

You can build a measurably better agent from data you already have, without retraining a thing. The data is what your experienced humans do when they correct the AI. Capture those domain-knowledge based corrections as a context graph, mine them for patterns, and the agent steadily matches what the humans actually do.
Every AI agent deployed inside an enterprise sometimes quietly disagrees with the humans running the same process. The written policy says one thing. The institutional knowledge sitting in Slack threads, hallway conversations, and the heads of long-tenure employees says another.
The agent is correct against policy and wrong against reality. The reviewer is right because they hold context the system of record doesn’t. Most teams treat the gap between them as noise. It’s the most useful signal in the system.

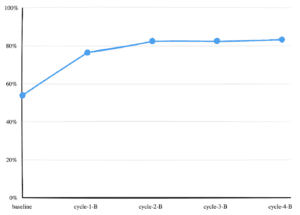
To prove it, we built a procurement agent. Ran 130 purchase requests through it. A simulated reviewer with years of institutional knowledge disagreed with the agent on 60 of those decisions: a 53.8% baseline match rate. After four cycles of mining the disagreements and feeding the patterns back as runtime config, the agent matched the reviewer on 108 of 130, an 83.1% rate. No source-code changes. No fine-tuning. Just structured capture of human overrides and a loop that reads them.
We covered the broader case for context graphs in an earlier post. This post shows what they look like when you build one.
What we built
We built three components for this demo:
- Procurement agent: simulates a real-world procurement system managed by an agent. Users submit purchase requests; the agent reviews them against its process documents and approved vendor list. Traces go to Arize AX.
- Vera Fye, a human reviewer: a simulated human reviewer with institutional knowledge. She reviews the agent’s decisions and overrides where necessary, and the overrides feed back through the procurement agent so they’re traced too.
- Mining agent: a Claude Agent SDK tool wrapping agent skills that extract traces from Arize AX and propose improvements to the procurement agent.
The demo is available for you to explore on GitHub.
The procurement agent
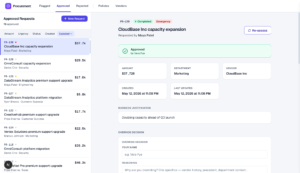
The procurement agent is a Python agent built with LangChain, with a Next.js UI. When the agent launches, it loads a set of process documents that details the rules for the procurement process, such as which vendors are already approved, price thresholds, and so on.
At runtime the agent calls three tools (check_policy, lookup_vendor, check_budget) to gather context before deciding. Each vendor record has a status (preferred / approved / suspended / not_listed), categories, notes, and extension fields (cost-overrun factor, relationship credit) that default to inert values. Approvals tier by amount: auto-approve below $5K, manager approval up to $50K, VP approval above. Requests come from one of five departments (Engineering, Marketing, Sales, Customer Success, Security).
The agent’s output is a recommendation (approve / reject / flag-for-review) plus a confidence level (high / medium / low), and all the traces for one request group into an Arize AX session.
Once the agent and UI is running, you can manually add procurement requests to be reviewed by the agent, or you can use the seed_requests script to upload 130 sample requests.
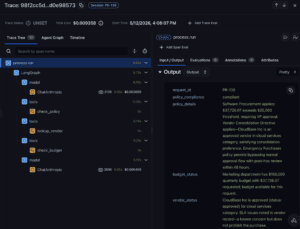
Every step in the agent flow is traced: the policies it followed, its reasoning, its final decision.
Based on the knowledge the agent has, here’s a summary of how the agent processes the sample data:
| Recommendation | Count | % |
|---|---|---|
| Approved | 57 | 43.8% |
| Flagged for review | 42 | 32.3% |
| Rejected | 31 | 23.8% |
| Total | 130 | 100% |
Vera Fye, the reviewer
If you’ve read Gene Kim’s The Phoenix Project, you remember Brent Geller. The senior engineer who knows how every system actually works, who handles every escalation, who is the bottleneck because all the operational knowledge lives in his head. The Phoenix Project plot exists because Brent is undocumented institutional memory walking around in a person.
Brents are real. Every company has them: the long-tenure engineer, the admin who knows everyone, the operations person you ask before doing X. The artifact is the same: rules and context that aren’t written anywhere readable live in this person’s head.
For our demo, Vera Fye simulates the company’s Brent. She carries the undocumented knowledge: which vendor’s CEO plays golf with the enterprise’s CEO, which companies have a history of billing disputes, which departments tend to panic-buy. When she overrides the procurement agent’s decision, the key isn’t the override itself; it’s that we capture it in the same trace session as the original agent decision.
Vera reviewed every request the agent flagged, made the call on each, overrode some of the agent’s clear-cut decisions, and flagged a handful of clean approvals that she felt needed VP sign-off. In total, she made 60 overrides out of 130 agent decisions:
| Agent decision | → | Vera decision | Status | Baseline |
|---|---|---|---|---|
| approve | → | approve | unchanged | 44 |
| approve | → | reject | changed | 10 |
| approve | → | flag-for-review | changed | 3 |
| reject | → | approve | changed | 5 |
| reject | → | reject | unchanged | 26 |
| reject | → | flag-for-review | changed | 0 |
| flag-for-review | → | approve | changed | 27 |
| flag-for-review | → | reject | changed | 15 |
| flag-for-review | → | flag-for-review | unchanged | 0 |
| Total agreements (unchanged) | 70 | |||
| Total disagreements (changed) | 60 |
This means our agent has a success rating of 53.8%. Not great.
Our traces now hold the original decision and the human review side by side. The institutional knowledge that used to live only in Vera’s head is now data we can mine.
The context graph
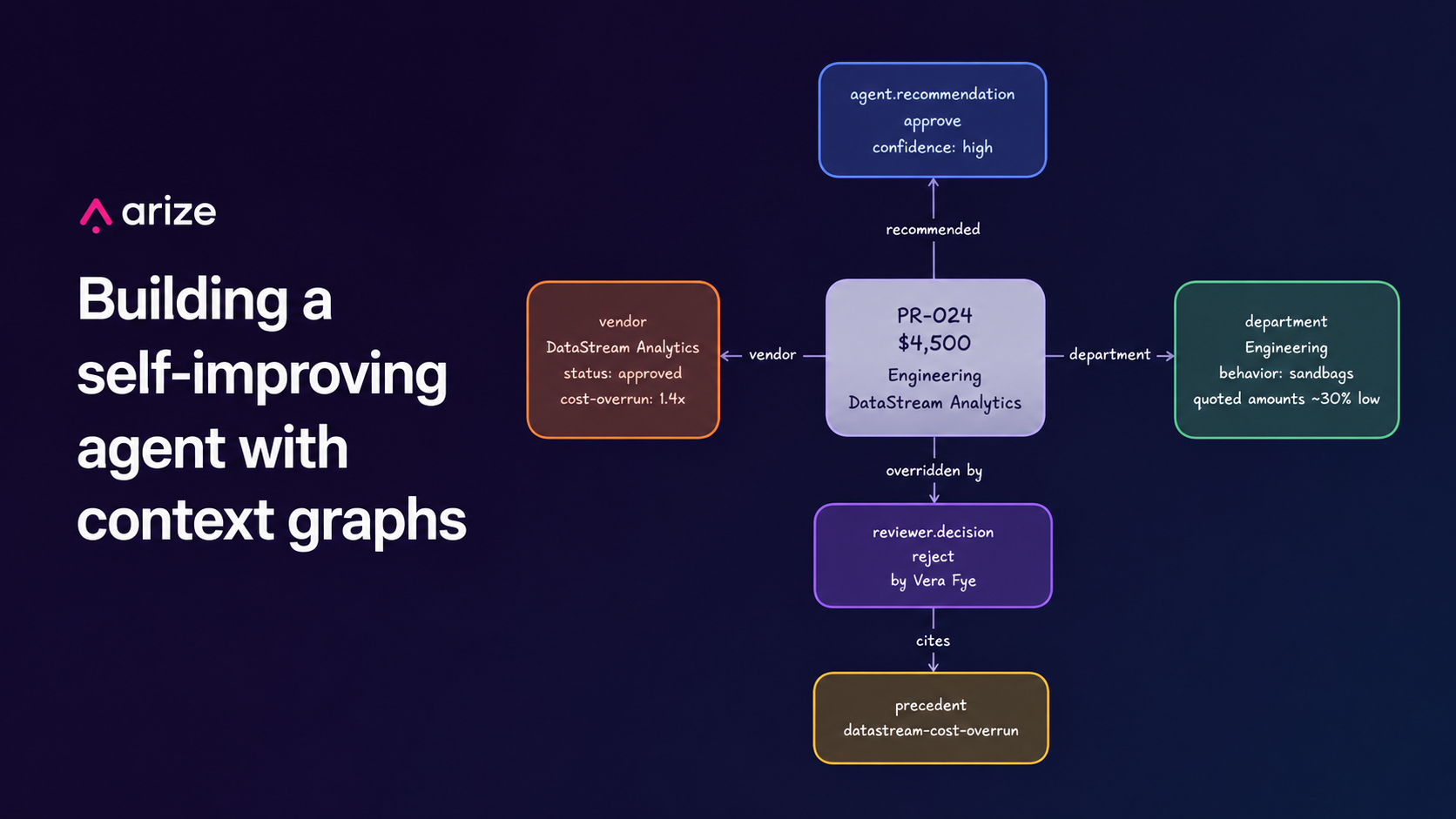
The architectural shift here is that we don’t have a logging table, we have a structured context graph:
- Nodes: requests, decisions, vendors, departments, precedents, dollar bands.
- Edges: the agent recommended X citing Y, the reviewer overrode to Z citing precedent P, vendor V is preferred over W under directive D.
Concretely, the graph lives in Arize AX. Every request becomes a session, every agent run is a process.run span, every Vera review is an override.run span, and the reviewer’s reasoning, precedent tag, and conditions sit on each override span as structured annotations.
There is no separate graph database. The graph is what you get when you join sessions to their annotations and treat each span as a node and each session-membership or annotation as an edge. The mining agent queries it back the same way: export spans by session, group by precedent, look for clusters.
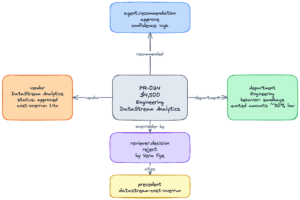
A row in a database tells you Vera said “reject”. The graph tells you Vera rejects DataStream Analytics requests under $5K when the justification doesn’t name a specific deliverable, because DataStream’s quotes inflate 40% in implementation. That second sentence is the asset. It’s a piece of decision logic the company has that none of its systems of record contain.
Mining the graph
130 sessions is enough to surface patterns in the human overrides. The job of the mining agent is to find them.
In this demo, the mining agent is an agent skill with a runner that invokes it via the Claude Agent SDK (or can be run manually through a coding agent like Claude Code). The skill leverages the Arize skills to extract traces and look for patterns.
Here are some of the patterns the mining agent surfaces.
| Precedent | Count | Pattern | Why |
|---|---|---|---|
| marketing-panic-buy | 14 | always reject | Marketing keeps buying single-campaign tools that get abandoned after launch. |
| customer-success-understaffed | 14 | always approve | CS is chronically understaffed; their urgent requests are usually genuine. |
| datastream-cost-overrun | 14 | mostly reject | DataStream’s quotes inflate ~40% on implementation. |
| vertex-march-outage-goodwill | 8 | always approve | Vertex extended emergency pricing during the March outage; Vera carries it as credit. |
| cloudbase-cto-relationship | 7 | never reject | The CTO has a personal relationship with CloudBase’s CEO. |
| cfo-vendor-consolidation | 5 | reject (3), approve (2) | Q2 directive: consolidate to one vendor per category. |
The first five rows are surfacing institutional knowledge. The process documents that the procurement agent uses don’t have any detail about the customer success team being understaffed, or the CTO’s relationship with CloudBase’s CEO. By mining the overrides, we’re converting that institutional knowledge into data that can be fed back to the agent.
The last row is also interesting. This directive is already returned by the check_policy tool on every single tool call, but appears to be ignored. The agent has the text in front of it and still ignores it. The mining report calls this out as a meta-finding:
“the policy is present in the tool output but invisible in the agent’s output”
Vera is catching documented process issues where the agent failed to follow its rules. That’s a different shape of fix: not “teach the agent something new” but “make the agent surface what it already knows.”
Fix the agent using the context graph
The mining agent is built on skills invoked via the Claude Agent SDK. It sits in a harness that extracts traces, mines patterns, and proposes updates to the system prompt instructions for the procurement agent and to the policy documents. No new tools are added, instead the same lookups return richer data.
The ground truth for the loop comes from Vera’s overrides. Where the agent agreed with her, that’s a known-correct answer. Where she overrode, her decision is the correct one. Every variant we run gets scored against the same 130 requests, and the score is how often it matches Vera. We iterate until the score stops climbing.
Rather than change the demo app’s source, our mining agent writes its proposed updates into an experiments folder, and the procurement agent picks them up at startup via an environment variable. Each cycle gets its own Arize AX project, and its own score against Vera’s baseline.
Cycle 1
We pointed the mining agent at the 130 baseline traces and Vera’s 60 overrides. It proposed the following changes:
- Two procedural rules added to the agent’s instructions. Cite the Vendor Consolidation Directive by name whenever the vendor comes back as not listed, and drop confidence to medium whenever the recommendation is flag-for-review.
- Vendor policy updates. Set a 1.4× cost-overrun factor on DataStream (reject-by-default with three carve-outs), a “March-outage goodwill” credit on Vertex (approve in the $5K to $50K manager-approval band), and a “never reject, flag-don’t-reject” CTO-relationship credit on CloudBase.
- Department policy updates. Marketing and Sales get a panic-buy reject rule: when the request is a tool, license, or plugin tied to a single campaign with no recurring-revenue case, reject regardless of amount or vendor status. Customer Success gets an understaffed-approve rule: their urgent requests are usually genuinely urgent, so approve in the manager-approval band when urgency is urgent or emergency, or when the justification mentions understaffing or a migration. Engineering gets a sandbag-floor: their quoted amounts run ~30% low in practice, so treat the figure on the request as a lower bound rather than the actual spend.
These suggestions need a human review pass before they ship to production. Some belong in the permanent process documents. Others, like the note that Customer Success is currently understaffed, capture this quarter’s reality and probably belong in a time-boxed config rather than the long-term policy.
Running the agent with these updates gives a better result:
| Agent decision | → | Vera decision | Status | Baseline | Cycle 1 | Δ |
|---|---|---|---|---|---|---|
| approve | → | approve | unchanged | 44 | 55 | +11 |
| approve | → | reject | changed | 10 | 2 | −8 |
| approve | → | flag-for-review | changed | 3 | 1 | −2 |
| reject | → | approve | changed | 5 | 8 | +3 |
| reject | → | reject | unchanged | 26 | 42 | +16 |
| reject | → | flag-for-review | changed | 0 | 0 | 0 |
| flag-for-review | → | approve | changed | 27 | 13 | −14 |
| flag-for-review | → | reject | changed | 15 | 7 | −8 |
| flag-for-review | → | flag-for-review | unchanged | 0 | 2 | +2 |
| Total agreements | 70 | 99 | +29 | |||
| Total disagreements | 60 | 31 | −29 |
Our agent now has 76.2% agreement with Vera’s original overrides. Not perfect, but closer. Nothing about the agent’s source code changed. We just gave it back what Vera knew.
Cycle 2, 3, and 4
We ran the same cycle three more times. Each pass moved the agent closer to Vera’s baseline, but the moves shrank: cycle 2 added 6%, cycles 3 and 4 added less than one between them. The agreement curve flattened around 83%, which is the diminishing-returns shape any loop of this kind settles into.
What changed across the four cycles was the shape of the work. Cycle 1 was teaching: handing the agent rules it didn’t have. The biggest single jump in the next three cycles, cycle 2’s +6%, wasn’t a new rule at all. It was an explicit allowlist telling the agent when it was allowed to flag for review. That one change resolved 22 of the 31 over-flag disagreements from cycle 1. The agent already had enough information to make those calls without escalating. It just lacked permission.
The standard instinct when an agent is wrong is to add more context, more rules, more examples. The fix here was the opposite. From cycle 2 on, the work was tuning rather than teaching: sharpening the edges of rules that were already there. An over-cautious agent doesn’t need more rules. It needs to know when it’s allowed to decide.
The general pattern
Strip out the procurement specifics. The same seven steps ran every cycle:
- Run your agent, and get humans to review with their institutional knowledge
- Capture the full context graph: agent decision, its reasoning, the human override, the reviewer’s reasoning, all as traces in the same session
- Extract the traces for both the agent and the human review
- Look for patterns in the agreements and disagreements
- Update the agent in a sandbox and re-run it
- Validate against the previous human reviews, or run another review pass
- Iterate until the curve flattens
The agent is unlikely to ever hit 100% alignment with a competent human. Some of that ceiling is irreducible: humans aren’t perfectly consistent with themselves either. In our demo, the simulated reviewer Vera flipped direction on the CloudBase cluster between cycles, citing the same precedent both times. The judgment calls at the edges don’t compress cleanly into rules, no matter how many cycles you run.
Push too hard on one sample set and you overfit. The honest version of this loop is continuous, not one-and-done. Vendors get acquired, policies change, and last quarter’s institutional knowledge becomes this quarter’s open question. The loop has to run against fresh traces on a cadence, or you’re just measuring a snapshot.
The pattern holds anywhere an agent runs against a policy and humans run against reasons: sales lead routing, support triage, content moderation, fraud review.
The seven steps above are what it looks like to treat the gap between policy and reality as the signal it is. Most teams collect the same data and throw it away.
Don’t throw your data away
The full demo is at github.com/Arize-ai/context-graphs. Set up an Arize AX account, run it end-to-end, and watch your own version of the curve climb.
If you’re shipping agents into a real workflow where humans review them, you have the raw material already. The override sitting in a Slack thread, the comment correcting the AI’s suggestion, the manual fix after the recommendation, those are signals your system gives you for free. Structure them as traces, mine them for clusters, and the curve climbs without retraining or fine-tuning anything. The hard part isn’t the data. It’s deciding to treat it as data.