

Memory in LLM applications is a broad and often misunderstood concept. In this blog, I’ll break down what memory really means, how it relates to state management, and how different approaches—like session-based memory versus long-term persistence—affect performance, cost, and user experience.
Defining “Memory”
The term “memory” is often used in discussions about LLM applications, but it’s an abstraction that can mean different things to different people. Broadly, memory refers to any mechanism by which an LLM application stores and retrieves information for future use. This can encompass state in its many forms:
- Persisted state: Data stored in external databases or other durable storage systems
- In-application state: Information retained only during the active session, which disappears when the application restarts.
Lots of people use the word “memory” without defining it, so take it with a grain of salt when someone uses it (including this article).
What is State in LLM Applications?
State is the mechanism which a system retains and uses information over time, connecting past interactions to current behavior. In software engineering, state can be categorized into two main types:
- Stateful systems retain context
- Stateless systems treat each interaction independently, with no memory of prior exchanges.
LLM models are stateless. They process each query as a standalone task, generating outputs based solely on the current input. This simplifies model architecture but poses challenges for LLM applications that require context continuity.
For example, in a chatbot, messages within the same session may appear stateful, as they influence ongoing interactions. However, once the session ends, the application reverts to a stateless design, if there is no information persisted across sessions.
Why Managing Memory & State is Essential
Applications require state to deliver consistent, coherent, and efficient user experiences. Without it:
- Users are forced to repeat information
- Applications can’t adapt to ongoing context
- Processing redundant information increases costs
Managing state requires balancing the things you need, and the things you don’t for the particular LLM application. For applications needing long-term context, such as personalized workflows or multi-session tasks, persisted state is essential. For simpler or transient interactions, lightweight in-memory state might be good enough.
How to Choose the Best Strategy
First, a disclaimer: The best way to manage state in an LLM application depends on your specific use case. Different applications require different approaches to state and memory, ranging from transient session-based contexts to long-term persisted data. Choosing the right strategy starts with understanding your actual requirements and balancing trade-offs effectively.
Parameters for Memory
When deciding the larger parameters for memory, it’s a lot like human memory:
- How Much to Remember – Amount of Information: Context windows, cost, scalability for state management might be factors to consider
- What to Remember – Importance: Not always binary, could include systems of importance (special entities / memory variables, most recent vs most relevant, or a hierarchy of state, etc. – all which we’ll get to later)
Generally the two big ideas above are good abstractions to think about how memory can be broken down. Theoretically, you would either just remember everything, or remember all important things and nothing else, and that could solve any issue, but of course, the real world is going to be some optimal combination of the two.
LLM State Management Considerations
Below are more tangible ways to think about state in LLM applications state management mechanics, and how they might affect how that system works
The Context in Which State Should be Carried
The context in which state should be carried will affect the design of your state management system, illustrative examples below.
End User Examples:
- State Across Messages: Maintains continuity during an ongoing session but resets once the session ends. Useful for chatbots, iterative problem-solving, or workflows.
- State Across Sessions: Persists information across sessions, enabling personalization or long-term task tracking. Essential for applications like virtual assistants or collaborative tools.
Agent Examples:
- State Across Tool Calls: Does each tool execution need to carry over context, or can the tools operate independently?
- State Across Multiple Agents: In multi-agent systems, should agents share state, or should they operate with isolated knowledge?
LLM Model Context Window
LLMs have a fixed context window, limiting how much information they can process at once. As the input grows, performance can degrade, costs increase, and hallucinations become more frequent. State management strategies must account for these limitations to ensure relevance without exceeding token context windows.
Costs
Stateful designs often improve user experience and application performance but come with increased costs. Persisted data and larger prompts increase storage and processing demands. Balancing the cost of maintaining state against its benefits is critical for sustainable applications.
LLM Application Performance
Depending on the outcome you are trying to produce, some folks might need more complex state management to actually achieve the outcome they desire while others can implement something more simple and still achieve their required results. Some can go with a more brute force approach while others might need to refine the state system.
Basic Ideas: Managing Context
Excessive state leads to inefficiencies and irrelevance, while insufficient state disrupts continuity and user satisfaction. A complex state management system can cost a lot of upfront development work and may increase complexity, while a simpler state management might increase model costs and reduce performance.
A thoughtful approach selectively retains what’s most important while discarding what’s unnecessary. There is no right or wrong answer here as this is very much application dependent. There are pros/cons like all engineering decisions.
The below is by no means an exhaustive list, mainly an idea of common ideas of how context might be managed. There are many implementations of the below, with varying outcomes depending on the implementation details.
Conversation History
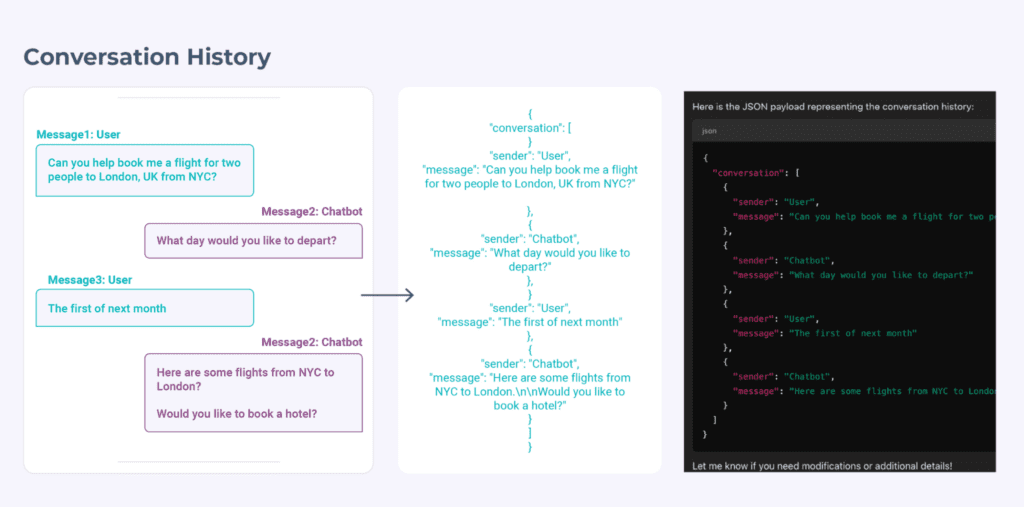
Conversation history involves including all past messages—user inputs and model outputs—in subsequent prompts. While straightforward and intuitive, this method quickly runs into problems:
- Degraded performance: Large prompts reduce model quality.
- High costs: Token usage grows quadratically with conversation length.
- Context limits: Long histories can exceed the model’s capacity.
This approach works for short interactions but scales poorly in more complex applications.
Sliding Window
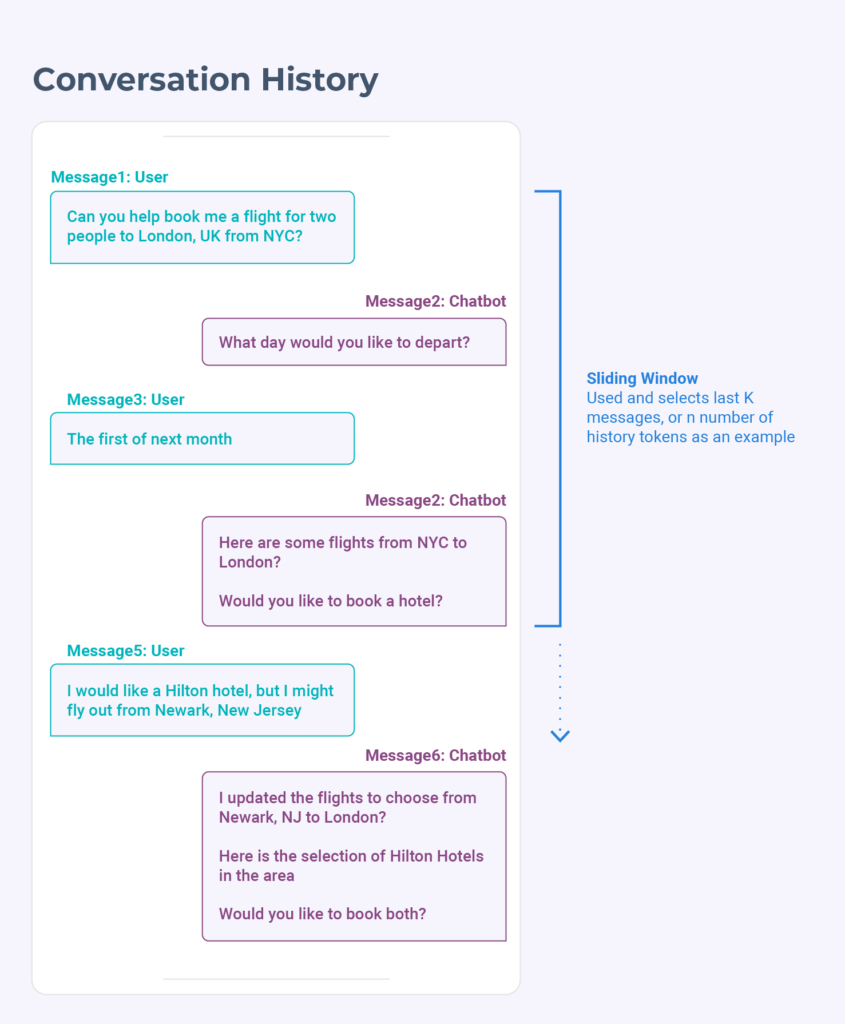
A sliding window retains only the most recent messages, discarding older ones to maintain a fixed context size.
- Benefits: Keeps context relevant, stays within model limits, and controls token costs.
- Drawbacks: Risks losing important earlier details and struggles with long-term dependencies.
Sliding windows balance efficiency and relevance but may require supplementation for applications needing deeper context.
Combining Strategies
Blending approaches, such as combining recent message windows with past summaries, offers a practical balance. This ensures recent context is preserved while retaining essential historical information.
These foundational techniques provide a starting point for managing state effectively, tailored to the specific needs of your application.
Storage Types
Choosing the right storage type depends on the persistence requirements, cost, and latency of your application. Here’s an example below
Ephemeral conversation history
- Temporarily stored in application memory, used during a single session. For example, a shopping assistant might track interactions in real time without needing to persist data for future sessions.
Persistent conversation history
- Stored in a durable database or vector store, enabling access to prior context across sessions. This is essential for applications like personal assistants that need long-term memory for personalization.
- The persistence storage medium—whether a database, blob storage, knowledge graph, or retrieval-augmented generation (RAG) system—should align with your application’s complexity, latency requirements, and cost constraints.
Advanced State Management
Tiering Memory
Not all information is equally valuable. Tiering memory helps prioritize what to retain and for how long. Here are some examples with different kinds of data:
- High-priority data: Critical user inputs, such as preferences or details likely to impact future queries (e.g., a shopper’s size in a clothing app).
- Medium-priority data: Summarized responses or intermediate results that help maintain context but aren’t essential.
- Low-priority data: Temporary or large outputs from tooling calls that are unlikely to be reused.
Balancing between how much and how important the state is, can help guide users when to prune and when not to prune this data. This approach ensures that the most relevant data is preserved while managing storage and retrieval costs effectively.
Specialized Entities/Memory Variables
Domain-specific applications benefit from storing structured entities as discrete memory variables. The idea is that you may know certain fields or entities that will likely be important for your application, so you would preemptively search and store them in the state system.
For example:
- A travel assistant could retain destinations, travel dates, budgets, and hobbies as specialized fields, enabling it to respond contextually (e.g., “Can I ski during my trip?”).
- An e-commerce chatbot might extract and save product preferences or delivery details for reuse later in the conversation.
By focusing on relevancy weighting, specialized entities streamline how applications process and retrieve meaningful data consistently used in that domain or workflow.
Semantic Switches
When a conversation shifts topics, the associated memory or state must adapt. For example:
- In an e-commerce chatbot, if the user switches from discussing a specific product to a different one, injecting irrelevant details about the first product could confuse workflows.
- Semantic switches can help applications detect when context has changed, ensuring the system responds appropriately without overloading the state.
More Dynamic Write and Reads of State
Advanced state management separates active memory (used during interactions) from external memory (stored for retrieval). This enables scalable, efficient, and adaptive applications.
- Smart Write: Automatically adds key external data into the LLM’s active context.
- Smart Reading: Retrieves specific data on demand, keeping the context lightweight.
Memory hierarchies organize data into:
- Core memory: Actively used information in the current interaction.
- Archival memory: Persistent storage for long-term or less critical data.
Effective systems prioritize relevance, refine stored data over time, and balance retrieval strategies to optimize performance and cost.
More advanced frameworks like Letta are actively developing these systems.
Evaluating State Management
Effectively evaluating state management is essential for understanding and improving how state and memory impact LLM application performance. Here are some approaches to consider:
Evals for State and Memory Performance
Use methods such as running LLMs as judges, incorporating human annotations, or leveraging logic-based evaluations to assess tasks that depend on state payloads, structures, or entities.
Measure Persisted State Usage
- Evaluate how often persisted state is accessed to identify unused or unnecessary state.
- Consider implementing a time-to-live (TTL) mechanism to remove stale or unused state data.
- Measure and address inefficiencies where state is stored but rarely used, refining the system as needed.
Component-Level State Evaluation
- Assess individual components within the larger application to identify where state management can be improved.
- Recognize that some components may require nuanced state handling rather than an all-or-nothing approach.
- Focus on refining state management for specific parts of the application that rely heavily on state to enhance the overall system.
State management in complex LLM applications is rarely straightforward. By measuring and refining how state is accessed, maintained, and optimized across different components, you can ensure that your system balances performance, cost, and scalability.
State in Different Agent Architectures
Here are some illustrative examples of how state might be handled in various architectures. These are just ideas to consider and are not meant to be definitive or correct solutions.
Augmented LLM
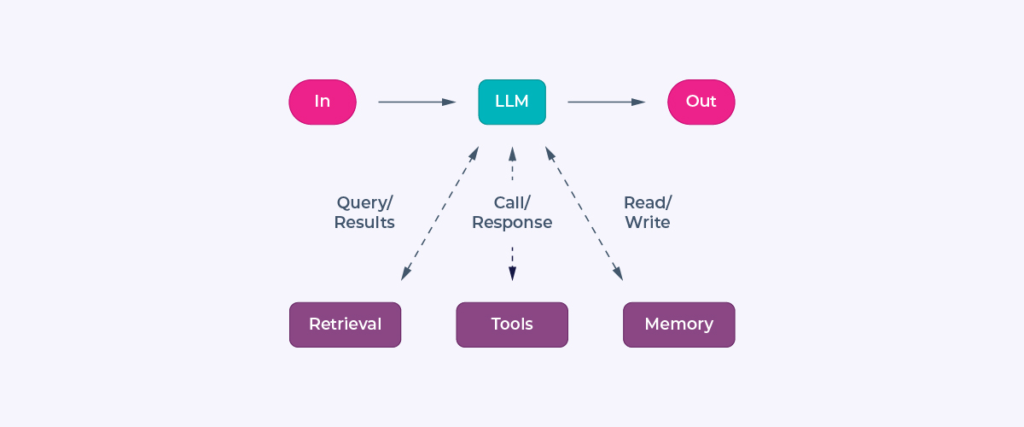
In a simple standalone system like an Augmented LLM with tool calling or RAG, state can be maintained by appending user inputs and application outputs to a conversation payload. If the context window is exceeded, long RAG contexts or tool call results can be summarized. Combining a sliding window approach with summarization helps retain only the most relevant recent interactions, ensuring continuity without exceeding system capacity.
If state needs to be shared across a session, you can persist and manage it; otherwise, state may not be necessary for simpler, transient interactions.
Prompt Chaining
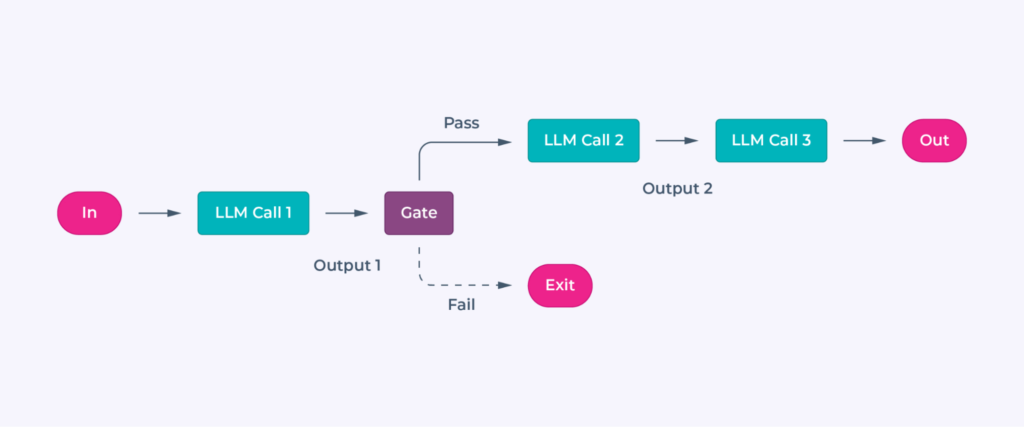
State flows between steps as outputs from one prompt feed into the next. Summarized or structured data helps retain context across steps while keeping prompts efficient and focused. This workflow is simple which also might make the state management also simple.
Routing
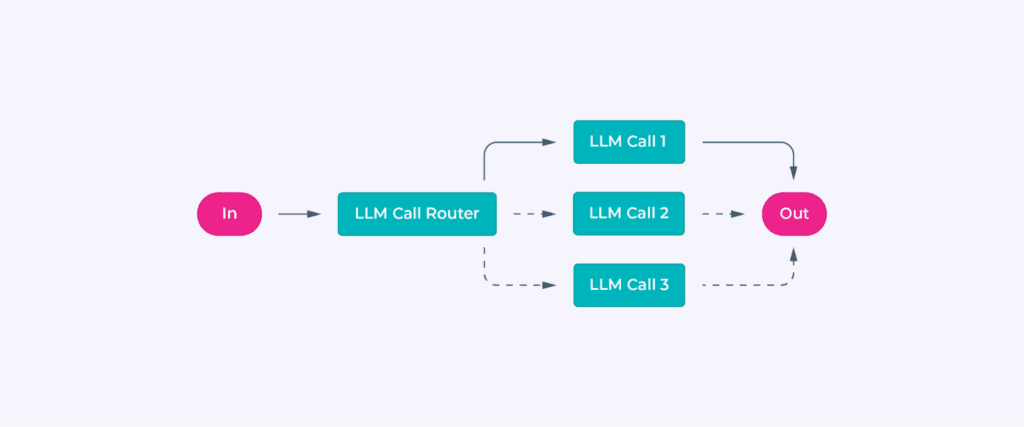
State could track classification decisions, ensuring inputs are directed to the right task or model. Persistent storage can log routing history for analysis or future optimization.
Parallelization
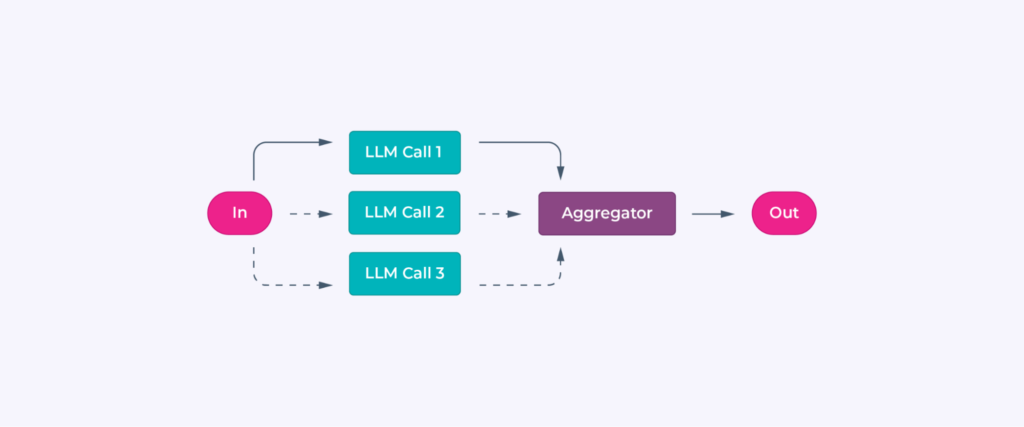
State is split across subtasks, with results temporarily stored and programmatically merged. For voting workflows, outputs from multiple attempts are aggregated to ensure reliability.
Orchestrator-Workers
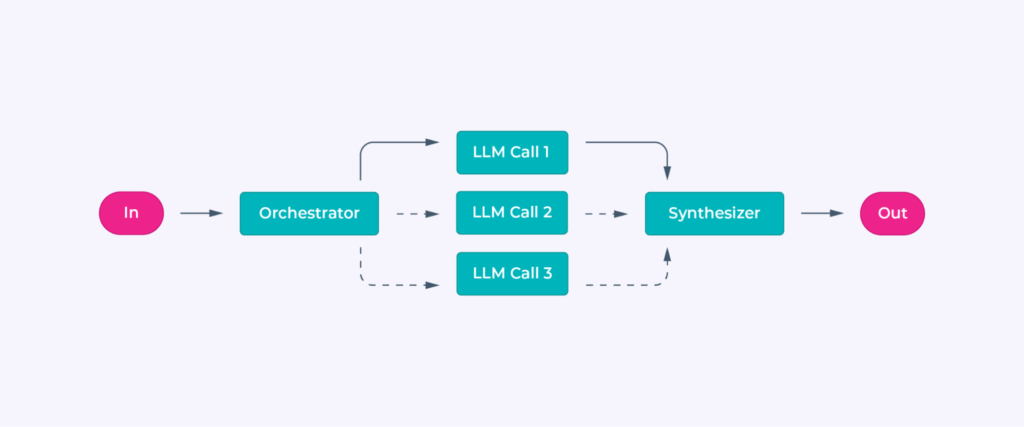
The orchestrator dynamically tracks the task’s progress and coordinates workers. It retains state by logging subtasks and results, enabling flexible handling of complex or unpredictable workflows.
Evaluator-Optimizer
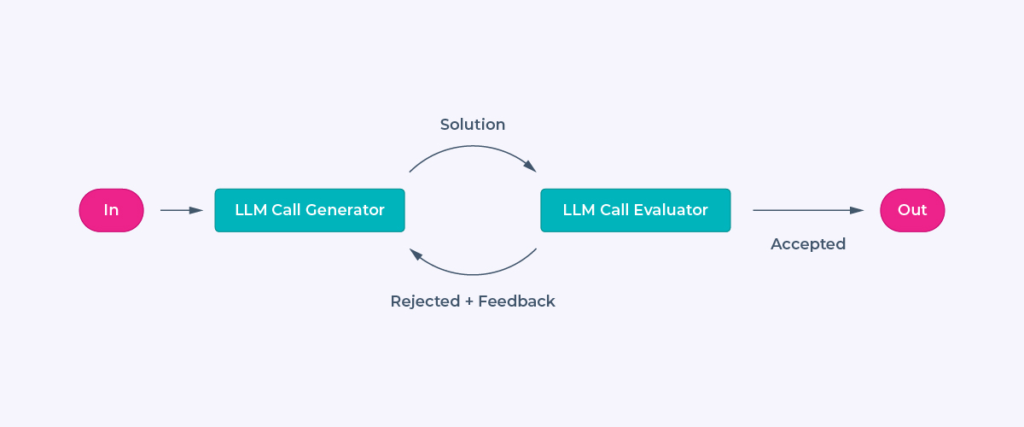
State is updated iteratively as the evaluator refines outputs. Feedback and prior iterations are stored to guide the optimizer toward improved results.
Agents
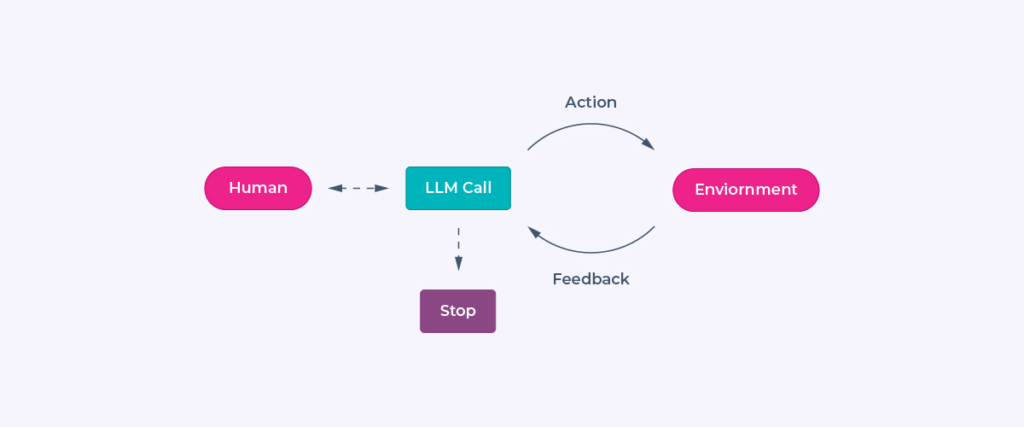
State includes task progress, tool usage, and environmental feedback, maintained persistently or temporarily based on the task’s scope. Agents use this state to adjust plans and ensure continuity over multiple steps.
Looking Ahead: What is the State of State?
For Arize customers and the Arize AI Copilot we built, we’ve observed that application architectures are often far more complex than their state management systems, which currently rely on simpler approaches, often centered on gathering and maintaining the entire message history and other less complex state systems.
It’s still early days, but this suggests two possibilities: either state systems in LLM applications have significant room for refinement and intelligence, or simpler state management may remain a preferred approach for many, provided teams are willing to pay the trade-off of increased context window usage.
As more complex systems evolve, it will be interesting to see how the balance between simplicity, cost, and efficiency shapes the future of state management in SOTA LLM applications.