


Coding agents have become the focal point of modern software development. Tools like Cursor, Claude Code, Codex, Cline, Windsurf, Devin, and many more are revolutionalizing how engineers write and ship code.
A consistent pattern among the most capable agents is their reliance on a single, persistent system prompt rather than a chain of sub-prompts. Each session starts with a comprehensive base prompt defining available tools, I/O formats, and safety policies. From there, all messages build on the same context. This design lets the model maintain state through its context window, use tool outputs as implicit memory, and reason continuously without an external controller — favoring simplicity, stability, and tight feedback loops.
That single, often large, system prompt effectively governs the agent’s behavior. It’s a major determinant of performance, and its precision and scope directly influence how reliably the agent performs complex coding tasks.
To give developers more control, most coding agents expose rules files — user-defined instruction sets that are appended directly to the system prompt. These files let users configure behavior around security and compliance, programming style, architectural patterns, testing practices, and more by directly appending structured guidance to the base prompt.
Rules are a hot topic; it feels like I see people share their new coding agent rules on X every day. This is largely because writing effective rules is difficult. How do you know if a rule actually helps? How do you measure its impact or trust that it improves the agent’s reasoning, tool calling, data retrieval, etc.?
To answer this, we used Prompt Learning, our prompt-optimization algorithm, to automatically generate and refine rule files. We applied it to Cline, a powerful open-source coding agent, chosen for both its strong baseline performance and full transparency — including access to its prompts, tool descriptions, and system configuration — which make it ideal for optimization.
Keep reading to see how we improved Cline’s accuracy by 10-15%, just by optimizing Cline rules.
What Is Prompt Learning?
Prompt learning is an optimization algorithm designed to improve prompts, inspired by reinforcement learning. It employs a similar [action -> evaluation -> gradient] framework, modified and optimized for prompts. It’s a method of realizing improvements and gains for your LLM applications and agents by optimizing their prompts, rather than having to fine-tune or train the underlying LLMs.
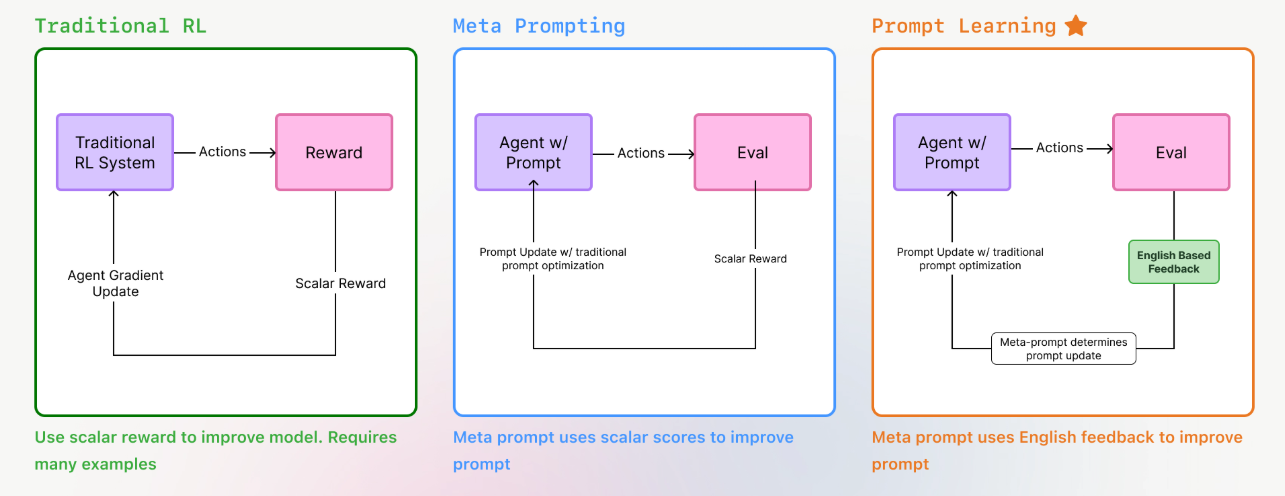
Instead of something like gradient descent, the prompt optimization technique that prompt learning uses is called meta prompting. Meta prompting is the simple concept of feeding a prompt into an LLM, and asking it to improve the prompt. You can also provide the meta prompt LLM with context that shows how the original prompt performs. This often includes input/output pairs, along with labels/scores on those outputs, such as whether those outputs were correct or incorrect.
This approach has one major limitation – the labels/scores/scalar reward provides very low information content to the meta prompt LLM about the individual data points. The LLM does not know WHY certain outputs were correct/incorrect, where improvement is needed, or any specific nuance about those datapoints.
Prompt learning completes the algorithm by using LLMs to generate rich english feedback for the meta prompt. This helps guide the meta prompt LLM to producing better prompts.
- Initial Prompt: Start with a baseline prompt that defines your task
- Generate Outputs: Use the prompt to generate responses on your dataset
- Evaluate Results: Run evaluators to assess output quality
- Optimize Prompt: MetaPrompt(initial prompt, data, feedback) -> optimized prompt
- Iterate: Repeat until performance meets your criteria
Evaluating Improvement with SWE Bench
For reference, see the SWE bench paper and the SWE Bench leaderboard.
We specifically used prompt learning to optimize Cline, through its rules. In order to track Cline’s improvement across optimizations, we used SWE Bench. SWE-bench is a benchmark designed to evaluate a system’s ability to automatically resolve real GitHub issues. It contains 2,294 issue–pull request pairs from 12 popular Python repositories. Each system’s output is evaluated through unit test verification, using the post–pull request repository state as the reference solution. It’s a popular and widely adopted benchmark for coding automation tasks.
We specifically used SWE-bench lite, which includes 300 issue-pull request pairs.
The Optimization Loop

Initialize – Train/Test
We split SWE-bench Lite into a 50/50 train–test split with 150 examples each — enough data to drive meaningful optimization but also enough data to have sufficient test coverage for reliable measurement of improvement.
Training Phase
Running Cline
Cline was booted up on individual servers. We used Cline’s standalone server implementation, which allows us to send requests to Cline servers through GRPC, pointing them at the SWE bench repositories.
Cline was set to ACT Mode – where its given full access to read and edit code files as it deems fit.
We configured each Cline run with the current ruleset by funneling it through .clinerules. Ruleset is initialized to empty, and optimized after each training phase.
your-project/
├── .clinerules
├── src/
├── docs/
└── …After giving Cline ample time to run, we used git diff to generate cline_patch, or the patch it produced.
Testing Cline
We then use SWE-bench package to run the unit tests for each SWE bench row after Cline’s edits, which tells us whether Cline was correct/incorrect.
Evaluating Cline – Generating Feedback/Evals
Evals are a crucial part of the optimization loop – they serve as powerful feedback channels for our Meta Prompt LLM to generate an optimized prompt. The stronger the evals are, the stronger the optimization should be.
We used GPT-5 to compare cline_patch with patch (ground truth patch) from SWE bench, asking it to tell us WHY cline_patch was right/wrong, and WHY the model may have taken the direction it did.
You are an expert software engineer, tasked with reviewing a coding agent.
You are given the following information:
- problem_statement: the problem statement
- cline_patch: a patch generated by the coding agent, which is supposed to fix the problem.
- patch: a ground truth solution/patch to the problem
- test_patch: a test patch that the coding agent's output should pass, which directly addresses the issue in the problem statement
- pass_or_fail: either "pass" or "fail" indicating whether the coding agent's code changes passed the unit tests.
Your task is to review the given information and determine if the coding agent's output is correct, and why.
Evaluate correctness based on the following factors:
- Whether cline_patch fixes the problem.
- Whether test_patch would pass after applying cline_patch.
- Whether the coding agent is taking the correct approach to solve the problem.
You must synthesize why the coding agent's output is correct or incorrect. Try to reason about the coding agent's approach, and why the coding agent may have taken that approach.
problem_statement: {problem_statement}
ground truth patch: {patch}
test patch: {test_patch}
coding agent patch: {cline_patch}
pass_or_fail: {pass_or_fail}
Return in the following JSON format:
"correctness": "correct" or "incorrect"
"explanation": "brief explanation of your reasoning: why/why not the coding agent's output is correct, and why the coding agent may have taken that approach."
"""
Meta Prompt
To complete the training phase, we use everything we have generated as input into a Meta Prompt LLM, prompting it to generate a new ruleset.
You are an expert in coding agent prompt optimization.
Your task is to improve the overall ruleset that guides the coding agent.
Process:
1. Review the baseline prompt, the current ruleset, examples, and evaluation feedback.
2. Identify high-level shortcomings in both the baseline prompt and the ruleset — look for missing guidance, unclear constraints, or opportunities to strengthen general behavior.
3. Propose edits that make the ruleset more robust and broadly applicable, not just tailored to the given examples.
BELOW IS THE ORIGINAL BASELINE PROMPT WITH STATIC RULESET
************* start prompt *************
{baseline_prompt}
************* end prompt *************
BELOW IS THE CURRENT DYNAMIC RULESET (CHANGE THESE OR ADD NEW RULES)
************* start ruleset *************
{ruleset}
************* end ruleset *************
BELOW ARE THE EXAMPLES USING THE ABOVE PROMPT
************* start example data *************
{examples}
************* end example data *************
FINAL INSTRUCTIONS
Iterate on the current ruleset. You may:
- Add new rules
- Remove rules
- Edit or strengthen existing rules
- Change the ruleset entirely, if need be
The goal is to produce an optimized dynamic ruleset that generalizes, improves reliability, and makes the coding agent stronger across diverse cases — not rules that only patch the specific examples above.
The rules in the baseline prompt are static, don't change them. Only work on the additional dynamic ruleset.
Please make sure to not add any rules that:
- ask for user input
- use ask_followup_question
Cline is to perform without user input at any step of the process.
Return just the final, revised, dynamic ruleset in bullet points. Do not include any other text.
New ruleset:
Even though we focused solely on ruleset optimization, we provided both Cline’s full prompt and its current ruleset to give the Meta Prompt LLM complete context. The {examples} dataset included input–output pairs, correctness labels, and detailed evals explaining why each case succeeded or failed. Crucially, the Meta Prompt LLM was instructed to generate broadly applicable rules that strengthen overall agent performance — not rules that overfit to specific training examples.
Test Phase
After the optimized ruleset is generated, we boot up Cline servers on the 150 test examples, testing out the optimized ruleset, and generating an accuracy metric (% of test examples where Cline’s patch passed all unit tests).
Final Ruleset
Here are some examples of rules that got added to the ruleset. The final optimized ruleset tends to contain anywhere from 20-50 rules.
- Ensure every code modification strictly preserves correctness, minimality of change, and robustly handles edge/corner cases related to the problem statement—even in complex, inherited, or nested code structures.
- Avoid blanket or “quick fix” solutions that might hide errors or unintentionally discard critical information; always strive to diagnose and address root-causes, not merely symptoms or side-effects.
- Where input normalization is necessary—for types, iterables, containers, or input shapes—do so only in a way that preserves API contracts, allows for extensibility, and maintains invariance across all supported data types, including Python built-ins and major library types.
- All error/warning messages, exceptions, and documentation updates must be technically accurate, actionable, match the conventions of the host codebase, and be kept fully in sync with new or changed behavior.
- Backwards and forwards compatibility: Changes must account for code used in diverse environments (e.g., different Python versions, framework/ORM versions, or platforms), and leverage feature detection where possible to avoid breaking downstream or legacy code.
- Refactorings and bugfixes must never silently discard, mask, or change user data, hooks, plugin registrations, or extension points; if a migration or transformation is required, ensure it is invertible where possible and preserve optional hooks or entry points.
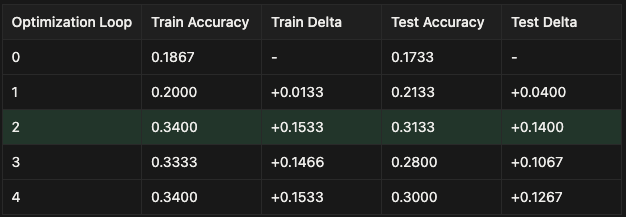
Results
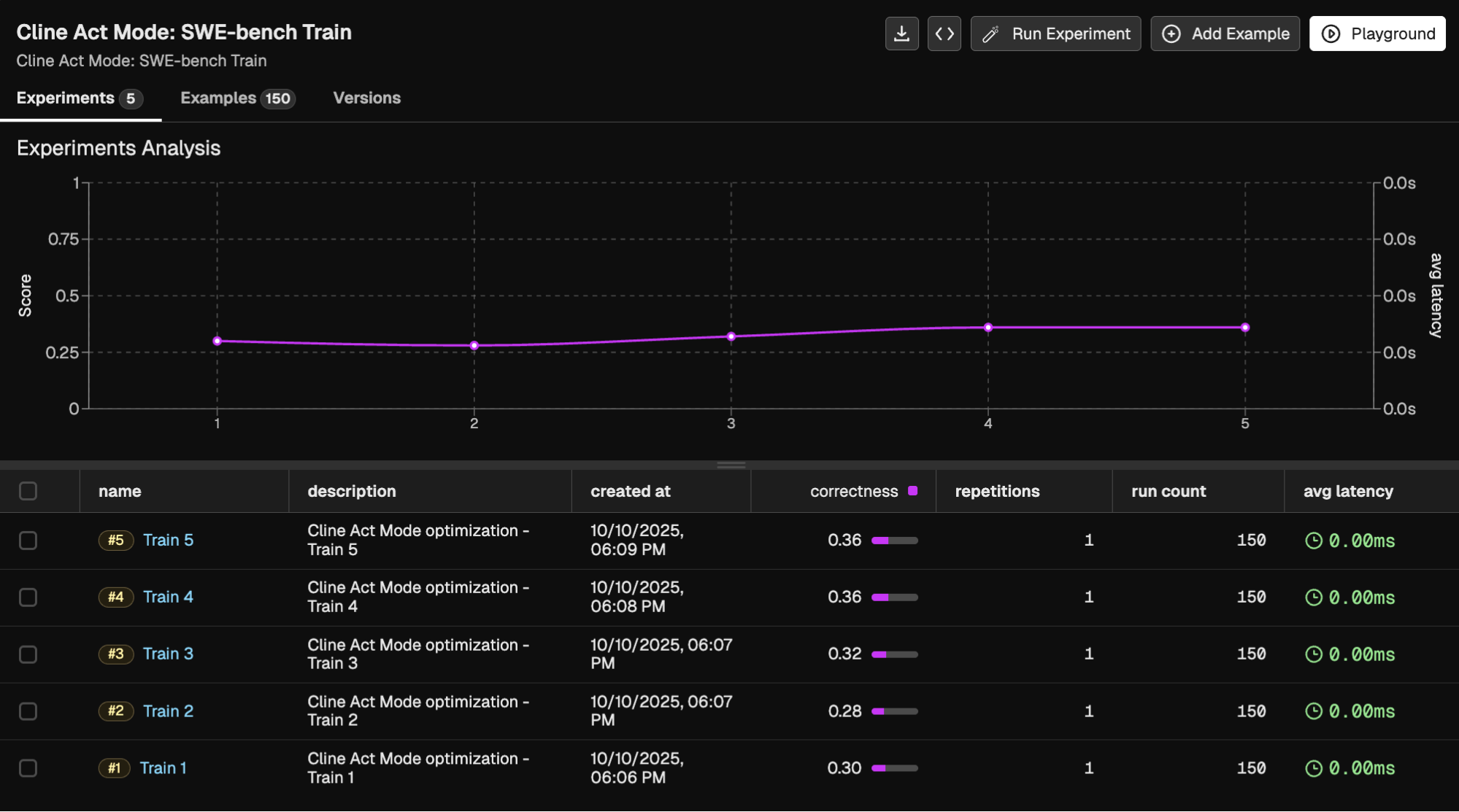
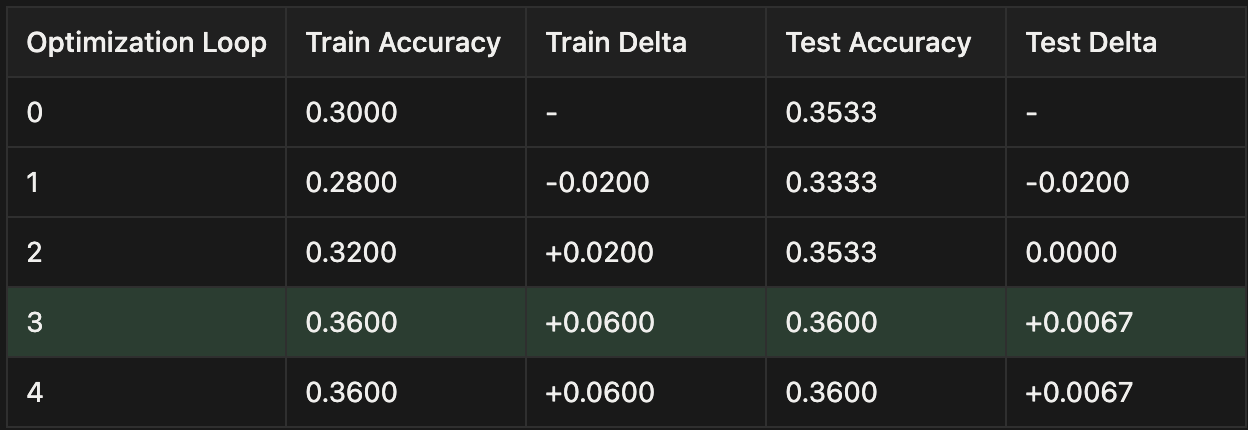
We used Phoenix Experiments to track our Cline runs at each level of optimization. Phoenix Experiments are a great way to test out your LLM applications over datasets, run evals on those experiments, and track your experiments in one central location over time.
Claude Sonnet 4-5
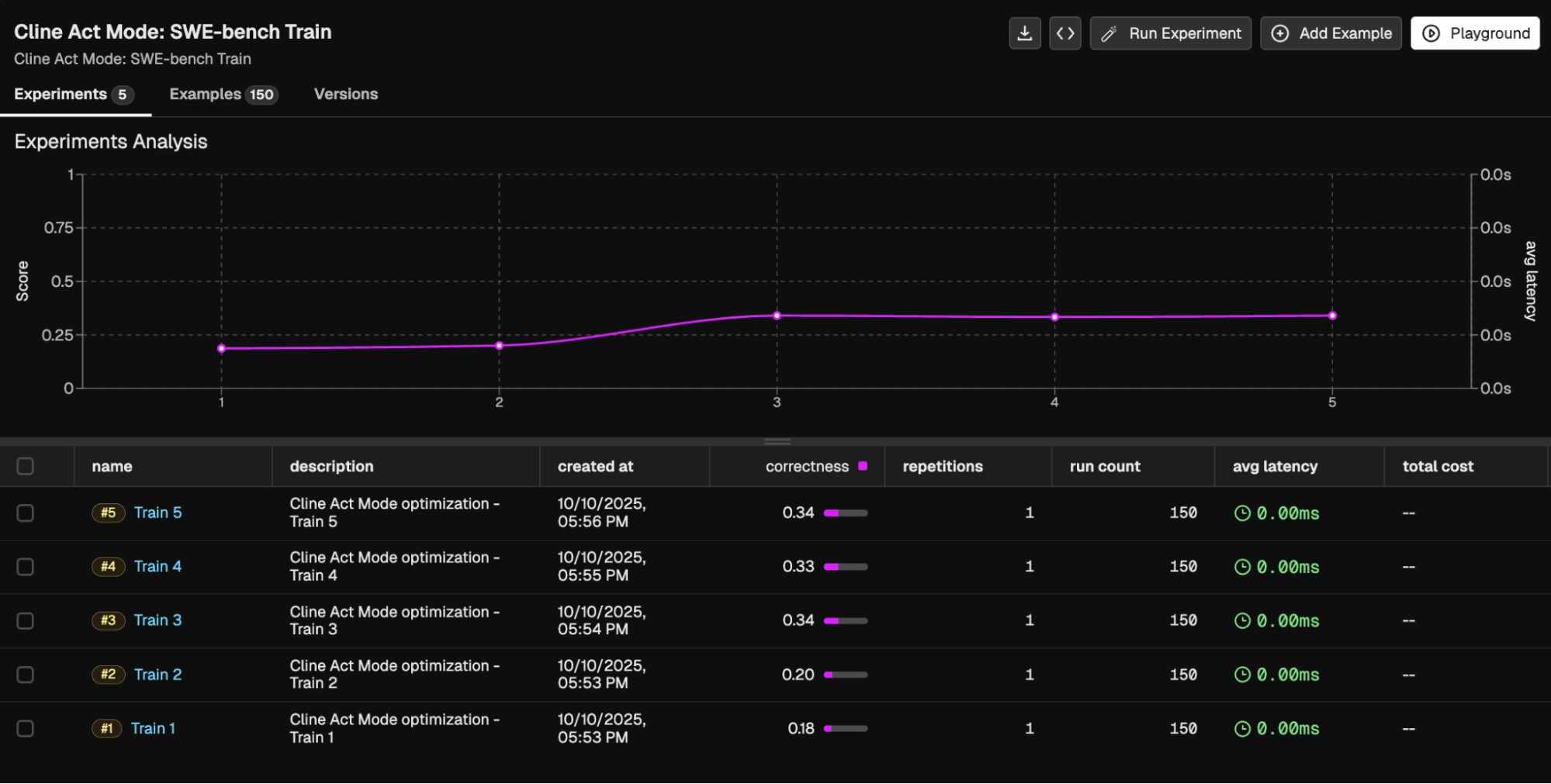
GPT 4.1
Final Takeaways
Sonnet 4-5 is already near the ceiling of coding-agent performance on SWE-bench — a state-of-the-art model that leaves little headroom for further gains. GPT-4.1, on the other hand, had more room to improve. Through ruleset optimization alone, Prompt Learning was able to close much of that gap, bringing GPT-4.1’s performance close to Sonnet-level accuracy without any model retraining, architectural changes, or additional tools.