



AI Agents are launching in 2025 at an incredible rate. Examples range from Cursor IDE agents to sales SDR agents and back office workflow assistants. Making these agents work and work well is arguably the biggest challenge. As deployments scale, we observe that teams shipping the most reliable and performant agents are those that invest in evaluation and observability from the start.
Why this comparison matters now
In the rapidly evolving landscape of LLM evaluation platforms and observability tools, it helps to understand how each one actually supports building high quality agents at scale. Building proof of concepts is easy; engineering highly functional agents is not. Reliable agents aren’t discovered; they’re engineered through systems built to observe, measure, and improve behavior over time.
Here, we zero in on five platforms teams ask about most often and that lead in adoption and market share: Arize AX, Arize Phoenix, LangSmith, Braintrust, and Langfuse. All can help you test agents, but they are built for different stages of the lifecycle.
What “Good” looks like in an LLM evaluation platform
Built on open foundations and standards
Evaluations should be portable, and your data should belong to you. Platforms built on open standards like Open Telemetry and OpenInference make it easier to move data, query results, and feed insights downstream into analytics, product, and reliability workflows. Open foundations ensure evaluations remain reproducible and interoperable across your stack as it evolves.
Interoperable across providers and frameworks
The LLM ecosystem moves fast with new model releases, frameworks, orchestration layers, and AI agent memory platforms popping up weekly. Evaluation tools need to integrate cleanly across inference providers and agent frameworks without custom code or adapters. True interoperability ensures your evaluation and observability pipelines continue to function effectively even as your stack (and the market) evolves.
Breadth and depth of evaluation features
Mature evaluation platforms extend beyond simple performance metrics. They support a wide range of evaluation types — from session-level LLM evaluations, to out of the box LLM as a Judge Evaluators, or code evaluators — all built on a consistent interface and shared data model. Practical evaluation tools reveal the why behind results, surfacing context, patterns, and causes that make outcomes explainable and actionable. Each evaluation run should capture the full context so results can be replayed under the same conditions they were produced from, with differences explained.
Agent evaluation support
The future of AI systems is agentic — where reasoning and behavior unfold across multiple steps, tools, and decision points within an interactive workflow. Evaluations must evolve to capture and interpret these multiple-step agent traces holistically. LLM evaluation platforms that treat these traces as first-class data can evaluate not only the final answer but also the reasoning that produced it — connecting outcomes to the agent’s planning, context use, and decision making along the way.
AI agent for AI engineers
Some platforms now include AI assistants that help analyze traces, improve prompts, test datasets, design evaluations, and interpret results in context — for example, linking evaluation outcomes to business impact or product quality. A strong assistant should support planning of AI debugging tasks, execute workflows, help you debug your AI agents and help you improve your prompts.
Platforms
Arize AX
The most complete, enterprise-ready evaluation and observability platform — built on open standards, optimized for scale, and enhanced by an AI assistant.
Instrumentation with Arize AX
Arize offers the fastest path to full tracing coverage on its managed AX platform. Its auto-instrumentation supports the widest range of frameworks and providers, so getting started only requires a few lines of code before your AI application or agent begins emitting standardized traces right away.
# pip install arize-otel
# Import open-telemetry dependencies
from arize.otel import register
# Setup OTel via convenience function
tracer_provider = register(
space_id = "your-space-id", # in app space settings page
api_key = "your-api-key", # in app space settings page
project_name = "your-project-name", # name this to whatever you would like
)
# Import the automatic instrumentor from OpenInference
from openinference.instrumentation.openai import OpenAIInstrumentor
# Finish automatic instrumentation
OpenAIInstrumentor().instrument(tracer_provider=tracer_provider)
Example: using Arize AX and OpenInference to automatically trace OpenAI calls with OTel
Good for
- Agent evaluation: Arize AX sets the standard for AI agent evaluation, providing deep visibility into how agents reason, plan, and act through multi-step workflows. With built-in support for session-level evaluation, tool-calling analysis, agent convergence tracking, and coherence scoring, Arize helps teams assess the quality of each step in an agent’s process. It shows how well your agent selects tools, follows instructions, maintains context, and stays aligned with its goals over time. Recognized across the ecosystem for leadership in agent evaluation and observability, Arize AX simplifies understanding how agents think and helps build systems that teams can trust.
- Vendor-agnostic evaluation and observability: Arize was one of the first companies to launch OTel-based LLM observability and maintains an influential position in the OTel group defining standards for LLM observability. Arize maintains hundreds of Otel-based integrations across frameworks and foundation models, the most extensive set of LLM tracing integrations supported in the industry.
- Alyx and Arize’s agent-based platform: Alyx, Arize’s Cursor-like agent, was one of the first launched in the industry. Alyx provides teams with agent powered experience to search, troubleshoot, and build AI applications. Find a problem, annotate the problem, write an evaluation, test it, and save that evaluation for serving in your product, all in one agent-driven workflow.
- Enterprise and production scale: Arize was one of the first vendors to deploy at production scale, processing trillions of events a month. The Arize Database (adb) is purpose-built for high-volume agent telemetry, with fairly extensive published benchmarks. Arize is also one of the few vendors that have true real-time monitors that run at scale in production.
- Data control and single source of truth: As of October 2025, Arize is the only vendor that enables seamless integration into your data lake, providing zero-copy access to data. Arize’s adb supports Iceberg and Parquet datasets as a single source of truth, enabling consumption of AI data by any downstream line of business. Cloud-backed data with smart active caching enables teams to store years of data, paying 100x less than monolithic observability platforms. For example, Langsmith is 10x in cost for 1 year of data.
- Online evaluations: Arize has one of the more extensive online evaluation solutions in the market, leveraging its open-source eval library at scale. They are currently one of the only platforms with online evaluations for trace and sessions necessary for agent evaluation. In addition, in-depth logging and test-in-code replay make for one of the better self-serve evaluation experiences.
- Evaluation-specific strengths: These include: support for multi-criteria evaluations, allowing you to use one LLM judge to score multiple dimensions in a single request; transparent and published benchmarks for every built-in LLM evaluation metric template; and Alyx to help you build evals — never start from a blank slate.
Limitations
- Small virtual private cloud self-hosted deployments: Arize AX is designed for large-scale, managed environments and is generally less suited for small, single-server VPC setups. In these cases, Arize Phoenix offers a lightweight, self-hosted alternative that better fits smaller teams or localized deployments.
- OTel can take a little more configuration: Arize uses OTel for instrumentation, which can require slightly more configuration than proprietary approaches. However, this tradeoff provides the benefit of adopting a standardized, open framework that aligns with the broader industry direction. Auto-instrumentation features ease initial setup and help reduce configuration overhead.
- Extensive siloed data regions: For organizations operating across multiple data regions, such as a global enterprise subject to data-residency requirements, a hybrid deployment can be more efficient than maintaining multiple Arize AX instances. Using Arize Phoenix for regional workloads and Arize AX for centralized operations helps balance data-sovereignty needs with cost and operational complexities.
Arize-Phoenix
Open source observability and evaluation for LLMs and agents — self-hosted, Otel-native, and built on the same open schema that powers Arize AX.
Instrumentation with Phoenix (Open Source)
If you prefer to run evaluations and observability locally or self-hosted, Arize Phoenix offers an open source implementation of the same OpenInference schema used in Arize AX. It emits native OTel and accepts traces from any OpenInference-instrumented exporter.
With native OTel support, Phoenix makes sending telemetry as simple as registering a tracer and running your app.
w
from phoenix.otel import register
# configure Phoenix tracer
tracer_provider = register (
project name="your-llm-app",
auto_instrument=True,
)
tracer = tracer_provider.get_tracer(__name__)
As with AX, Phoenix can also trace all calls to any supported libraries with auto-instrumentation. (OpenAI shown as an example)
# pip install openinference-instrumentation-openai
import os
import openai
os.environ["OPENAI_API_KEY"] = "Input OpenAI key..."
client = openai.OpenAI()
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content":
Phoenix also supports TypeScript instrumentation, providing first-class OpenInference tracing for any Node or TypeScript environment.
Good for
- Ease of deployment: Phoenix is lightweight and designed for quick iteration. With minimal dependencies and native OTel support, teams can instrument applications and begin capturing traces with only a few lines of code. This makes it well-suited for fast experimentation and iteration.
- Data control and speed of deployment: As an open-source, self-hosted solution, Phoenix lets teams deploy observability in minutes while retaining full control over where data is stored and processed — ideal for environments with strict data-residency or sovereignty requirements.
- Extensibility: Phoenix’s open architecture and extensible plugin system make it easy for developers to customize functionality, integrate new data sources, or build custom evaluators.
- Agent evaluation capabilities (compared with other open source tools): Compared with other open-source evaluation and tracing tools such as Langfuse, Arize Phoenix provides deeper support for agent evaluation. It captures complete multi-step agent traces, allowing teams to assess how agents make decisions over time. While other OSS frameworks focus primarily on tracing and visualization, Phoenix extends those capabilities to include structured evaluation workflows and integration paths to managed Arize AX deployments for production-scale observability and evaluation.
- Prompt management: The OSS core of Phoenix now includes a prompt management module (released April 2025) that lets teams create, version, store, and reuse prompt templates across models and workflows.
- Production-ready even before upgrading: The OSS core ships with async workers, scalable storage adapters, and a plugin system for custom eval judges. These features make it stable for sustained workloads, not just experimentation, allowing teams to run meaningful evaluation pipelines before adopting a managed service.
- Open-source control with the same trace schema used in Arize AX: Phoenix shares the same OpenInference trace schema as Arize AX, ensuring full compatibility between self-hosted and managed environments. Teams can start locally with complete control over infrastructure and later migrate seamlessly to AX without changing instrumentation or data models.
- OTel-first integrations and notebooks: Built natively on OpenTelemetry, Phoenix integrates easily into existing observability and analytics stacks. Evaluation results can be exported to notebooks, dashboards, or downstream BI tools, making it simple to extend Phoenix into broader analytical workflows.
Limitations
- You manage the infrastructure: Teams lacking DevOps expertise may find upgrades and storage management distracting.
- Enterprise guardrails: Complete security and access controls, including SSO, RBAC, and audit trails, are enabled through Arize AX.
LangSmith
Purpose-built for LangChain developers, offering a smooth evaluation and debugging loop — so long as you’re comfortable with staying in the LangChain ecosystem.
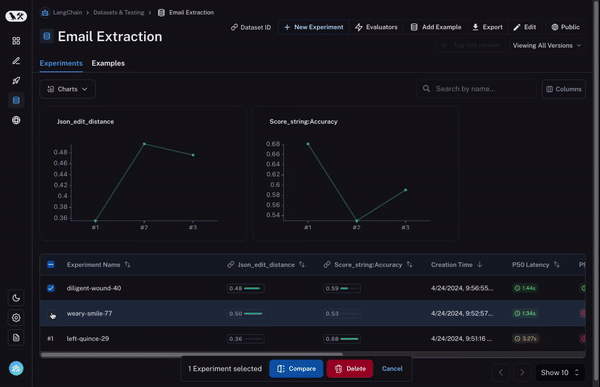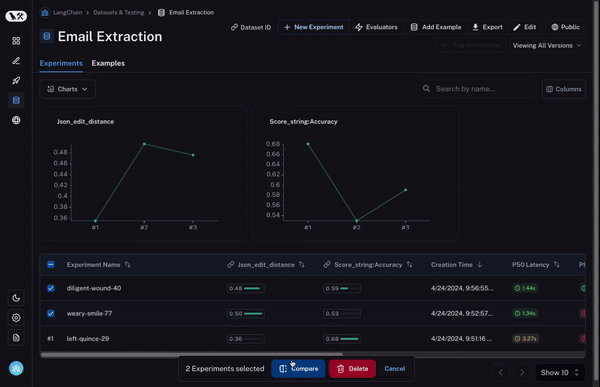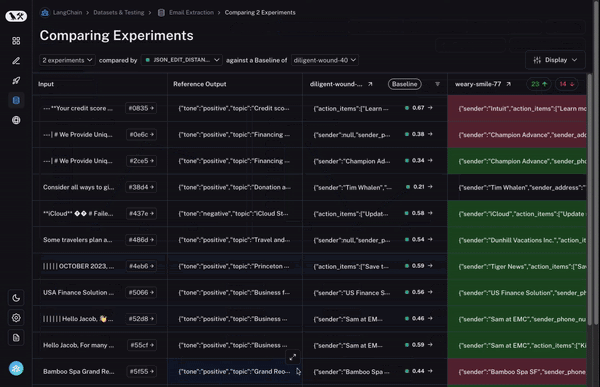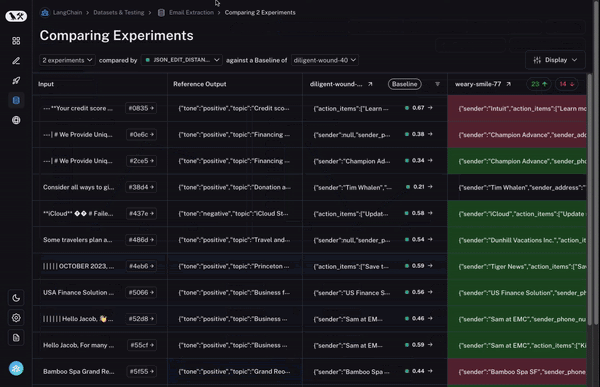
Instrumentation with LangSmith
While Arize AX and Phoenix are vendor-neutral and OpenTelemetry native, LangSmith is purpose-built for the LangChain ecosystem. It provides its own proprietary tracing layer that captures AI application and agent activity automatically for any LangChain or LangGraph workflow.
OpenTelemetry integration for LangSmith is available as a separate integration that requires manual configuration.
Good for
- Teams that are all-in on the LangChain ecosystem: Best for organizations fully committed to the LangChain ecosystem. Great for teams that only use LangGraph and are ok with the future risk of vendor lock-in.
- Lightweight, small-scale deployments: LangSmith deploys quickly with minimal infrastructure requirements, making it well-suited for small teams or rapid iteration environments.
- Rapid prototyping with LangChain and LangGraph: You can go from idea to running evals in minutes, with visualization tools that help make early experimentation low friction.
- Fast regression testing during dev cycles: Built for quick feedback loops while building and tuning chains.
- Adaptive LLM evaluators: Evaluation agents that learn from human corrections, reducing prompt hand-tuning for judges over time.
Limitations
- LangChain-first approach: Tracing, prompt canvases, and dataset iteration feel native within the LangChain ecosystem but rarely translate smoothly outside of it. Langsmith does not work well with 3rd party agent frameworks focusing on integrations with LangGraph first.
- No vendor-neutral instrumentation story: LangSmith’s tracing is designed around LangChain workflows, so integrating with other orchestrators takes extra work.
- Session-level agent evaluation depth: LangSmith supports step and trajectory evaluation, but full session-level assessments of complete agent workflows may require custom instrumentation or configuration.
- Limited data portability: LangSmith keeps evaluation data in its own formats, so moving results into tools like BigQuery or Snowflake requires bulk exports, which can be slow or limited by runtime constraints.
- Python-first orientation: It fits naturally in Python workflows, but teams using mixed stacks or TypeScript-heavy agent codebases may hit friction.
- Scaling beyond LangChain workflows: Once you move to custom routers or other toolchains, you’ll usually need to add your own instrumentation to get comparable visibility.
- Online monitoring limitations: As production volumes grow, workspaces can hit their limits fast, so teams reportedly often end up exporting data elsewhere.
- Limited evaluation detail: Among evaluation workflows, LangSmith supports value and comment style scoring by default. Still, users report that advanced metric summarization, such as variance or multi-dimensional metrics, may require custom code or external processing.
Braintrust
Solid early-stage development and evaluation workflows, but not yet built for production observability or scale.
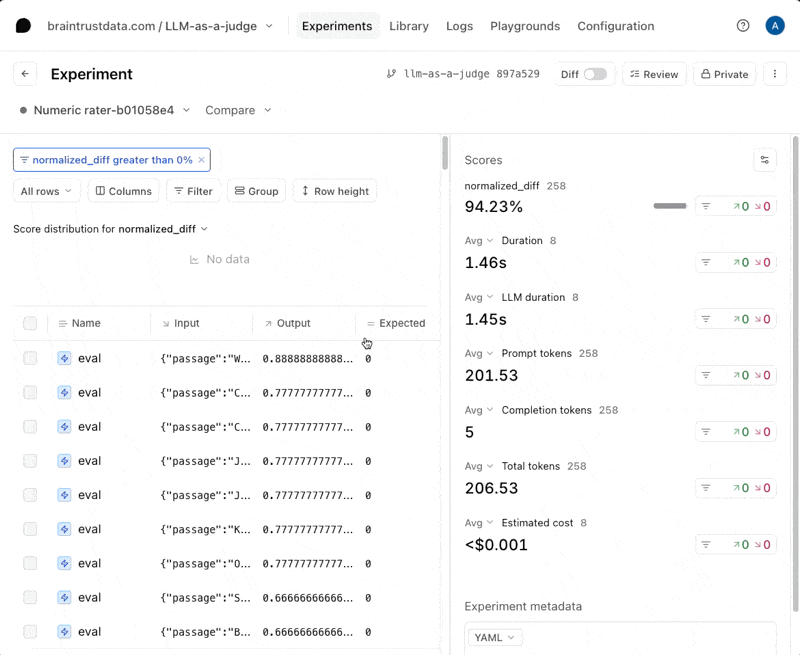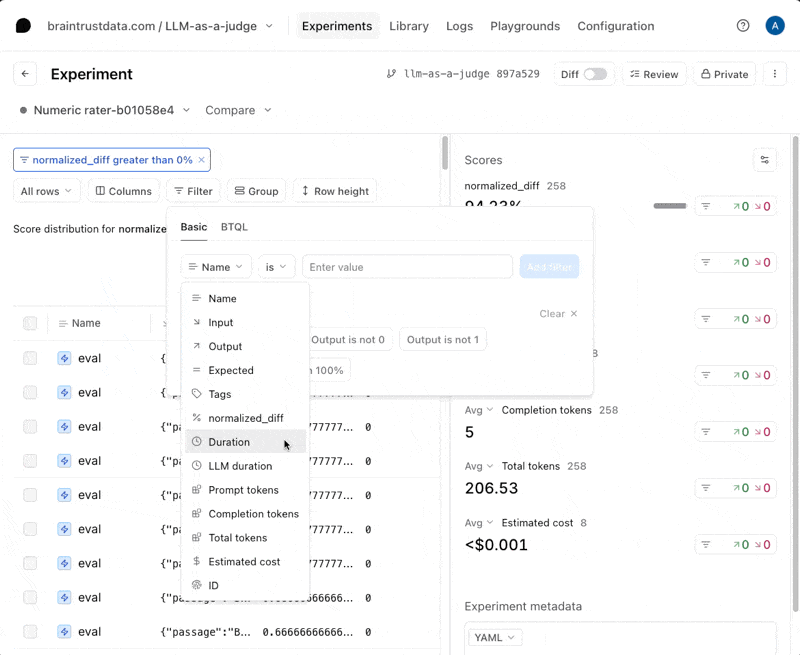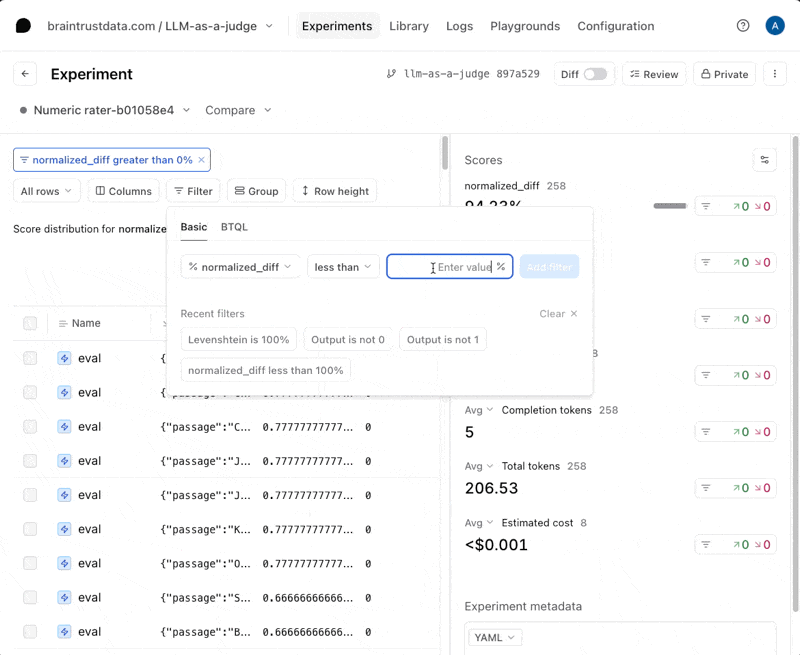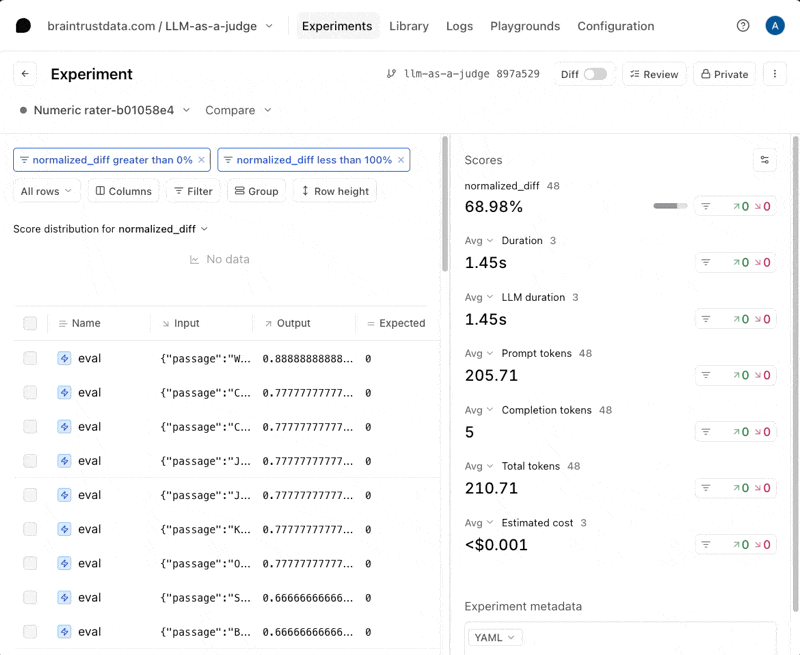
Instrumentation with Braintrust
Early versions of Braintrust focused on what’s known as the development loop — the space where teams design, test, and refine LLM behavior through evals, human review, and prompt versioning.
Over time, Braintrust expanded its toolkit to include optional tracing and OpenTelemetry integration to bridge some of the gap between experimentation and observability. Tracing in Braintrust is still considered an advanced use case rather than a core feature. Its tracing API enables teams to log nested spans and link model calls or evaluations to sub-components of a workflow, offering a window into how each component behaves. However, as implied by their documentation, tracing is primarily positioned for debugging and introspection during development, rather than for full production observability or interoperability.
Good for
- Cross-functional collaboration in development: Suitable for teams where not everyone writes code — Engineers, researchers, and PMs can all contribute directly.
- Prompt-centric development: Designed for early-stage prompt design, tuning, and experimentation.
- Rapid iteration cycles: Ideal for fast prompting and experiment loops with support for batch tests, AI-assisted diffing, and collaborative reviews.
- Shared evaluation backlogs: Provides a shared space for datasets and scoring rubrics, reducing the need for manual spreadsheet tracking.
- Eval artifact management: Managing eval artifacts in Brainstore, a purpose-built log database that keeps iteration history searchable.
Limitations
- Not designed for building agents: Braintrust is more focused on evaluation workflows than on observability and evaluation of multi-step execution agents.
- Agent tracing depth is limited: Multi-step agent runs involving tool calls often require external instrumentation to capture the full context.
- Shallow agent debugging experience: Agent tracing views are limited, making it challenging to follow reasoning chains or visualize tool call sequences during complex runs.
- Agent evaluation support: Evaluations for agents exist, yet coverage for dynamic, multi-turn tasks is narrow.
- Lightweight production monitoring for online evals: Observability features like monitors, dashboards, and alerting are less mature than its eval authoring tools.
- Regression response workflows lack a cohesive vision: No native concept of on-call readiness (e.g., playbooks, incident timelines) when evals flag regressions in production.
- Governance and compliance controls are still maturing: PII scrubbing, tenancy isolation, and audit logs are still on the roadmap, which keeps Braintrust squarely in the experimental lane.
- Limited vendor integrations: Braintrust lacks built-in integrations for inference gateways, ticketing, and notification systems.
LangFuse
Lightweight, open source tracing based on OTel, suitable for teams managing their infrastructure independently without needing enterprise-level governance or support.
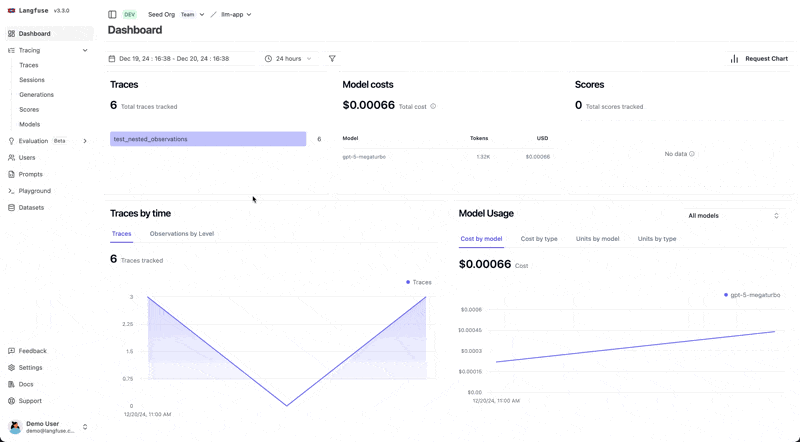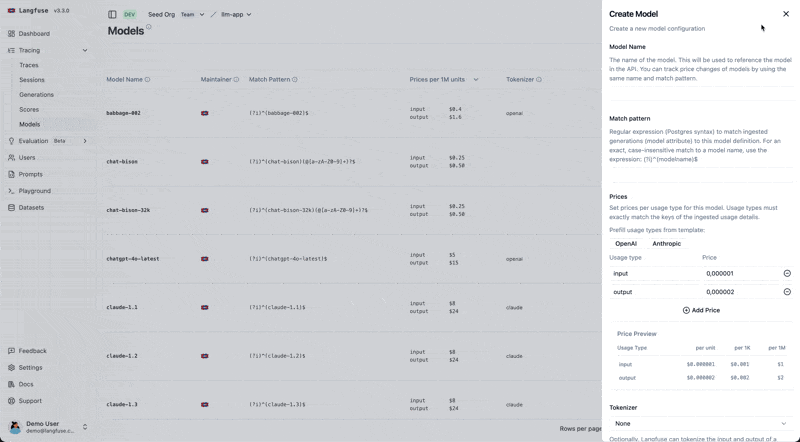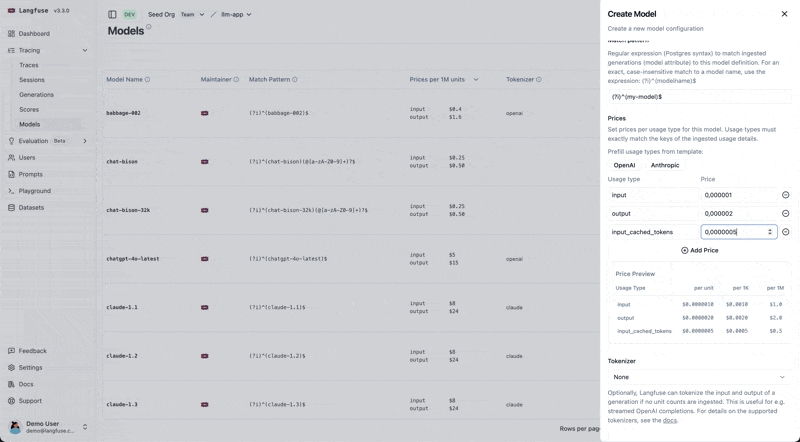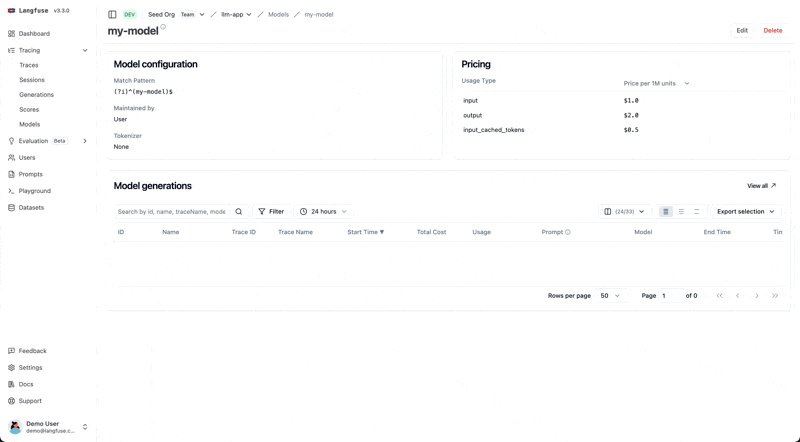
Instrumentation with LangFuse
Langfuse provides a native OTel instrumentation path, making it easy to bring tracing data into Langfuse. Its open-source SDK automatically converts emitted telemetry into observations, keeping your data portable while still unlocking LLM-specific tracing features.
Instrumentation is straightforward: initialize the Langfuse SDK, register Langfuse as a processor, and instrument your application with a function decorator.
# pip install langfuse
# .env config
LANGFUSE_SECRET_KEY = "..."
LANGFUSE_PUBLIC_KEY = "..."
LANGFUSE_HOST = "https://cloud.langfuse.com"
Once your environment is configured, you can start tracing any function using the @observe decorator. It automatically captures inputs, outputs, and timings.
from langfuse import observe, get_client
@observe
def my_function():
return "Hello, world!" # Input/output and timings are automatically captured
my_function()
# Flush events in short-lived applications
langfuse = get_client()
langfuse.flush()
Good for
- Smaller teams with open source DNA: Teams that want an open-source observability stack with multi-modal trace support, cost tracking, and agent graphs out of the box.
- Infra-savvy teams: Teams that are good at managing their own infrastructure.
- Straightforward pipeline integration: OTel-compatible ingestion makes it straightforward to slot Langfuse into existing pipelines.
- Collaborative agent debugging: Debugging agent flows for when you need to inspect tool usage and annotate failure cases collaboratively.
Limitations
- Limited enterprise readiness: Enterprise features like RBAC, audit logs, and compliance tooling are minimal or still in development.
- Community-first support model: Support comes mainly from the open-source community, with faster response times available through Langfuse paid plans.
- Scaling friction: As evaluation traffic grows, teams are limited by their ability to manage their own infrastructure effectively.
- No integrated AI automation: Langfuse is purely an observability and tracing platform with no built-in AI assistant.
- Early-stage evaluation automation: Automated evaluation workflows are still maturing, and you often need to pair Langfuse with external judge services to get comprehensive scoring.
- Ops workflows are left to you: Langfuse lacks native human-in-the-loop tooling (e.g., annotation queues, review dashboards), so ops teams build those layers themselves.
- Compliance handled externally: No built-in compliance tooling (e.g., masking, retention, GDPR workflows) means enterprises must build compliance guardrails typically provided by other managed platforms.
How to choose
Selecting the appropriate LLM evaluation platform is less about ticking boxes and more about how well it fits your team’s workflow. Some platforms are designed for scalability and reliability from the start, while others are geared toward open experimentation or a strong ecosystem focus.
Arize AX and Arize Phoenix share the same open foundations but serve different comfort levels. AX for managed enterprise scale, Phoenix for teams that value open-source control.
LangSmith keeps everything tightly integrated inside the LangChain ecosystem, making it ideal for rapid prototyping and smaller dev loops.
Braintrust targets teams engaged in early-stage experimentation and collaborative prompt design, while Langfuse appeals to infrastructure-savvy teams seeking to build and control their observability stack from the ground up.
Regardless of stack, Hamel’s warning still applies: evals only earn trust when they mirror human judgment and stay wired into observability. Each of these platforms can help you measure, test, and trust your agents, but the best choice is the one that best fits your team’s structure and workflow.
FAQ
What platform to choose to set up end-to-end LLM evaluation framework now?
Start with Arize AX for managed scale and access to its built-in AI assistant, Alyx. Or, choose Arize Phoenix if you prefer OSS control with a happy path to AX later.
What evals framework is best to use for LangChain?
LangSmith keeps everything in one canvas, provided you accept the ecosystem lock-in. If lock-in is a concern, go with Arize AX for a neutral eval and observability platform.
Which LLM evaluation platform is best for shipping fast internal tools with heavy prompt churn?
Braintrust and Arize AX give you opinionated workflows for experimentation.
Which platform best helps you stand up an LLM evaluation framework in-house?
Arize Phoenix is a strong OSS baseline; bring your own eval judges and review process until the feature set matures.