



Every new AI release rises or falls on how people experience it, and prompts play a major role in shaping that experience.
A short sentence can write code, trigger tools, and pull data from secure systems, all depending on how it’s written. Teams juggle hundreds of loose one-off prompts, each performing differently because of context, model parameters, or plain randomness.
Prompt management tools help people share, version, organize, and refine prompts the same way engineers handle code on GitHub.
This blog explains what prompt management is, how it works, which tools lead the space, and how you can start using them to bring order to your AI workflows.
What is prompt management?
Prompts became central to AI systems the moment language models began responding like humans. A well-written prompt can decide whether a model explains a concept clearly, follows a rule, or fails.
Even as AI evolves into multi-step agents that plan, search, and call tools, prompts remain the anchor. Each agent still needs an instruction — a text blueprint that defines what it should do, how it should think, and which limits it must respect.
But today’s prompt isn’t just a JSON instruction. It carries model parameters like temperature, max tokens, top-p, and even function-calling rules that shape how it behaves. Change any of them, and you change the outcome.
Because of that, teams have started treating prompts as structured assets: small, composable building blocks that shape reliable AI behavior rather than one-off inputs. This idea of treating prompt management as part of the infrastructure ensures that:
- The same input can be replayed with identical conditions.
- Teams can compare versions and understand what changed.
- Good prompts can be reused across projects or integrated into agents.
In short, prompt management is to language models what Git is to software. It provides rollbacks, history, reproducibility, and collaboration for the instructions that drive AI behavior.
Components of Prompt Management
Prompt management works as a collection of connected parts. Each part supports a specific task, like storing or testing prompts. Together, they keep prompts consistent and usable across projects.
The table below lists the main components found in current prompt management systems.
Central library to store all the prompts
A central library of prompts or a Prompt Hub acts as the single source of truth for every prompt used across an organization.
Instead of storing prompts in scattered text files or within notebooks, the library keeps them in a single, searchable place where every prompt lives with its settings (temperature, max tokens, model), history, and ownership.
A sample index in such a database might look something like this; it might be UI-first or API-addressable.
Copy Code
Copied
Use a different Browser
{ “name”: “email_summary_v2”, “template”: “Summarize in 120 words:\n{document}”, “model”: “gpt-4o”, “params”: { “temperature”: 0.2, “max_tokens”: 220 }, “tags”: [“support”,”summaries”], “version”: “2.3”}
A central library gives teams a stable foundation for managing prompts and their associated data.
Sandbox to test different prompts
A sandbox gives teams a controlled space to test prompts before they reach production. It isolates experimentation from live systems, so changes can be measured without affecting user-facing results.
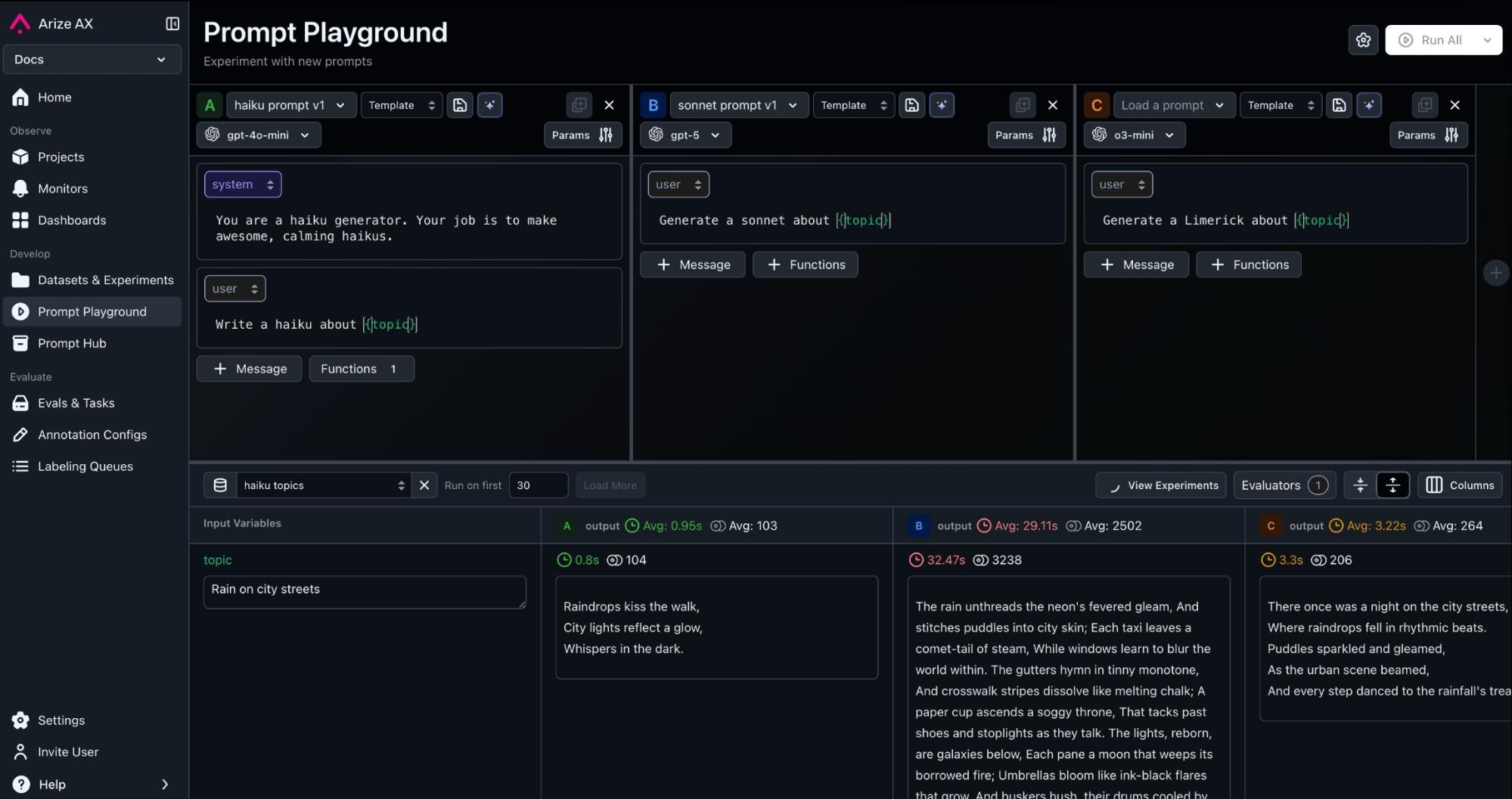 Prompt testing workflow inside Arize AX showing controlled runs and evaluation tracking.
Prompt testing workflow inside Arize AX showing controlled runs and evaluation tracking.
Teams can compare model outputs, adjust parameters, and collect evaluation data safely in this environment. Running tests in a sandbox helps catch performance drift early and keeps prompt changes deliberate instead of reactive.
Feedback loops to judge and improve prompts
Every effective prompt management system needs a feedback loop — a way to capture how prompts actually perform once they’re used.
Outputs are compared with the expected result, and any gaps are logged for revision. Refining prompts in this way improves reliability and makes model behavior easier to predict.
Many teams mix human review with automated scoring. Some use prompt learning, where written feedback is processed by a model to guide later updates. This approach reduces manual labeling and speeds iteration.
Some key LLM evaluation metrics being used to track in production agents are:
| Metric | What It Measures |
| Accuracy | How closely the model’s response matches the correct or expected answer. |
| Coherence | Whether the response maintains context and logical flow across sentences. |
| Helpfulness | How well the output fulfills the user’s intent or task goal. |
| Toxicity | Frequency of biased, unsafe, or offensive language in model outputs. |
| Latency | Time taken by the model to generate a complete response. |
| Cost per Run | The compute or token cost for each prompt execution. |
| Consistency | Stability of results when the same prompt is run multiple times. |
What to look for in a prompt management platform?
Choosing the right prompt management tool depends on how your team actually works with language models. The best way to decide is by asking simple, practical questions:
- Can I update prompts without breaking production?
- Will the system track what changed and why?
- Does it connect to my model provider and data store?
- How easily can I test prompts before they go live?
- Can I review model behavior without exporting logs?
Depending on what stage your team is in — planning, building, scaling, or evaluating — the key things to look for are:
- A clear interface for writing, storing, and reviewing prompts.
- Version control that logs edits and allows rollback when something breaks.
- Built-in evaluation tools to test prompts before deployment.
- Collaboration spaces so that engineers and non-technical teams can work in the same environment.
- Integrations with existing template, observability, tracing, or analytics tools.
- Deployment and cost flexibility to match how your stack is set up today.
Top Prompt Management Tools
The market for prompt management tools has grown fast, with each platform taking a slightly different approach to the different aspects of prompt management.
Below is a breakdown of the most established free and paid options used across teams building AI products today.
1. Arize AX
Best for: Teams that want to generate, manage, evaluate, and monitor LLM or agent behavior in production with complete visibility and control.
Arize AX is a managed, enterprise-ready platform for managing and refining prompts. Its tracing is built on OpenTelemetry, ensuring vendor-agnostic cross-compatibility across frameworks and inference providers.
Every prompt, model call, and evaluation is captured in a unified schema. This schema can replay behavior, compare versions, and measure how changes ripple through an agent’s reasoning process.
Key Features
- Prompt hub: A repository-driven workspace for building and testing prompts at scale. Teams can version prompts, compare behavior across models and parameter settings, and view diffs to monitor regressions.
- UI-based Prompt Playground: The playground supports both UI-based and programmatic workflows — non-technical users can test prompts visually, while developers can log runs into experiments or evaluate multiple traces simultaneously.
- Prompt Optimization: A built-in workflow that tests and refines prompts through automated scoring and feedback cycles. It connects the Playground and evaluation stack, so teams can identify which edits improve performance instead of relying on manual trial and error.
- Alyx-powered integration: Alyx, Arize’s agent workspace, lets users modify or optimize prompts using contextual insights. It can auto-suggest revisions (“enhance clarity,” “adjust tone”) or generate new variants based on retrieved data, ensuring teams never start from a blank slate.
- Data control: Arize AX integrates cleanly with external data and analytics tools. Its schema aligns with open standards like Apache Iceberg, Parquet, and OpenTelemetry, enabling easy export to downstream observability or analytics workflows.
- Prompt Learning: Teams can run continuous tests on live traces, replay sessions, and use automated scoring to track how prompts evolve over time. The prompt learning system supports multi-criteria scoring, benchmark templates, and Alyx-guided evaluation setup — making feedback loops measurable and repeatable.
Limitations
- Smaller deployments: Arize AX is optimized for managed, large-scale environments. Smaller teams or single-server VPC setups often prefer Arize Phoenix for lightweight, self-hosted use.
- OTel configuration: The OpenTelemetry setup can require additional configuration compared to proprietary frameworks, though auto-instrumentation reduces friction and aligns with industry standards for observability.
2. Arize Phoenix
https://storage.googleapis.com/arize-phoenix-assets/assets/gifs/tracing.mp4
Best for: Teams that want open-source control, local deployment, and full flexibility in how they manage and evaluate prompts.
Arize Phoenix is the open-source foundation behind Arize AX. It gives teams the same data model, tracing standards, and evaluation capabilities without the managed cloud layer.
For teams comfortable maintaining their own stack, Phoenix connects easily to existing pipelines and data systems. It’s well-suited for organizations that prefer to keep data in-house or integrate prompt management with existing ML observability tools.
The platform uses the same OpenInference schema and OpenTelemetry standards as AX, making it simple to move between local and managed setups without rewriting integrations.
Key Features
- Prompt management: Phoenix includes a prompt management module that allows teams to create, store, and modify the prompts used to interact with LLMs. When handled programmatically, it becomes easier to refine and experiment with new variations.
- Prompt docs in code: With Phoenix as the prompt-management backend, prompts can be treated as code through Python or TypeScript SDKs, letting them behave like any other component of your tech stack.
- Span replay: Lets users return to a specific point in a multi-step LLM chain and replay that step to test whether an updated prompt or configuration produces a better result.
- Schema compatibility: Phoenix follows the OpenInference schema, the same foundation used in Arize AX. This lets teams move between self-hosted and managed deployments without changing instrumentation or data models.
- Production-minded OSS usage: When teams need a usable UI for day-to-day dev work and a path to production. It’s positioned as a practical base you can extend or later pair with AX.
Limitations
- You manage the infrastructure: Phoenix runs locally, so setup, scaling, and updates fall on your team. For managed deployments, Arize AX handles those layers for you.
- Enterprise guardrails: Access control, audit logging, and compliance features live in AX. Phoenix keeps things lighter for teams to be comfortable running without that overhead.
3. PromptLayer
Best for: Teams that want a hosted prompt management layer with version tracking and analytics without running their own infrastructure.
PromptLayer was one of the first dedicated tools for managing prompts at scale. It captures each model call and records how prompts evolve, letting teams measure the effect of every change on performance and cost.
PromptLayer sits between experimentation and production. It’s less about deep observability and more about managing the creative and operational lifecycle of prompts.
Developers can log every input and output, while product teams use the visual interface to review changes on new variants. The result is a shared workspace where both technical and non-technical members can iterate safely.
Key features:
- Prompt execution logs: Every API call made through PromptLayer is automatically captured with metadata, response time, and token usage. These logs let teams trace failures to specific inputs, detect prompt drift, and benchmark latency across different model providers.
- Dynamic parameter binding: Prompts can include variables (e.g., {customer_name} or {product}) that are injected at runtime. This enables template reuse across applications while keeping configuration consistent and reproducible.
- SDK-based instrumentation: The platform offers client libraries for Python and Node that wrap around existing OpenAI or Anthropic SDKs. This allows prompt logging and replay without changing core business logic.
- Prompt diffing and lineage tracking: Developers can compare prompt revisions line by line, view differences in both text and parameter space, and map lineage between experiments. This prevents regressions when optimizing prompts over time.
- Cost and latency heatmaps: The analytics layer visualizes prompt-level cost and response distribution. Teams can identify inefficiencies, detect over-tokenized requests, and monitor downstream latency when chaining multiple prompts together.
Limitations:
- Limited observability depth: While it tracks prompt runs and model responses, PromptLayer doesn’t expose full token-level or agent-trace visibility like Arize AX or LangChain. This makes root-cause debugging of multi-step workflows harder.
- No in-house model instrumentation: It wraps around provider APIs but doesn’t instrument self-hosted models or local inference servers directly, reducing flexibility for private deployments.
4. DSPy
Best for: Teams that want to treat prompts as structured, trainable programs rather than text templates.
Developed by the Stanford NLP Group, DSPy is an open-source framework that replaces ad-hoc prompt tinkering with a declarative, data-driven workflow. Instead of manually crafting and revising prompts, teams define modules — small Python functions that represent individual reasoning steps — and DSPy compiles them into optimized pipelines.
Each module can be trained and versioned, allowing systematic improvement using feedback data rather than intuition. In benchmark studies, DSPy pipelines have shown large accuracy gains over few-shot prompts, demonstrating the strength of treating prompts as trainable programs.
Key Features:
- Declarative modules with input/output signatures: Define each reasoning step as a Python module with clear inputs and outputs so prompts stay structured and consistent.
- Modular AI pipelines: Combine retrieval and reasoning modules into workflows that can be updated or optimized without changing the overall logic using pure code.
- Automatic prompt optimization: DSPy uses compilers that analyze how modules perform on real data and automatically rewrite or fine-tune prompts to maximize accuracy, consistency, or any defined metric.
- Traceable and version-controlled logic: Pipelines are reproducible and versioned, making it easier to track how prompt changes affect results.
Limitations:
- Developer-oriented workflow: DSPy requires Python scripting and module design, which can be complex for non-technical teams.
- Limited production tooling: DSPy focuses on research and experimentation; it lacks built-in monitoring or deployment features for large-scale production use.
- Setup and learning curve: The framework’s compiler and optimization steps take time to understand before teams see value.
- Ecosystem maturity: Documentation and UI support are still early compared to longer-established managed tools.
5. PromptHub
Best for: Teams that need a hosted workspace to manage prompts and track their evolution in a structured, accessible way.
PromptHub was created to make prompt operations easier for teams that move fast but still need order. It provides a single environment where prompts can be drafted, tested, and stored alongside their parameters.
This setup reduces confusion that often arises when multiple teams manage prompts separately through notebooks or scripts. Each prompt record carries its performance stats, configuration, context, and usage notes, helping users trace performance shifts over time.
Key Features
- Cross-model testing: PromptHub supports testing templates across many providers (OpenAI, Anthropic, Azure, etc.), allowing comparison and cost sensitivity under different model backends.
- Hosted API and deployment integration: PromptHub exposes REST endpoints to retrieve the latest prompt version, inject variables at runtime, and deploy directly into applications, enabling a “prompts as a service” setup.
- Git-based prompt versioning: Each prompt functions as a versioned object within a Git-backed repository. Teams can branch, review, and merge changes using familiar dev workflows, ensuring traceability across every iteration.
- Prompt chaining: The playground lets you chain multiple prompts together so the output of one becomes the input for another, creating modular workflows for multi-step reasoning or data transformation
- Pipelines with guardrails: A built-in CI/CD layer enforces rule-based checks to block prompts that leak secrets, trigger profanity, or underperform against benchmarks before deployment
Limitations:
- Minimal compliance tooling: Features like audit trails and enterprise-grade permissions are lighter than those in managed observability platforms.
- Basic observability: The platform tracks cost and latency but lacks deep model telemetry or detailed performance traces.
- Limited scalability: Large organizations may find the interface slower when handling thousands of prompt versions or bulk evaluations.
Which prompt management tool is right for my use case?
Choosing a prompt management platform depends on how your team works day to day. Some tools are built for structured scaling, while others focus on flexibility or quick testing cycles.
Both Arize AX and Phoenix stand out for teams that treat prompts as first-class assets because their shared schema links every version, evaluation, and trace under one framework. That makes them ideal for prompt management in complex or production-scale AI systems.
PromptLayer focuses on prompt tracking and version history across APIs like OpenAI or Anthropic. It helps teams measure how prompts evolve and what changes affect outcomes, all within a single workspace.
PromptHub offers a clean, browser-based workspace where teams can write, review, and share prompts. It’s best for collaborative environments that need simple versioning and easy handoffs between product and engineering.
Each platform reflects a distinct working style. The right choice is the one that keeps your feedback process active and transforms everyday testing into meaningful, traceable progress. It should make prompt behavior clearer and strengthen how your team builds confidence in its models.
For teams looking to extend prompt management into broader system reliability, consider exploring model monitoring and production monitoring capabilities that track model drift and performance degradation over time.
FAQs
What is the difference between prompt management and prompt engineering?
Prompt engineering focuses on crafting prompts for accuracy and tone. Prompt management handles storage, versioning, evaluation, and deployment at scale.
Why do teams need prompt management tools?
To replace ad-hoc Excel sheets and manual edits with traceable, version-controlled workflows that link prompts to performance data.
Can prompt management replace fine-tuning?
Not directly. Fine-tuning changes how a model itself behaves, while prompt management focuses on improving how teams interact with that model.
It complements fine-tuning by exposing how prompts perform across datasets, contexts, and models, giving teams clear evidence on whether retraining is even necessary.
Frequently asked questions
How does prompt management integrate with existing ML observability workflows?
Prompt management platforms like Arize AX and Phoenix use OpenTelemetry and open schemas that integrate seamlessly with existing ML observability pipelines. This allows teams to trace prompt changes alongside broader model performance metrics and connect prompt behavior to downstream system outcomes.
What are the top 5 AI prompt management tools for production use?
The top 5 AI prompt management tools covered in this guide are Arize AX, Arize Phoenix, PromptLayer, DSPy, and PromptHub. Each offers different strengths: AX and Phoenix provide enterprise-grade observability and tracing, PromptLayer focuses on hosted version tracking, DSPy enables programmatic prompt optimization, and PromptHub offers collaborative workspace features.
How can I measure AI ROI when using prompt management tools?
You can track real-time AI ROI with custom metrics that measure cost per prompt execution, latency improvements, accuracy gains, and reduction in manual prompt iterations. Many prompt management platforms include built-in analytics for cost and performance tracking across different model providers.
Where can I learn more about prompt management best practices?
Join the Arize community to connect with other practitioners, share prompt management strategies, and stay updated on emerging patterns in LLM evaluation and observability.