


Twitter said pick a side. The eval said the question was wrong.
Six months ago, MCP (model context protocol) was the hot new thing: tool usage with a built-in discovery mechanism. Everyone was building MCP servers. Then Anthropic, who invented MCP, launched Claude Skills, and the discourse turned. Simon Willison, the co-creator of the Django Web framework, called skills “maybe a bigger deal than MCP.” A blog post titled “MCP is dead, long live the CLI” sat on the front page of Hacker News for two days. Pieter Levels piled on: “MCP is dead, just as useless of an idea as LLMs.txt was.”
The argument is simple. LLMs already know how to use CLIs. Give them a shell and some docs, stop building servers, stop writing schemas. Just let them type commands.
That is a vibes-based debate. We wanted evidence, so we ran an evaluation.
The experiment
We took one model, Claude Opus 4.6, and gave it a set of GitHub tasks using the Claude Agent SDK, the same harness that powers Claude Code. Same agent, same tasks, same repo. The only thing that changed was how the agent learned about its tools.
We picked GitHub deliberately since lots of people use it. GitHub has a mature official MCP server, a reference-quality implementation. GitHub also has gh, a legitimately great CLI. Both sides of the debate get their best shot.
To have something to test against without breaking anything that mattered, we built a fake Python SDK called acme-sdk-python and pushed it to GitHub. We populated it with 12 open issues with realistic labels, three pull requests in different review states, milestones, comments, and assignees. The code was fake. The state of the repo was real.
A fun aside: we initially made the repo public. Within hours, some random person’s GitHub agent showed up, saw an issue marked “good first issue,” and started submitting PRs trying to fix our completely fake code. Our tests blew up because the state of the repo kept changing under us. We made the repo private. But at least we know it looked convincingly real.
We wrote 25 tasks across four tiers of difficulty:
- Tier 1. Trivial reads. “How many open bugs are there?”
- Tier 2. Harder reads. “List all bugs and tell me which have a linked PR.”
- Tier 3. Writes. “Create an issue. Fix a typo via branch and PR. Add a label.”
- Tier 4. Complex analysis. “For each milestone, report completion percentage. Find all multi-label issues and tell me the most common pairing.”
Then we wired up three arms of the experiment:
- MCP. The agent gets the official GitHub MCP server and is firmly instructed to use it.
- LobeHub skill. A skill we pulled from the popular LobeHub marketplace. Encyclopedic. 2,187 lines of markdown covering every
ghcommand and flag, organized like a man page. - Vault skill. A different skill from Claude Skills Vault. 341 lines, six times shorter. Opinionated and prescriptive. Sorts every
ghcommand into four safety tiers: safe, write, destructive, forbidden.
Same coding agent, same base system prompt, same 25-turn budget, same model. The only thing that changes is the tooling instructions.
We ran each arm against each task five times. 500 trials total, all logged to Arize.
The metrics
We tracked five things:
- Correctness is LLM-as-judge: we wrote down the real answer for every task and the judge compared the agent’s output to ground truth.
- Output quality is also LLM-as-judge: was the final response well-formatted and useful?
- Latency is wall-clock time.
- Cost is total tokens used, which Arize gives us for free from the trace data.
- Tool fidelity is the fraction of calls that stayed inside the allowed list for that arm: MCP tools for the MCP arm, bash and file tools for the skills arms.
One of the great things about LLM-as-judge evals is that every score comes with an explanation field. So every test came with a little buddy who watched what happened and wrote it down. We could read those explanations and understand exactly why the agent failed when it failed. That turned out to matter a lot.
The headline result: everyone gets there eventually
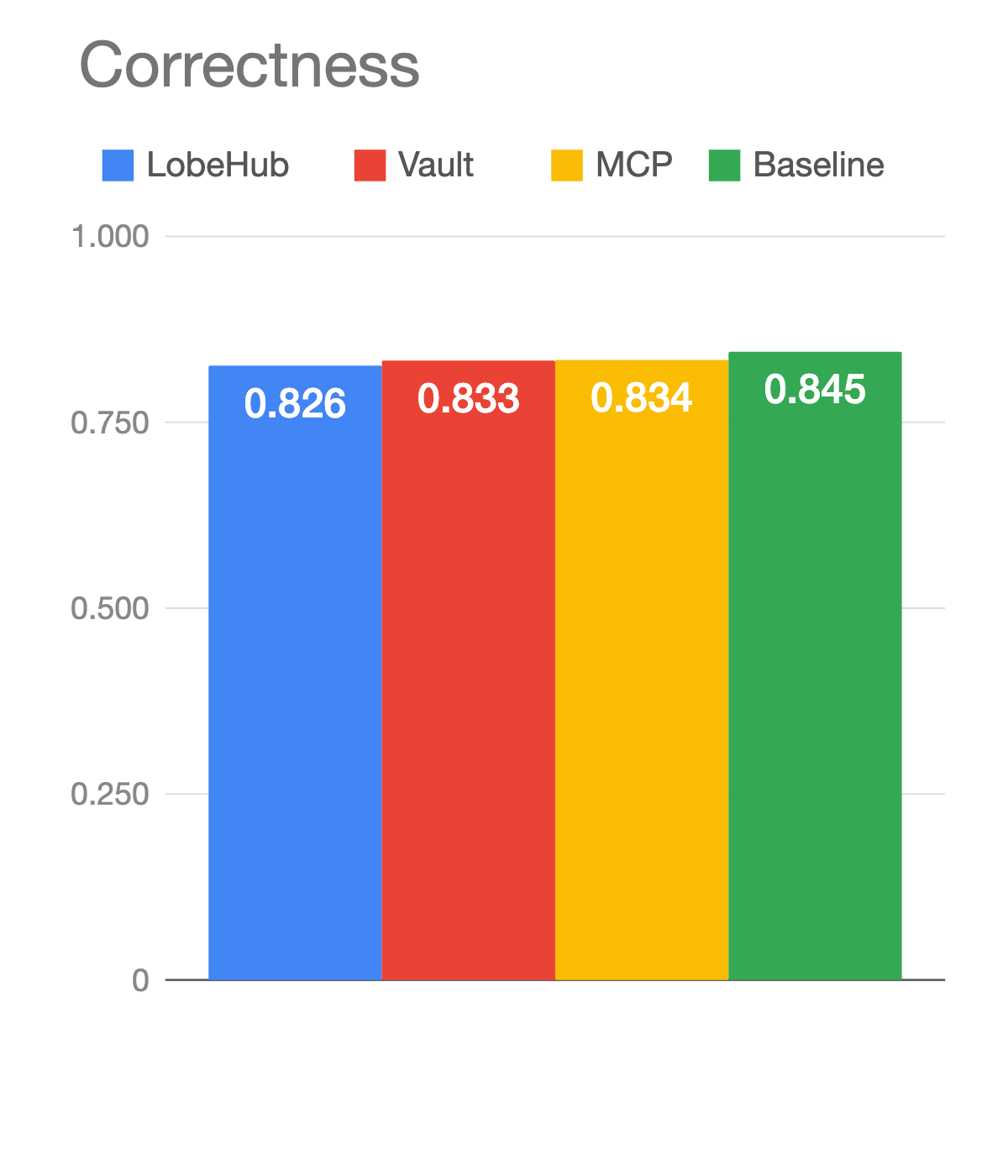
Correctness lands in a tight band. LobeHub 0.826, Vault 0.833, MCP 0.834. Tiers 1 and 2 were 100% across the board. The misses concentrate in tier 3, the writes, which turned out to be trickier than tier 4 even though we’d expected the opposite.
The takeaway from this chart alone: it doesn’t really matter which approach you pick. Your agent will get the answer. But “eventually” hides a lot.
Latency and cost tell a different story
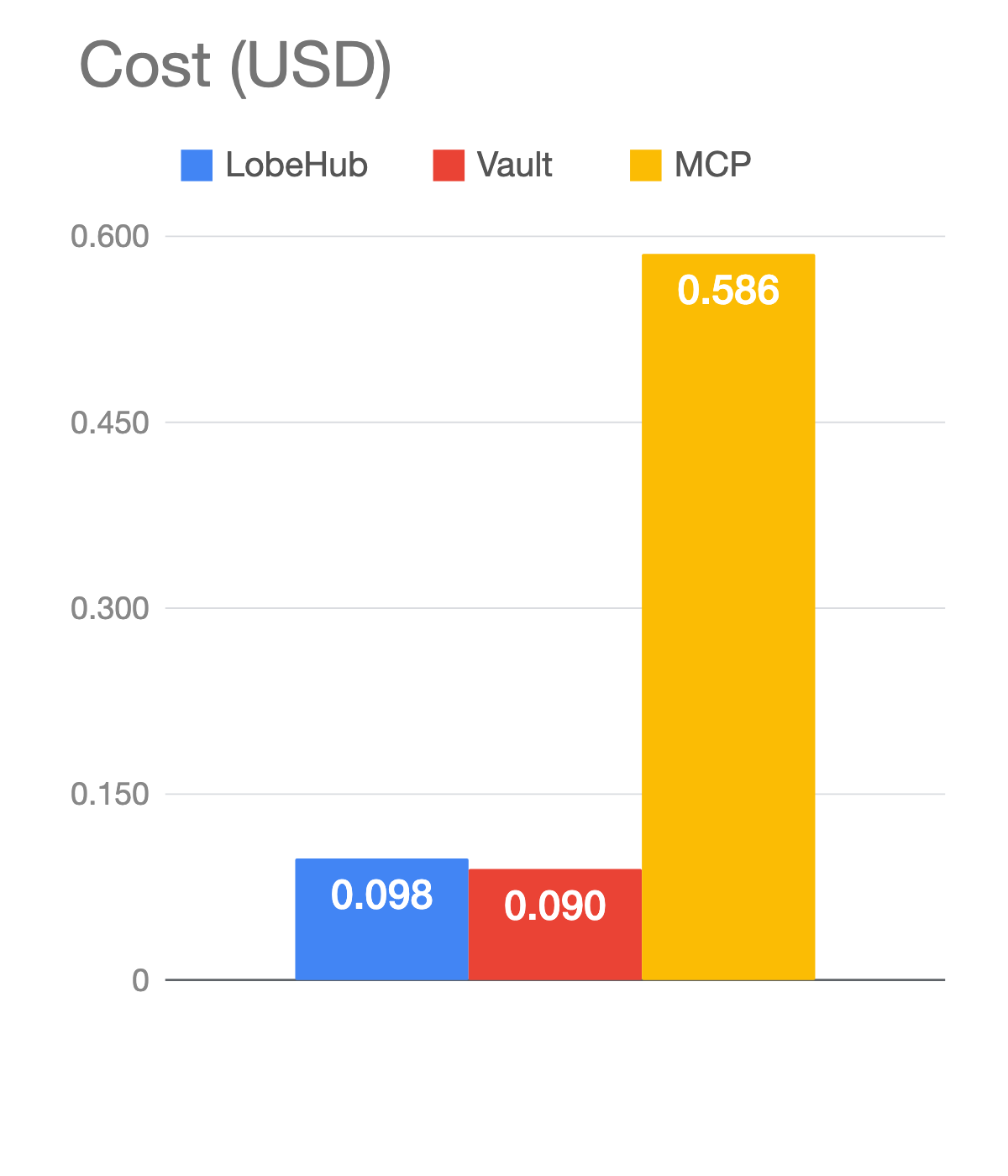
On the hardest tier, MCP cost more than six times what the skills cost and took five times longer. On average, MCP made about twelve tool calls per tier-4 task. The skills made five.
The reason is structural. The GitHub MCP server is a fixed API surface. When a task maps cleanly to one of its endpoints, it works perfectly. When it doesn’t, MCP can’t compose. There is no way in the API to “list all open and closed issues for milestone X, group by label, compute the most common pairing.” So MCP fans the task out into many calls. Each response comes back as verbose JSON. Bigger payloads mean more tokens. More turns mean the previous context comes back into the next call. The cost compounds.
The CLI doesn’t have that problem. Bash is Turing complete. gh plus jq plus pipes can compose. The skills arms used grep, sort, and uniq the way Claude Code does on a filesystem.
Tool fidelity: MCP escapes the tool boundary
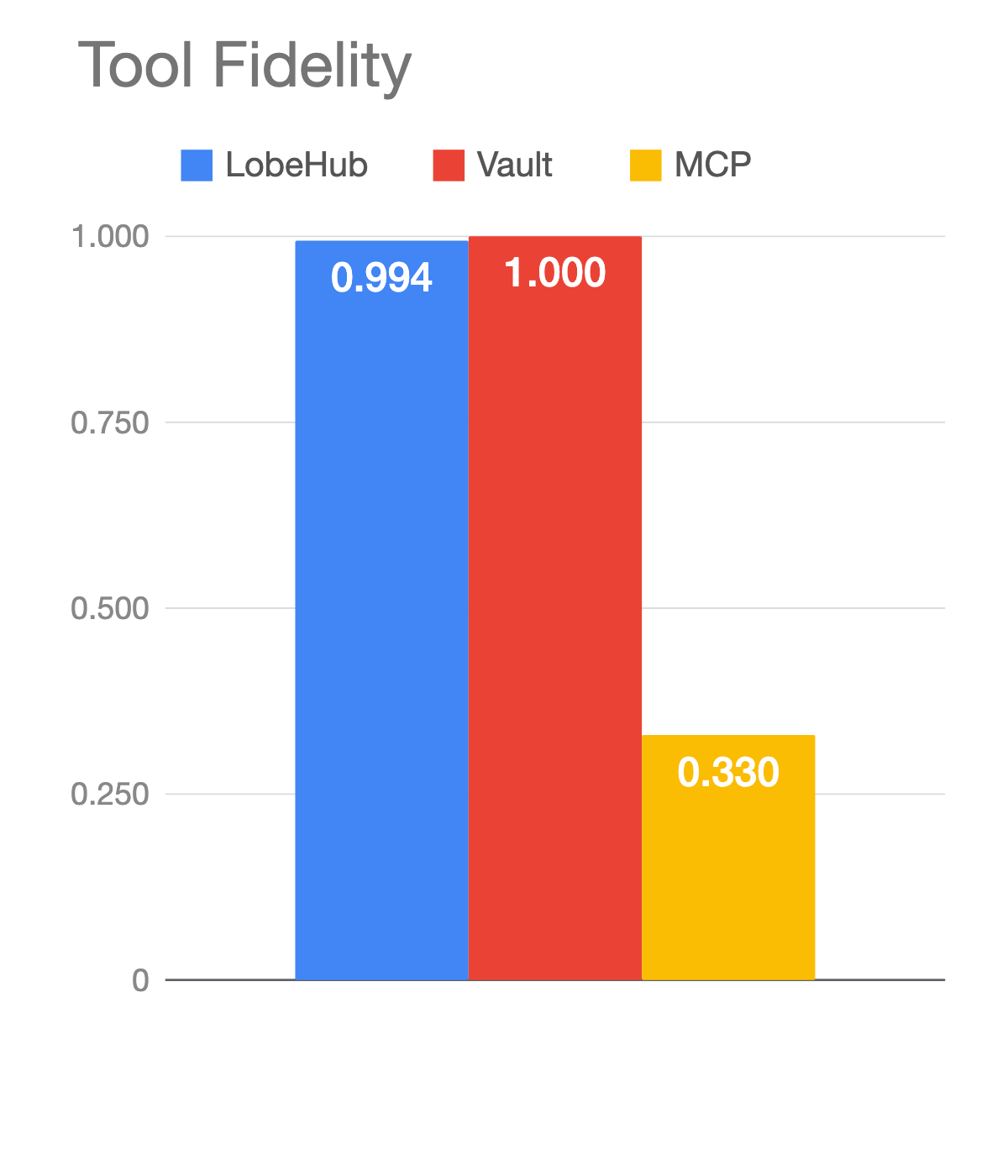
The skills stayed inside their allowed tools more than 99% of the time. MCP did not. Tool fidelity for MCP on tier 4 was 0.33.
The MCP agent was instructed to use only MCP tools. It ignored the instruction. When the API surface couldn’t compose, the agent gave up and shelled out to bash to parse the JSON files it had written to disk. We anticipated this, which is why we measured for it. From a practical standpoint it doesn’t matter much: if your MCP-powered agent uses bash sometimes, you don’t really care. But it tells you something about what the API surface couldn’t do on its own.
A representative tier-4 vignette: task 22 asked the agent to find issues open and closed in the same milestone and compute the average time-to-close. Vault solved it in seven tool calls, under a minute, 19 cents. MCP on its worst run took 71 tool calls, eight minutes of wall-clock time, and burned two dollars. Only three of those 71 calls were actually MCP. The rest was bash parsing JSON.
But task 13 went the other way. “Create a branch and open a pull request.” MCP averaged eight tool calls in 33 seconds, about 16 cents. LobeHub averaged 22 calls, nearly a minute and a half, 50 cents. When the task maps cleanly to MCP tools, MCP wins. create_branch and create_pull_request exist as endpoints. The CLI has to do more steps to get there.
The shape of the task determines the winner.
Then we added a fourth arm
We had a strong conclusion: Skills win out over MCP. We were ready to ship. Then we asked an obvious question and reluctantly realized we had to redo a lot of analysis: what happens if we don’t use a skill at all?
GitHub’s CLI is famous. The gh command is documented across thousands of webpages, tutorials, and Stack Overflow answers. The model has seen all of it during pretraining. So we ran a fourth arm: bare Claude with a generic system prompt, no MCP, no skill, just permission to run shell commands.
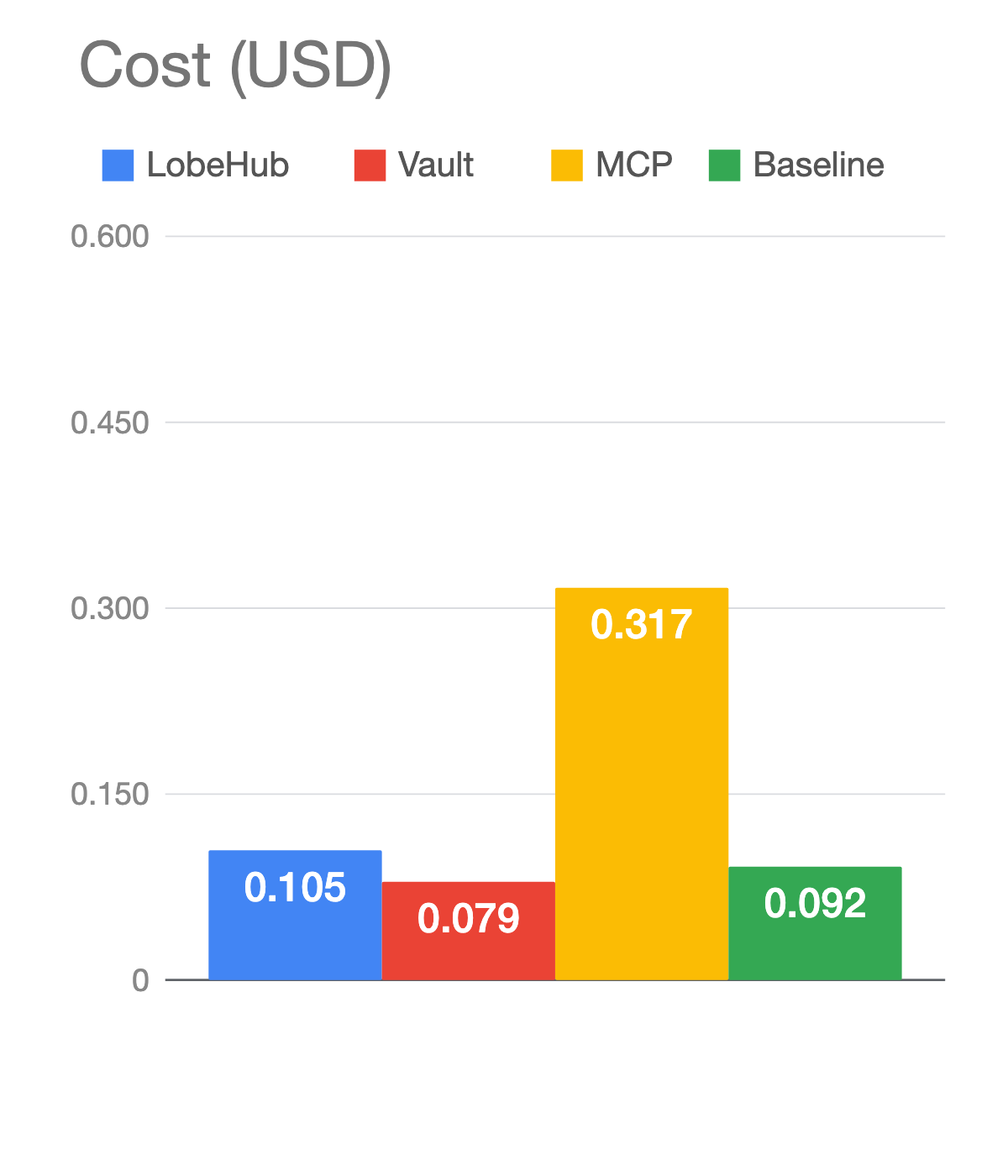
Baseline Claude is barely behind the skills. On correctness it actually scored slightly higher, 0.845 versus 0.833. The reason is mildly funny: the Vault skill told the agent to be careful with destructive commands and pause for permission, while bare Claude just ran commands without waiting. Faster and more correct, with a security trade-off the skill was deliberately making.
On cost and latency, the skills still beat the baseline. The Vault skill cost less than baseline because it taught the agent to use commands more efficiently. The verbose LobeHub skill burned slightly more tokens because it was, well, verbose. So skill quality matters. A short opinionated skill beats a long encyclopedic one. But for gh, the training data is doing most of the work.
This is the part you should worry about for your own systems. Your company’s CLI is not as famous as GitHub’s. The model hasn’t seen it. The training data isn’t doing the work for you. You will need a skill or you will need MCP. Or you will need to give up.
What complicates the picture
The headline numbers are real. MCP is six times more expensive on hard analysis tasks. Skills work, especially short ones. But three things complicate the story before you go off and rip out your MCP servers.
- The GitHub MCP is a thin REST wrapper. It’s not the only shape an MCP server can take. MCP is a rich protocol. A server can expose tools, resources, and prompts. More importantly, an MCP server can have an entire agent behind it. Instead of “list issues by milestone” being a fixed endpoint, the tool could be “ask me to find and filter issues for you” with another agent on the other side doing the composition. That MCP server would not have lost this benchmark. The GitHub MCP isn’t built that way, but yours could be.
- CLIs are developer tools. GitHub is a developer tool, so that’s fine. The average GitHub user can generate an API token and pass it to
gh. But agents in 2026 are a regular consumer product. The average ChatGPT or Claude user is not going to install a CLI, generate a personal access token, and paste it into a config file. Your agent isn’t going to figure that out for them either. Auth is wildly inconsistent across CLIs and access control is usually thin. MCP uses OAuth. Anthropic extended the OAuth spec so MCP could do everything it needs. The result is genuinely better: paste a URL, click through a browser consent screen, done. That moves MCP from a developer tool to a consumer protocol. - Enterprise control. OAuth lets administrators control who and what gets access to which resources. CLI auth usually does not. If you’re shipping agents to customers inside an enterprise, this matters more than the cost-per-call delta.
Use both
After all this, the right framing isn’t MCP versus the command line. It’s MCP plus the command line. Real agents use both. Claude Code uses both. Cursor uses both. Yours probably should, too.
Use the CLI when you’re working locally, when the tool has decades of training data behind it, when auth is pre-configured, and when you benefit from piping things together. This is the case where you are automating your own workflow.
Use MCP when the tool is remote, when it’s proprietary and not in the training data, when you need OAuth, when there’s real state to manage across steps, or when you want to hide an entire agent behind what looks like a simple tool call. This is the case where you are shipping software to customers.
Our headline findings hold. MCP collapses on open-ended analysis when it’s used as a thin REST wrapper. A short opinionated skill beats a long encyclopedic one. For a popular CLI, the training data is doing most of the work. But MCP isn’t dead. It’s the right answer for a different set of problems than skills are.
The eval did what evals are supposed to do. It showed us the limits of our original question. The Twitter debate said pick a side. Five hundred runs said the question was wrong.
The code, the tasks, and the data are open source on GitHub.