


Introduction
Retrieval Augmented Generation (RAG) has become the cornerstone of enterprise AI, yet most organizations struggle with a critical challenge: building RAG systems that work reliably in production. While the promise is compelling, combining LLM reasoning with proprietary knowledge, the reality involves complex orchestration, sophisticated evaluation, and continuous monitoring that traditional frameworks don’t address.
Google’s Agent Development Kit (ADK) provides robust foundations for sophisticated RAG agents, while Arize AX delivers specialized observability, evaluation and continuous improvement for production reliability. In this blog, we’ll see how ADK’s agent orchestration enables complex retrieval workflows while Arize’s platform provides critical visibility for hallucination detection, retrieval quality, and answer-quality assurance.
Google ADK: Intelligent RAG Orchestration
Building production RAG requires more than vector search and creative prompts. Modern enterprise RAG demands sophisticated orchestration of multiple retrieval strategies, intelligent routing between knowledge sources, and adaptive reasoning about retrieved information.
ADK approaches RAG as an intelligent agent system capable of complex decision-making. Rather than forcing all queries through identical processes, ADK enables specialized agents that adapt retrieval strategies based on query characteristics and available knowledge sources.
Key ADK Capabilities for RAG:
- Multi-Modal Knowledge Integration: Seamless integration of diverse sources: databases, vector stores, real-time APIs, and document repositories
- Intelligent Routing: Different query types directed to specialized sub-agents optimized for specific domains or reasoning tasks
- Vertex AI RAG Engine Integration: Native integration providing enterprise-grade document processing and semantic indexing
Arize AX: Specialized RAG Observability + Evaluation
While ADK handles orchestration complexity, Arize AXsolves the challenge of understanding and optimizing RAG behavior. Traditional monitoring falls short because it can’t capture nuanced interactions between retrieval quality, context relevance, and generation accuracy.
Arize AX’s RAG-Specific Capabilities:
- Comprehensive RAG agent Observability: End-to-end visibility from query processing, retrieval to response generation
- Evaluators and Metrics: Flexible LLM as a Judge evaluation framework provides comprehensive metrics against key areas such as hallucination, relevancy, groundedness, answer correctness and citation verification.
- Retrieval Quality Custom Metrics and Monitors: Custom metrics can be derived from evaluators, monitored and proactively alert when performance degrades.
- Context Utilization Monitoring: Tracking how effectively systems use retrieved context
Documentation Retrieval Agent
Let’s dive into a practical implementation with our sample document retrieval agent. We’ll build a comprehensive enterprise knowledge system showcasing both ADK’s orchestration and Arize AX’s observability capabilities. This agent is designed to answer questions related to documents you uploaded to Vertex AI RAG Engine. It utilizes Retrieval-Augmented Generation (RAG) with the Vertex AI RAG Engine to fetch relevant documentation snippets and code references, which are then synthesized by a Gemini LLM to provide informative answers with citations.
Core Architecture: Multi-Agent RAG System
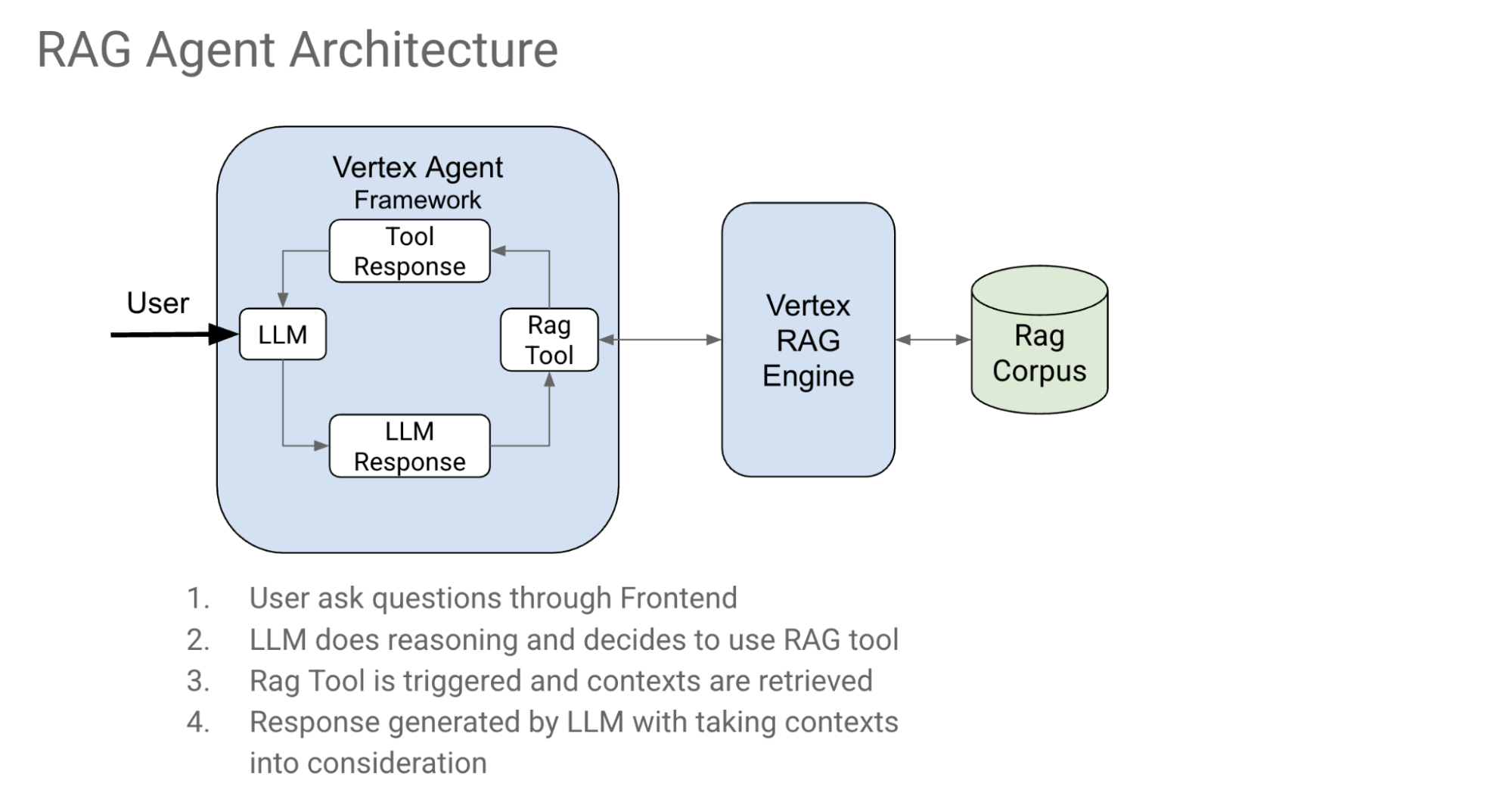
RAG Agent Key Features
- Retrieval-Augmented Generation (RAG): Leverages Vertex AI RAG Engine to fetch relevant documentation.
- Citation Support: Provides accurate citations for the retrieved content, formatted with URLs, title, page start and end.
- Clear Instructions: Adheres to strict guidelines for providing factual answers and proper citations.
Document Retrieval Agent: Code Walkthrough
Please find the full working code example here.
Prerequisites
- Google Cloud Project with Vertex AI and RAG Engine enabled
- Python 3.10+: Ensure you have Python 3.10 or a later version installed.
- uv: For dependency management and packaging. Please follow the instructions on the official uv website for installation.
- Arize AX account (sign up for free)
1. Set up Knowledge Corpus (Google Alphabet 10k 2024) in VertexAI RAG Engine
# This will create a corpus named Alphabet_10K_2024_corpus (if it doesn't exist) and upload the PDF goog-10-k-2024.pdf.
#Authenticate with your Google Cloud account:
gcloud auth application-default login
#Set up Google Project environment variables in your .env file:
GOOGLE_CLOUD_PROJECT=your-project-id
GOOGLE_CLOUD_LOCATION=your-location # e.g., us-central1
#Configure and run the preparation script (upload Alphabet's 10K PDF):
uv run python rag/shared_libraries/prepare_corpus_and_data.py
2. Setup Tracing for the Agent
def instrument_adk_with_arize() -> trace.Tracer:
tracer_provider = register(
space_id = os.getenv("ARIZE_SPACE_ID"),
api_key = os.getenv("ARIZE_API_KEY"),
project_name = os.getenv("ARIZE_PROJECT_NAME", "adk-rag-agent"),
)
GoogleADKInstrumentor().instrument(tracer_provider=tracer_provider)
3. Configure Agent Prompt
def return_instructions_root() -> str:
instruction_prompt_v1 = """
You are an AI assistant with access to specialized corpus of documents.
Your role is to provide accurate and concise answers to questions based
on documents that are retrievable using ask_vertex_retrieval. If you believe the user is just chatting and having casual conversation, don't use the retrieval tool.
.......
Citation Format Instructions:
When you provide an answer, you must also add one or more citations **at the end** of your answer. If your answer is derived from only one retrieved chunk, include exactly one citation. If your answer uses multiple chunks from different files, provide multiple citations. If two or more chunks came from the same file, cite that file only once.
.........
Simply provide concise and factual answers, and then list the
relevant citation(s) at the end. If you are not certain or the
information is not available, clearly state that you do not have enough information.
"""
4. Setup Agent and tools
ask_vertex_retrieval = VertexAiRagRetrieval(
name='retrieve_rag_documentation',
description=(
'Use this tool to retrieve documentation and reference materials for the question from the RAG corpus,'
),
rag_resources=[
rag.RagResource(
rag_corpus=os.environ.get("RAG_CORPUS")
)
],
similarity_top_k=10,
vector_distance_threshold=0.6,
)
with using_session(session_id=uuid.uuid4()):
root_agent = Agent(
model='gemini-2.0-flash-001',
name='ask_rag_agent',
instruction=return_instructions_root(),
tools=[
ask_vertex_retrieval,
]
)
Example Usage:
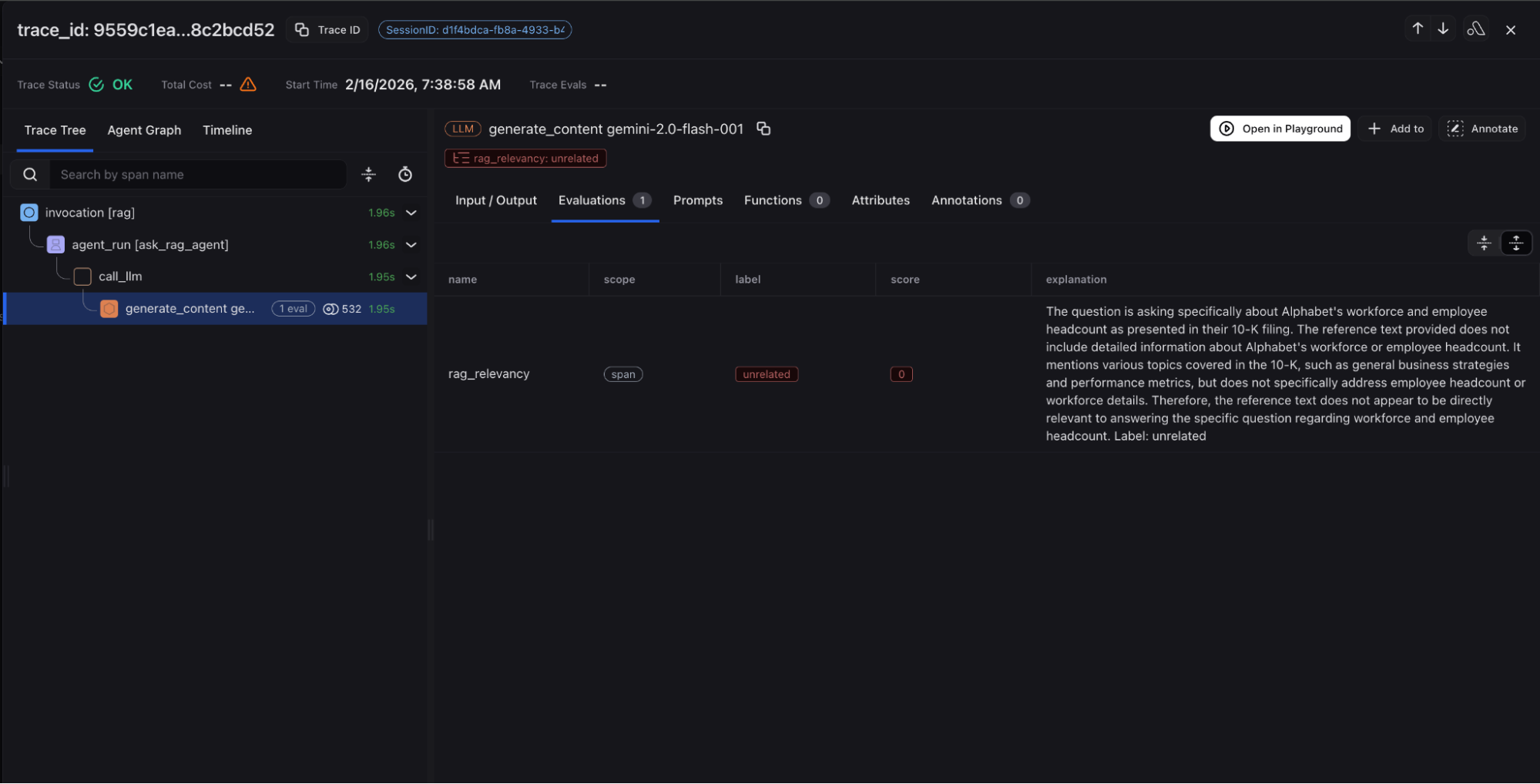
In adk web or adk cli, invoke your agent by asking questions related to google’s finances and you will see an output like this.
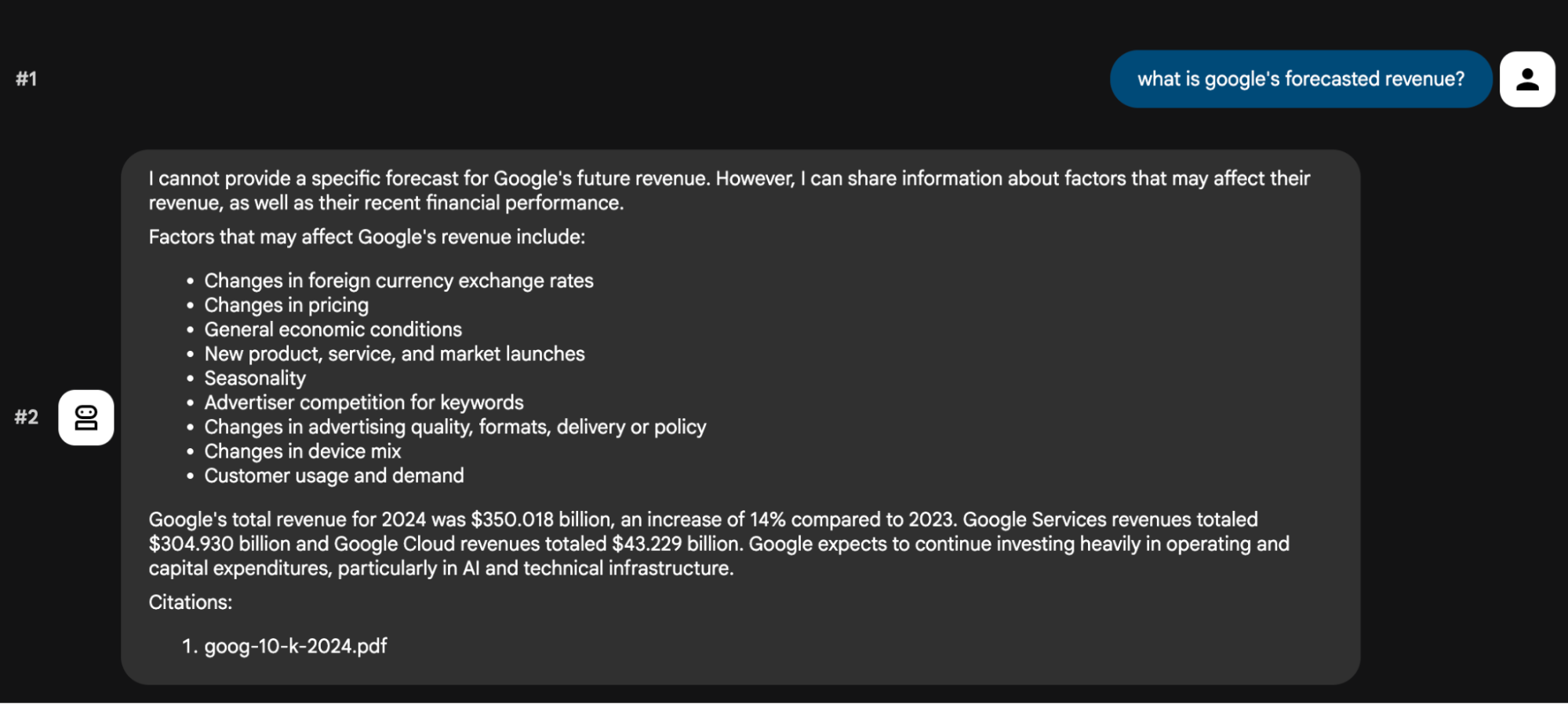
Now, check Arize AX to view your traces!
Advanced RAG Observability
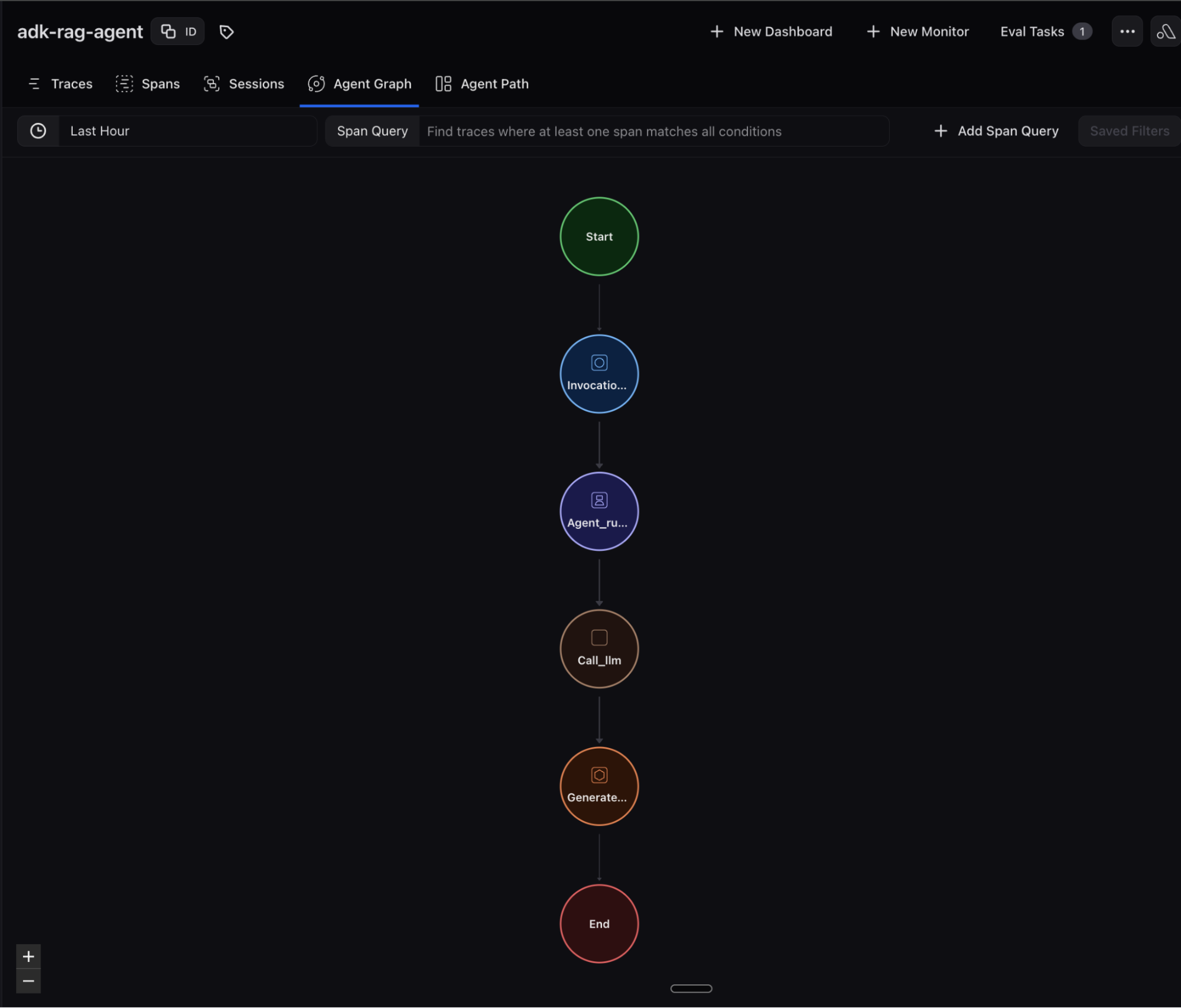
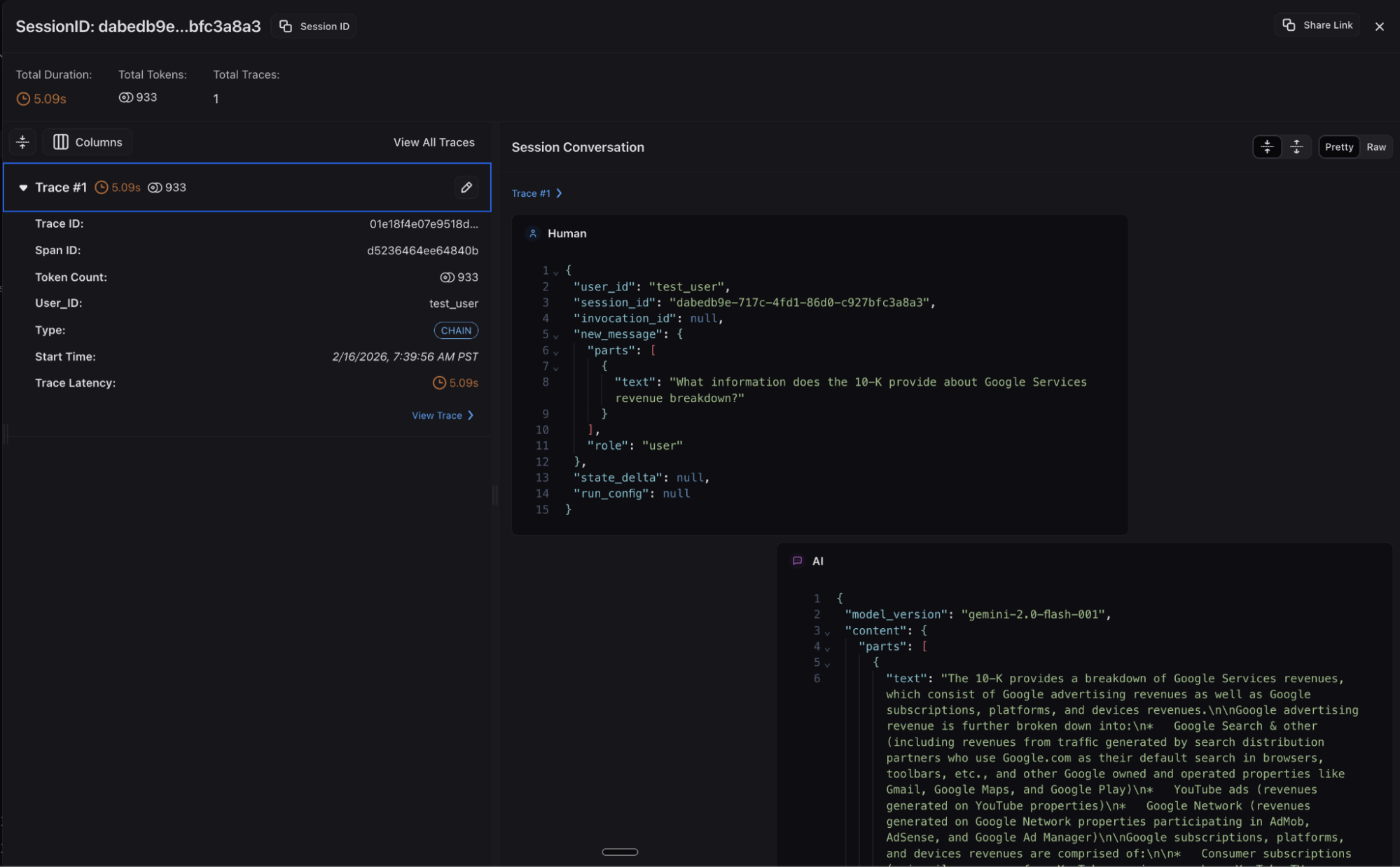
In Arize AX, you have complete visibility from query analysis through retrieval execution to response generation, enabling teams to understand decision points and optimize routing strategies. Documents, page locations and citations from the retrieval step are captured along with Gemini LLM inputs/outputs and relevant metadata. Agent graph visualization and session views provide additional ways to understand your RAG agent’s behavior.
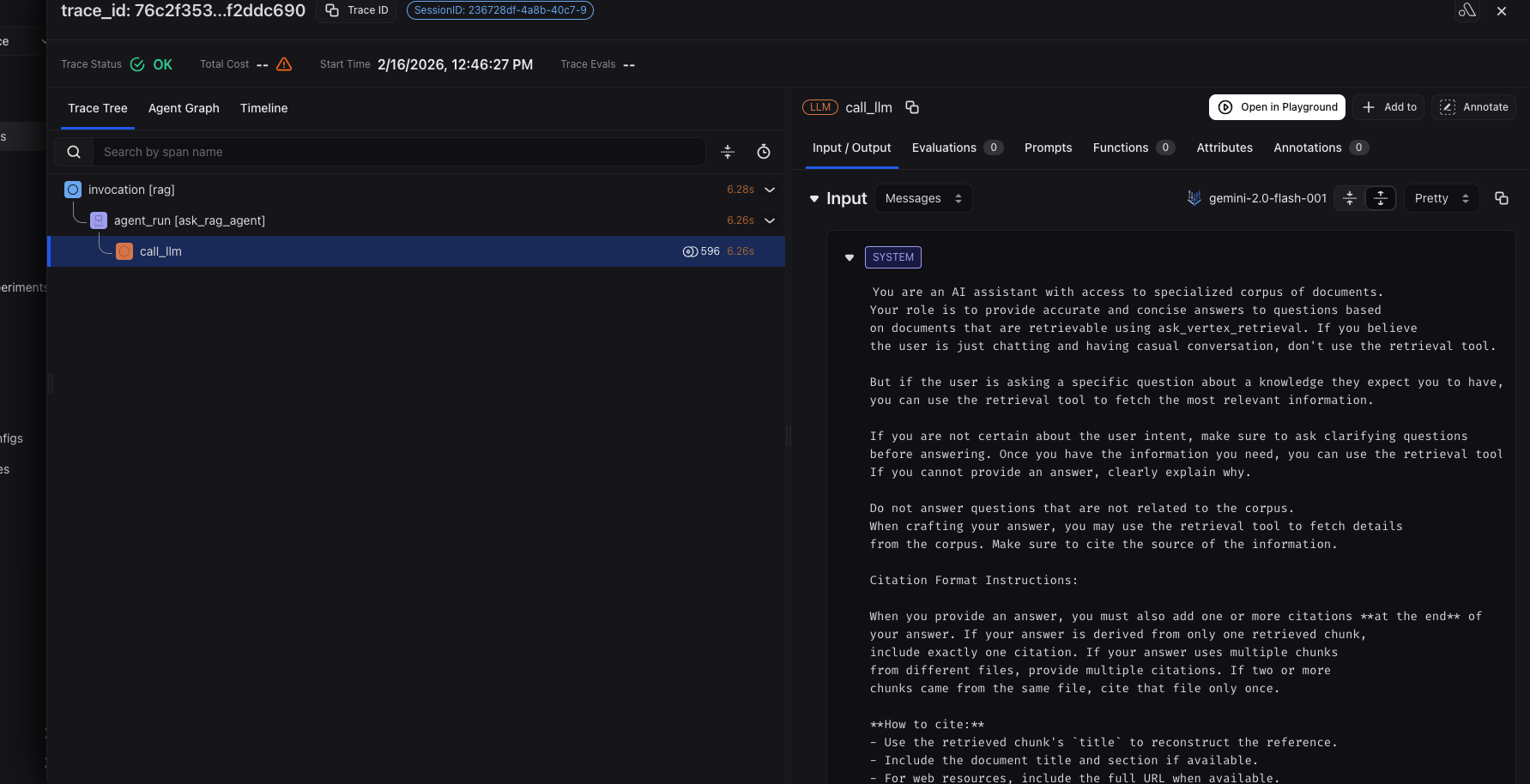
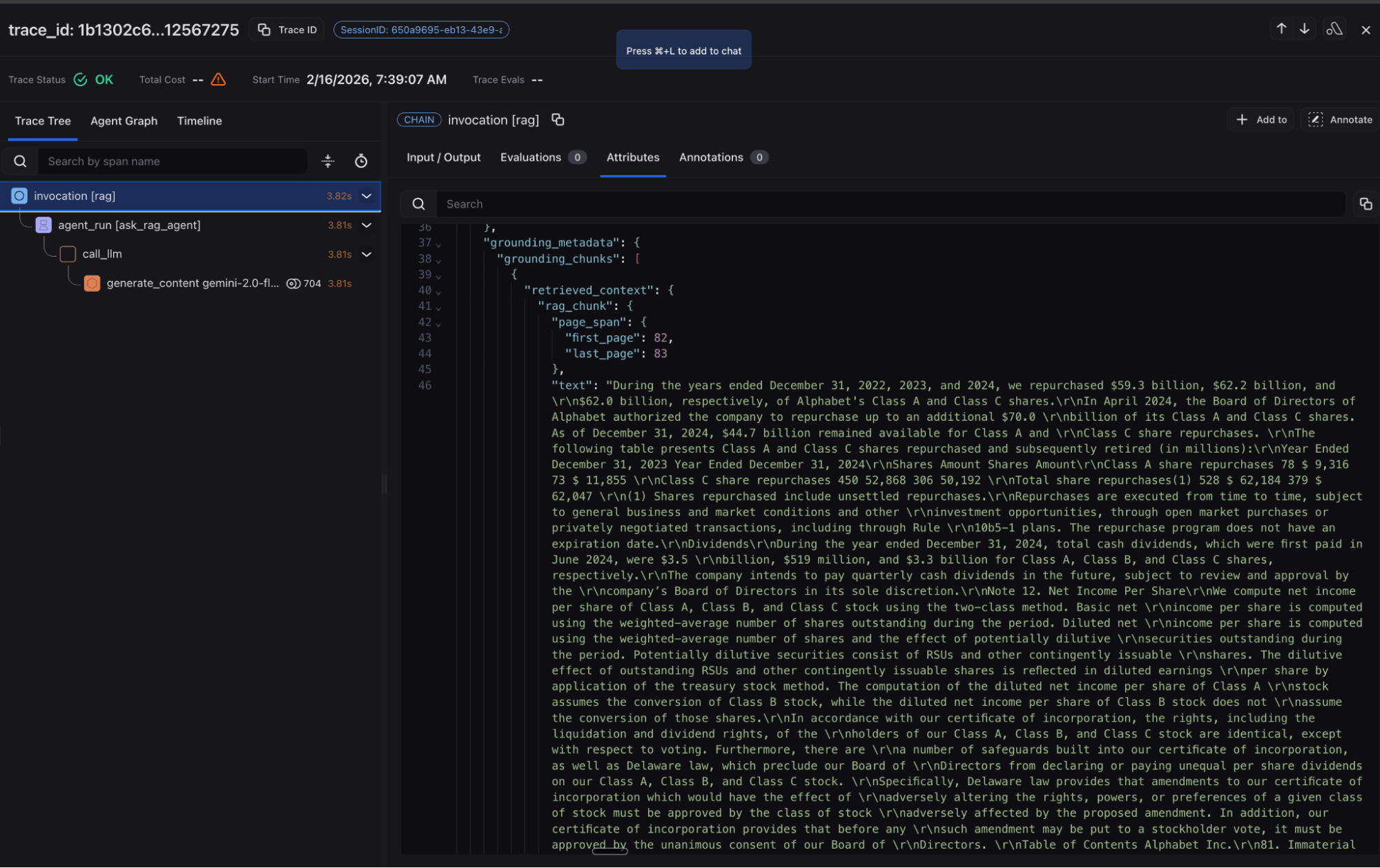
Advanced RAG Evaluation
When the application using RAG doesn’t give a good response, it can be because of different reasons. Arize AX leverages Phoenix’s open source evaluation framework for comprehensive coverage of quality metrics. This evaluation framework comes with a library of prebuilt evaluators that you can get started with and is flexible to create any type of evaluator that suits your specific needs.
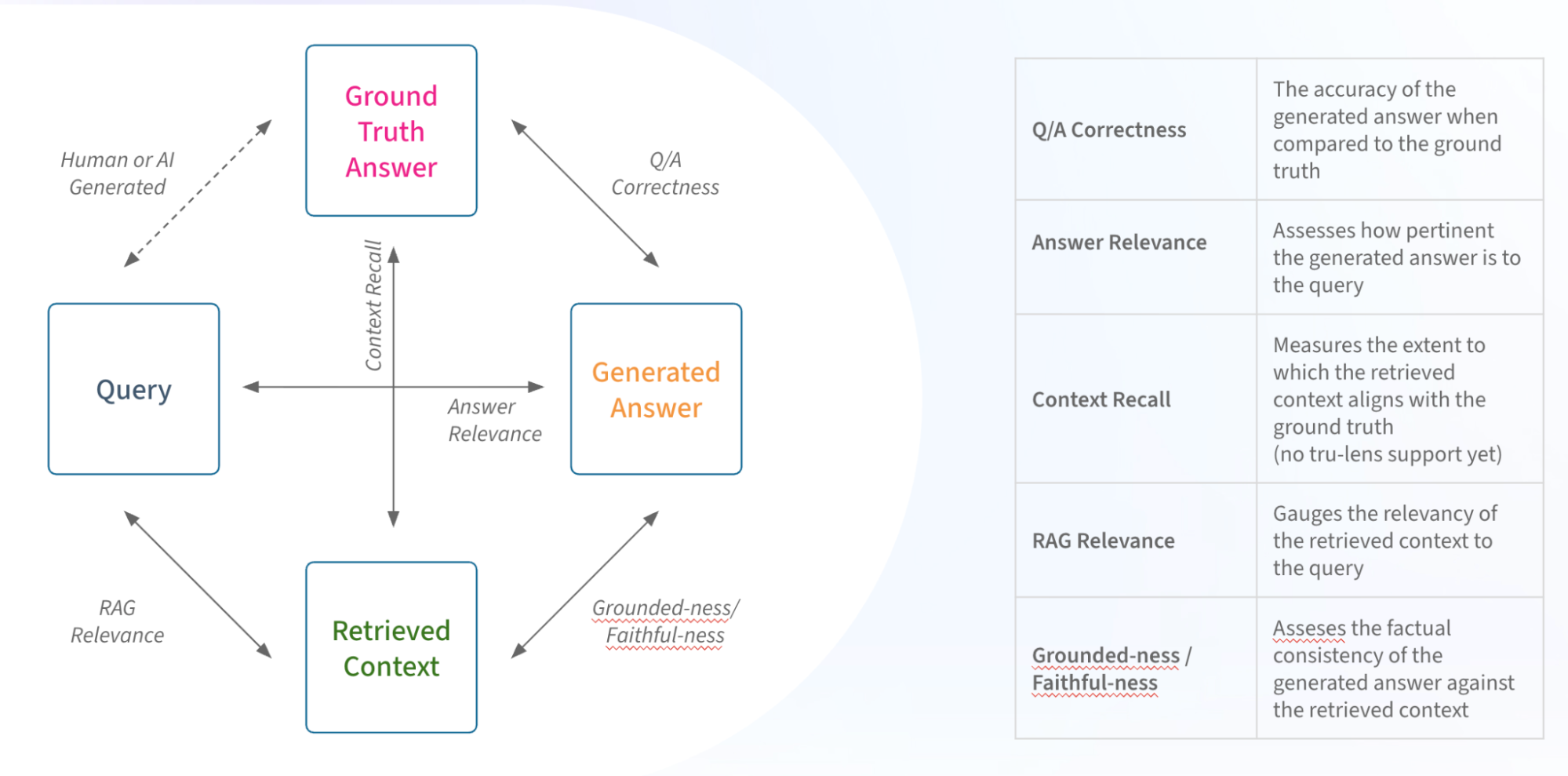
Below are some pre-built evaluators that make it easy to get started. (For a great primer on LLM as a Judge evaluation, see our definitive guide to LLM Evaluation.)
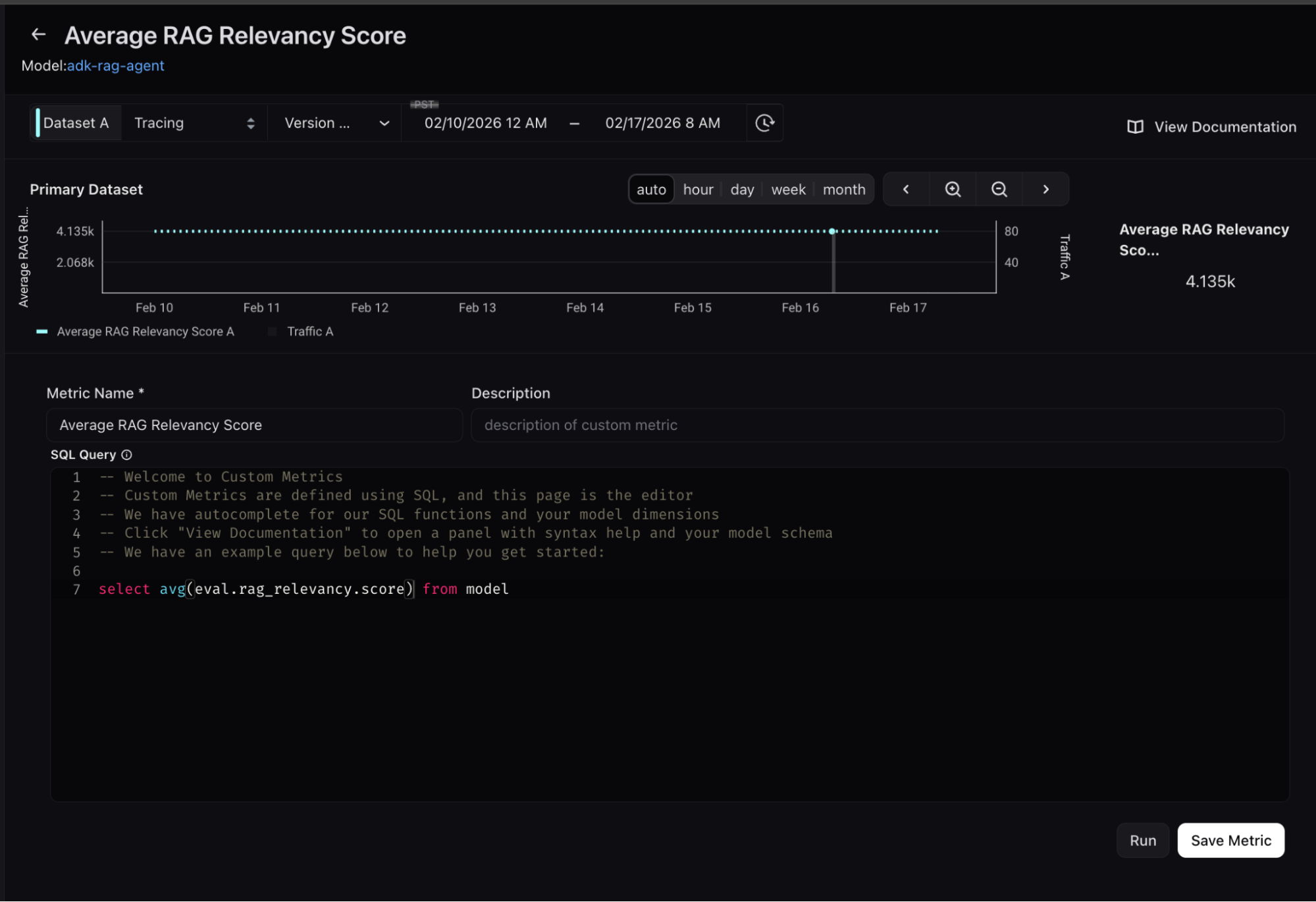
- RAG relevance – This evaluates whether a retrieved chunk contains an answer to the query. It’s extremely useful for evaluating retrieval systems. This can indicate a problem with the retrieval system or lack of coverage in your knowledge database.
- Faithfulness – It detects when responses contain information that is not supported by or contradicts the reference context.
- Q&A on Retrieved Data – This evaluates whether a question was correctly answered by the system based on the retrieved data. In contrast to retrieval Evals that are checks on chunks of data returned, this check is a system level check of a correct Q&A.
- Reference / Citation Links – This Eval checks the reference link returned answers the question asked in a conversation
- AI vs Ground Truth – This LLM evaluation is used to compare AI answers to Human answers. It can be useful in RAG system benchmarking to compare the human generated ground truth.
Automatic Online Evaluation
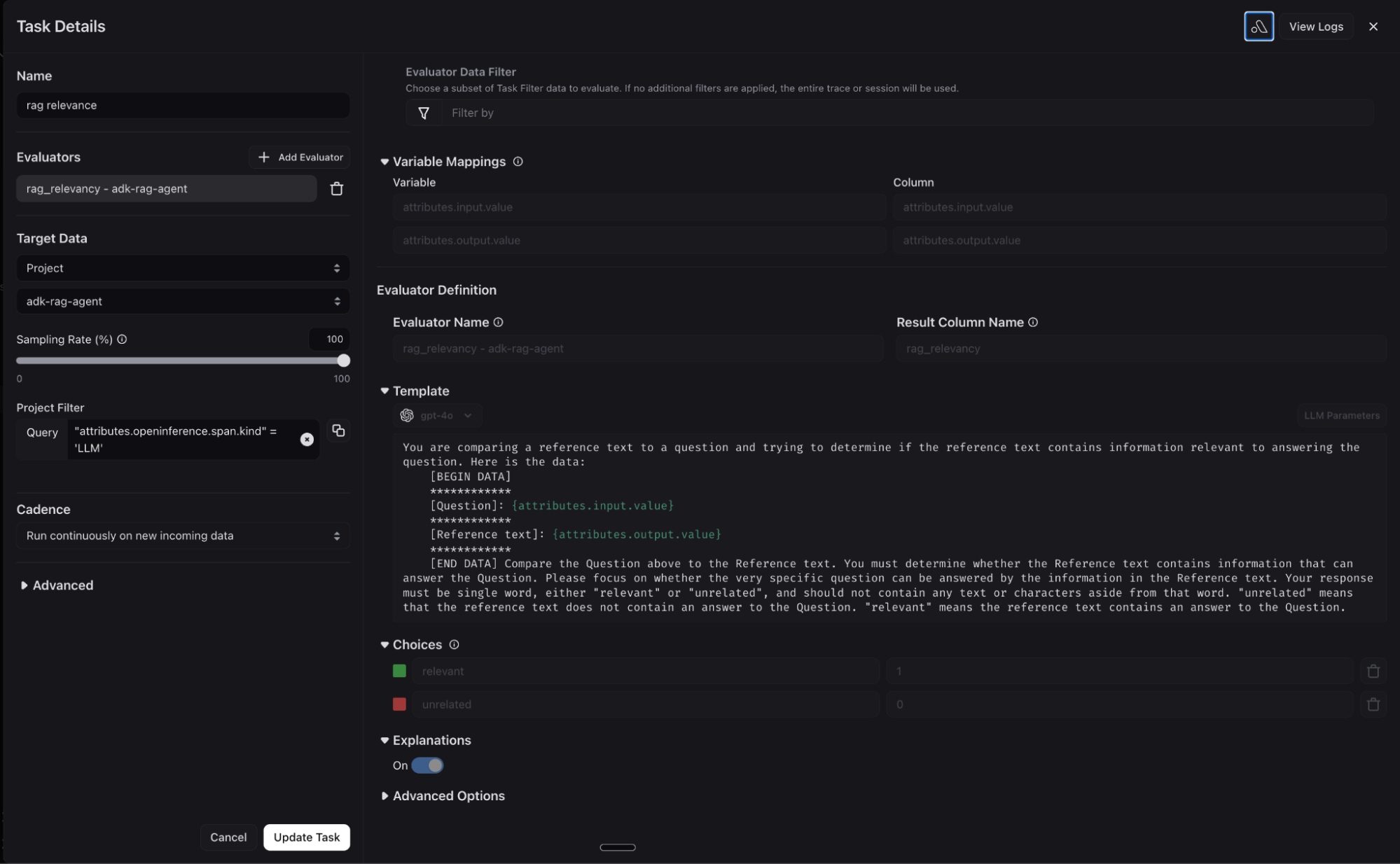
In production RAG systems, your evaluation system needs to support automation and scale. Arize AX automatically runs evaluators on your traces as they are ingested into the platform at high production volumes. This in turn enables automatic dataset curation for failed regressions (for example, detected hallucinations or failures on any evaluation metrics). These datasets then act as fuel for downstream improvement cycles for your Agent.
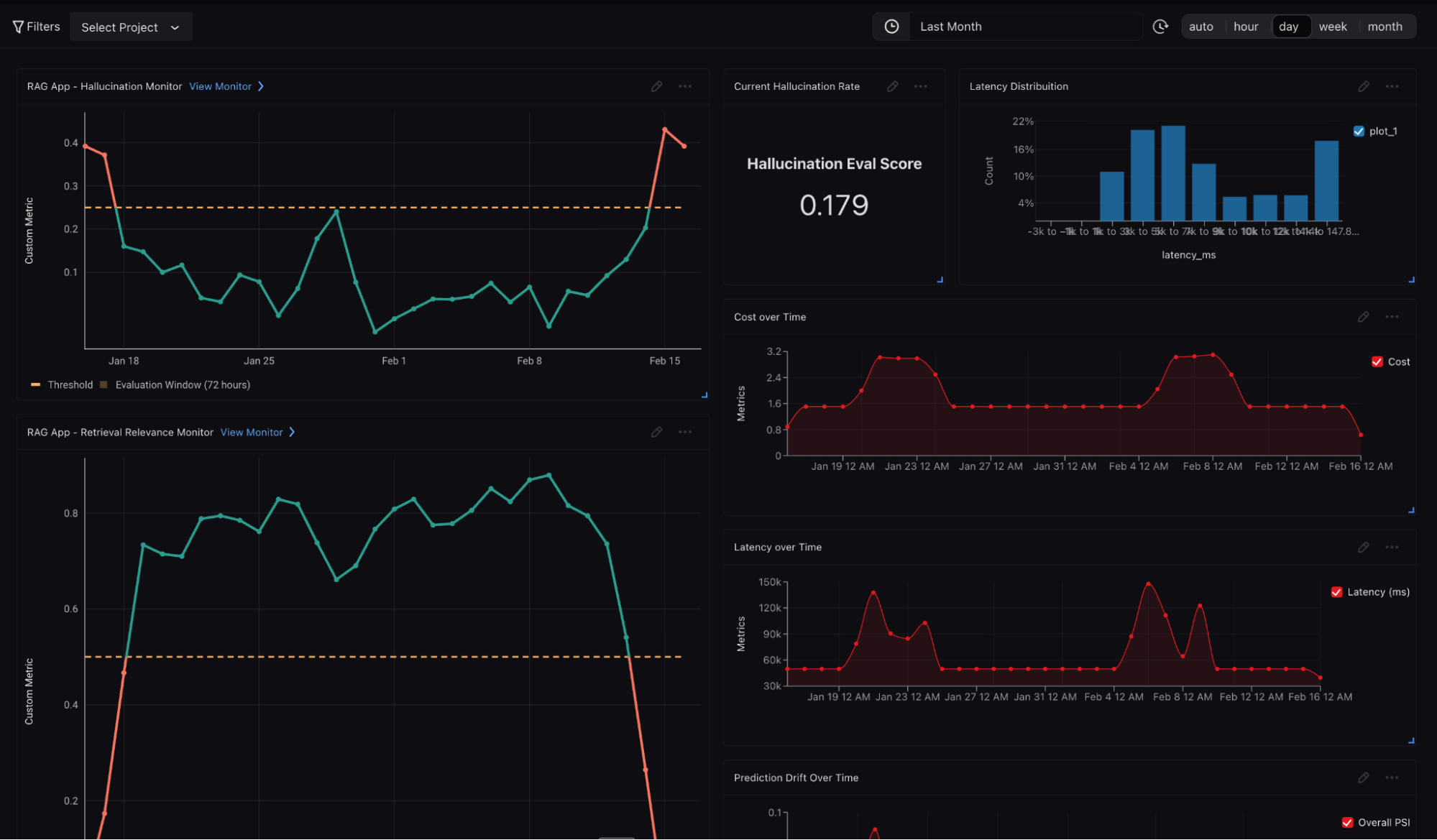
High-Scale Real-Time Performance Monitoring
In production, your AI observability system needs to ingest, evaluate and monitor at massive scale up to billions transactions in real time. Arize AX converts all critical performance and RAG evaluation signals into metrics, which drive flexible dashboards and proactive monitors. The proactive monitors automatically fire notifications into your backend systems like slack, pagerduty, opsgenie, etc, whenever latency, errors or rag quality metrics degrade beyond critical thresholds.
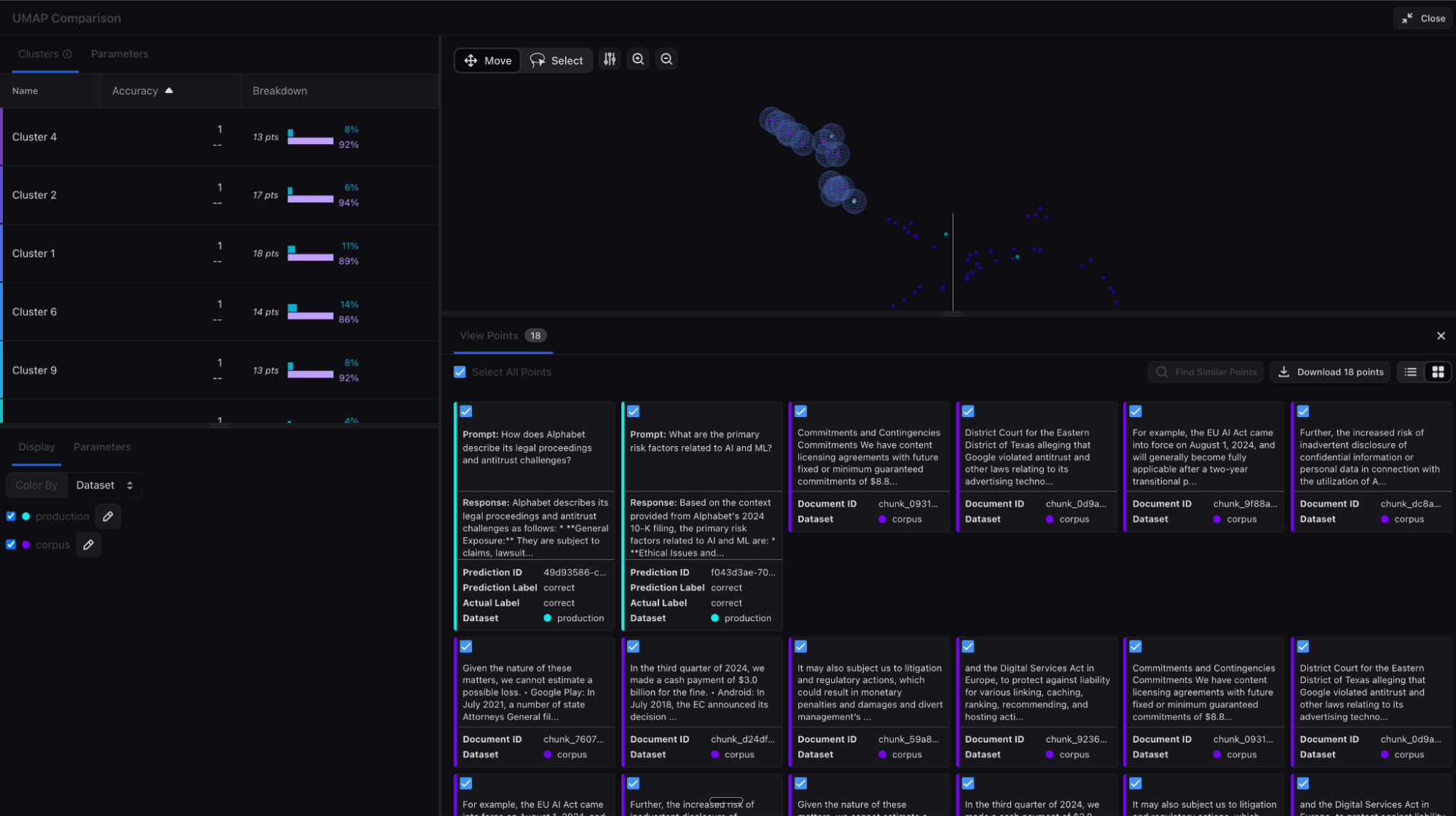
Embeddings analysis – Knowledge base
Arize AX can process embedding data from your knowledge base and user queries to give additional insights into the effectiveness of your RAG retrieval system. Embeddings representing your data can be generated and uploaded to Arize AX, powering UMAP visualizations and clustering to help reveal patterns, drift and gaps in your knowledge base. By visualizing query/context density, you can understand what topics you need to add additional documentation for in order to improve your chatbot responses. (For more information, refer to our docs).
Conclusion
Putting all of this together, high quality RAG systems leveraging Arize AX and Google ADK provide the following key outcomes and business value:
- Higher answer quality and trust: Improving user confidence and decision-making for end users from accurate, relevant, and well-supported responses with fewer hallucinations and incomplete answers.
- Faster optimization and operational efficiency: Iterate more quickly and reduce manual overhead. Proactive monitoring and streamlined workflows enable teams to detect issues earlier and reduce poor experiences.
- Enterprise-ready reliability and scale: Production grade performance at massive scale.
The integration between Google ADK and Arize AX addresses the fundamental enterprise RAG challenge: building systems sophisticated enough for real-world complexity while providing the reliability and transparency enterprises demand at enterprise scale. This best-of-breed approach enables organizations to move from experimental RAG implementations to core business systems that augment human expertise and accelerate decision-making. With ADK’s intelligent orchestration and Arize’s specialized observability and evaluation platform, enterprises can finally deploy RAG systems with confidence.
Ready to get started? Begin with the enterprise RAG implementation guide, explore the integration capabilities, and discover how this powerful combination can transform your approach to enterprise knowledge systems.