a “ground truth”, thereby capturing nuanced judgments about quality, correctness, safety, style, or appropriateness that automated systems often miss. These annotations then serve as a baseline to compare against, helping you calibrate LLMs-as-a-judge evaluations and detect divergences between the judge and human expectations.
Once you have human-annotated data, you can build evaluators–whether that be code-based, LLM-based, or both–that test new generations or agent behaviors systematically.
LLM-as-a-Judge: Basis In Research
Several academic papers establish the legitimacy, efficacy and limitations of LLM as a judge.
| Paper | Authors & Affiliations | Year | Why It Matters |
| Judging LLM-as-a-Judge with MT-Bench | Lianmin Zheng et al. (UC Berkeley) | 2023 | Demonstrated GPT-4’s evaluations closely align with humans. |
| From Generation to Judgment: Survey | Dawei Li et al. (Arizona State University) | 2024 | Comprehensive overview identifying best practices and pitfalls. |
| G-Eval: GPT-4 for Better Human Alignment | Yang Liu et al. (Microsoft Research) | 2023 | Provided methods for structured evaluations that outperform traditional metrics. |
| GPTScore: Evaluate as You Desire | Jinlan Fu et al. (NUS & CMU) | 2024 | Allowed flexible, tailored evaluations through natural language prompts. |
| Training an LLM-as-a-Judge Model: Pipeline & Lessons | Renjun Hu et al. (Alibaba Cloud) | 2025 | Offered practical insights into effectively training custom LLM judges. |
| Critical Evaluation of AI Feedback | Archit Sharma et al. (Stanford & Toyota Research Institute) | 2024 | Explored replacing humans with LLMs in RLHF pipelines. |
| LLM-as-a-Judge in Extractive QA | Xanh Ho et al. (University of Nantes & NII Japan) | 2025 | Showed LLM judgments align better than EM/F1 with human evaluation. |
| A Survey on LLM-as-a-Judge | Jiawei Zhang et al. (University of Illinois Urbana-Champaign) | 2025 | Offers a comprehensive taxonomy of LLM-as-a-Judge frameworks, benchmarks, and use cases across NLP and multi-modal domains. Emphasizes challenges like bias, calibration, and evaluation reproducibility. |
Techniques for Structuring LLM-as-a-Judge Prompts
The quality of a prompt plays a large part in the quality of a language model’s eventual output, and the same is true for using LLM-as-a-Judge. The way you pose the evaluation task matters, and your best shot at success is to start with clear and well-structured prompts. Here are a few commonly used formats.
Common LLM-as-a-Judge Prompt Formats
- Single-answer evaluation: Present a user input and a single model response. Ask the LLM to rate it on specific criteria like correctness, helpfulness, or fluency.
- Pairwise evaluation: Provide two outputs for the same input and ask the LLM to select the better one, explaining its choice.
Prompting Best Practices
- Include explicit criteria (e.g., “Rate based on helpfulness, factual accuracy, and completeness.”)
- Ask for chain-of-thought reasoning before the final score or decision
- Request structured outputs (e.g., a JSON format or bullet points)
- Randomize candidate order and evaluate both permutations to reduce position bias.
Example prompt:
You are an expert AI evaluator. Given a user question and two model answers, select which response is better and explain why.
Question: ...
Answer A: ...
Answer B: ...
Evaluation Criteria: helpfulness, factuality, coherence.
Respond in this format:
Better Answer: A or B
Explanation: ...
Limitations & Pitfalls
Some LLMs may introduce subtle biases when used as evaluators. For example, as noted above, certain models show a tendency to prefer responses in position A when performing pairwise comparisons, and often favor longer responses. These and similar kinds of behaviors can skew evaluation outcomes, which is why consistency in prompt formatting and evaluation criteria is key to getting trustworthy results.
Keep in mind:
- Evaluation quality depends heavily on prompt structure (see “Prompting Best Practices” for some advice on how to create reliable prompts)
- Use chain-of-thought (CoT) or reasoning steps to boost reliability
- Compare against a human gold standard (especially early on)
Future Directions for LLM-as-a-Judge
As LLM-as-a-judge matures, it’s begun to become part of the core layer of AI evaluation infrastructure. Developers are integrating judges directly into continuous-integration pipelines, real-time dashboards, and agent feedback loops, meaning evaluation will probably become an always-on process. Emerging trends include domain-specific judges trained on human-curated datasets, LLM-as-a-trainer systems that feed judgments back into model fine-tuning, and open-source benchmarks that make apples-to-apples comparisons possible.
In the next two sections, we’ll cover two major developments that are especially important.
Toward Standardized Evaluation Protocols
The growing adoption of automated AI evaluation makes standardization all the more important. Without shared protocols, evaluation results remain difficult to reproduce, verify, or compare. Researchers have started advocating common rubrics, prompt formats, metadata logging, and bias-testing procedures to ensure consistency across frameworks such as Arize’s. A recent paper making this argument is the 2025 “Survey on LLM-as-a-Judge”, which emphasizes reproducible scoring templates, documented chain-of-thought reasoning, and inter-judge reliability metrics such as Cohen’s Kappa and Krippendorff’s Alpha.
Meta-Evaluation: Evaluating the Judges
As AI judges themselves grow in influence and importance, meta-evaluation – principled ways of assessing the quality of the model’s evaluations – is emerging as a safeguard.
Studies like “Judging the Judges” have found that even advanced LLM judges can exhibit position bias, length bias, or inconsistent reasoning when prompts change, which is one impetus behind the work being done to develop meta-evaluation frameworks to test whether judges align with human annotations, remain robust to prompt variations, and avoid systematic preference patterns.
Ultimately, reliable meta-evaluation will help ensure that LLM-as-a-judge still offers sound evaluations as the technology advances. Consult the sections above for techniques you can use today to move in this direction.
Big Picture
LLM-as-a-Judge isn’t just a trend — it’s quickly becoming the default evaluation approach in many production AI stacks. When used carefully, it enables faster iteration, better tracking, and more rigorous quality control. And best of all: it’s fully automated.
Want to learn more about LLM-as-a-judge? Book a demo.