


Resource Hub

Mean Absolute Percentage Error (MAPE): What You Need To Know
What Is Mean Absolute Percentage Error? One of the most common metrics of model prediction accuracy, mean absolute percentage error (MAPE) is the percentage equivalent of mean absolute error (MAE). Mean...

Why AI token costs don’t tell you if your AI is working
Token spend does not prove AI is creating value. Teams need cost-per-outcome metrics that connect AI usage to resolved tickets, accepted code, shipped features, and other business results.
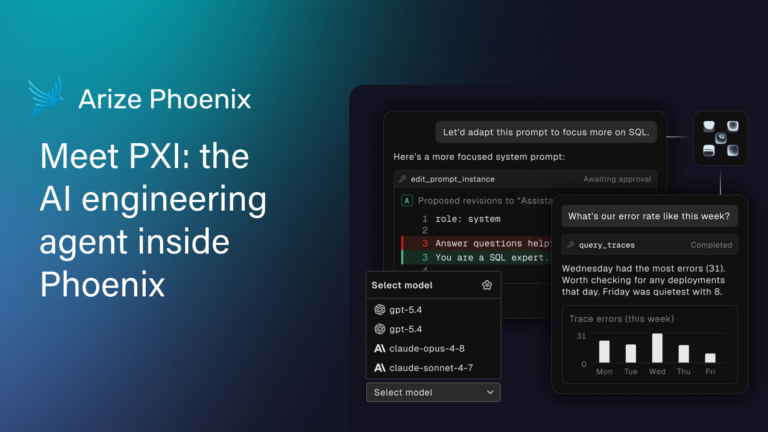
Meet PXI: the AI engineering agent inside Phoenix
An AI engineering agent built into Phoenix. It works like a coding agent, just point it at your telemetry instead of a source tree.
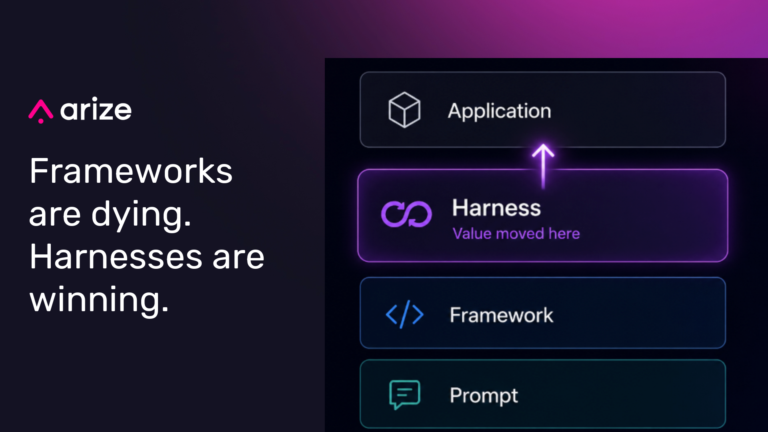
What is an agent harness? Why harnesses are replacing agent frameworks
Agent harnesses are replacing frameworks as the real product surface for reliable AI agents, shifting the work from prompt tuning to loops, tools, traces, evals, and operational metrics.

Two labs started dreaming, and they built two different architectures
Anthropic and OpenAI both shipped 'dreaming' for AI memory in May and June 2026, and they built opposite architectures. A look at what each lab shipped, what the empirical literature says, and what to do if you are building memory for your own agent.

What is agent orchestration? Frameworks, runtimes, and observability explained
Agent orchestration is not one problem. It spans expression, runtime, and observability, and separating those layers clarifies how teams should build, run, and improve production agents.

One agent, two trace destinations: Arize AX + Databricks Unity Catalog
Send one OpenTelemetry trace stream to both Arize AX and Databricks Unity Catalog so engineers can debug agents in Arize while data teams analyze the same spans in governed lakehouse storage.

Memory is still a missing primitive: Cataloguing what the field is actually shipping
This week the field shipped four kinds of memory, and Apple paid Google a billion dollars a year for one of them. None of the four is what the demos imply. A field map of what's actually shipping, and the missing primitive that sits between the buckets.
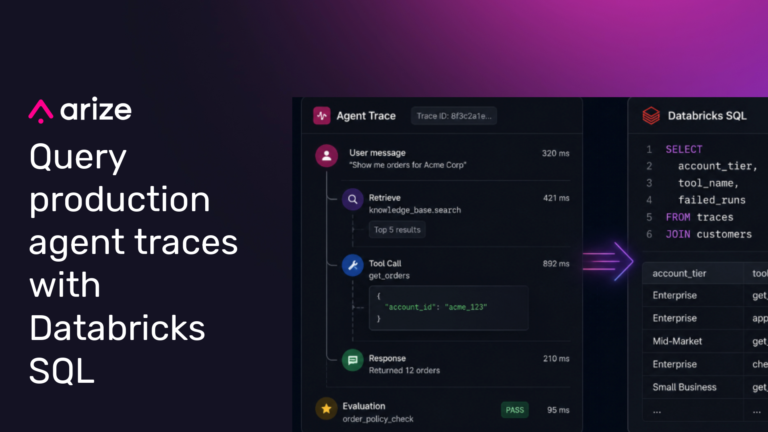
Bring production agent traces from Arize into Databricks Unity Catalog
Arize Data Fabric now supports Databricks, helping teams sync production agent traces, evaluations, and annotations into customer-owned storage for governed analysis in Unity Catalog.
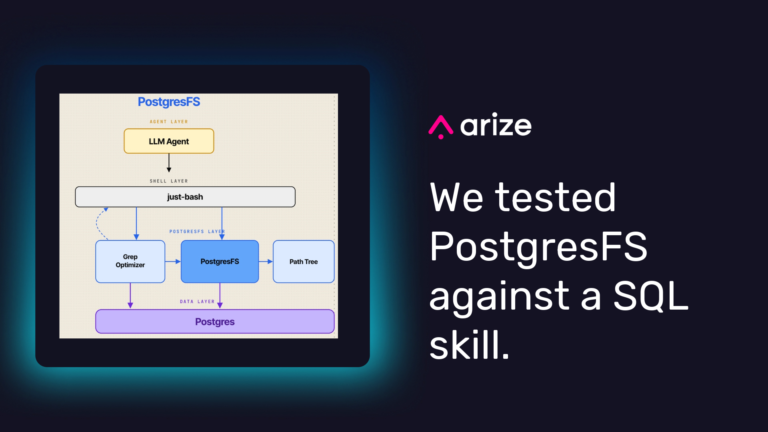
PostgresFS vs. SQL skills: should AI agents fake a filesystem?
Can an AI agent use a database as if it were a filesystem? Arize compared a Postgres-backed filesystem abstraction with a SQL skill and found that locality, accuracy, and maintenance cost favored the skill-based approach.
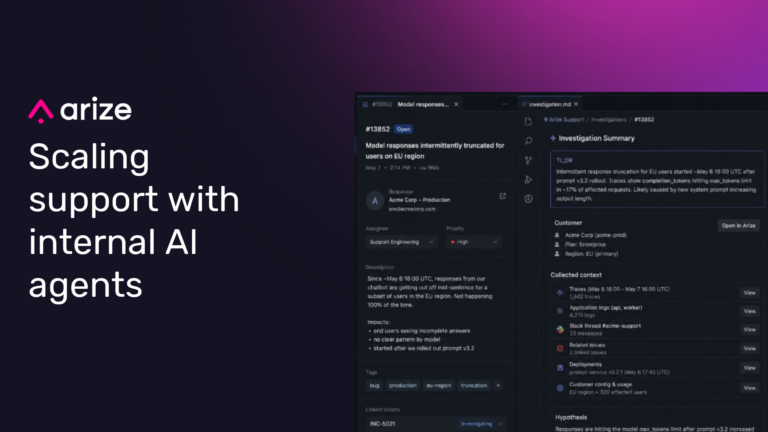
How Arize built AI-native support workflows that cut resolution time in half
Arize reduced median support resolution time from 22 hours to roughly 2.5 hours by building AI-native internal workflows for context gathering, debugging, escalation, and continuous improvement.

How to detect credential theft in AI agent harness traces
In May 2026, a malicious version of a popular VS Code extension spent 18 minutes in the marketplace before anyone caught it. In that time it ran on roughly 6,000...
No results found. Try a different filter or search term.