








As AI engineers, we believe in total control and transparency.
Just the tools you need to do your job, interoperable with the rest of your stack.
The continual learning platform for agents
The AI engineering platform for self-improving agents.
Trace. Eval. Learn.
Powering the world’s leading AI teams






















1 Trillion
spans per month
1 Billion
evals per month
5 Million
downloads per month
Arize runs your continual learning loop
The platform that turns production signals into better agents.
Arize AX: The Agent Experience
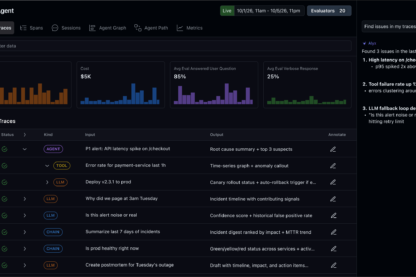
Agent debugging needs end to end workflows
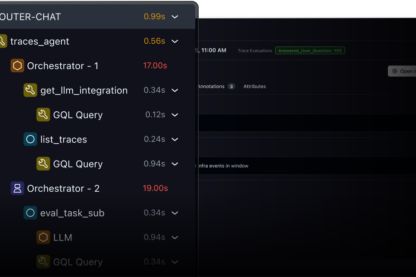
01 - Observe
What did my agent actually do?
Trace everything from the team who founded OpenInference - the leading open standard for GenAI observability.
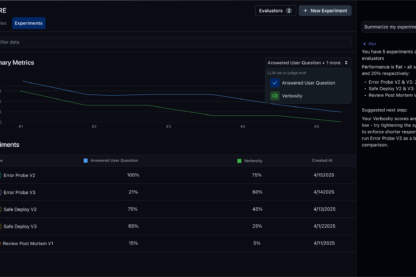
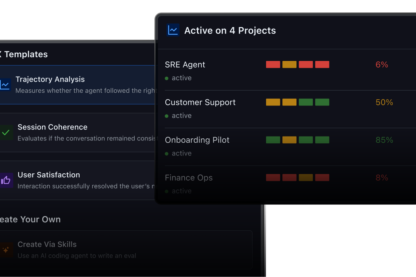
02 - Evaluate
Is my agent getting better or worse?
The most comprehensive eval framework in the market. Run span, trace, and session evals that run at scale.
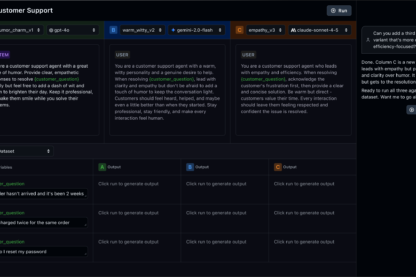
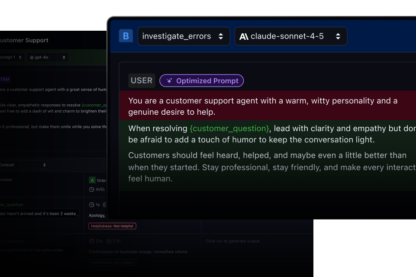
03 - Improve
Will this fix actually make things better?
Test prompts and harnesses faster before deploying to production.
Built for AI engineers
Infrastructure for self-improving agents
Build, evaluate, and improve your agents.
Agent Skills
Agent-first debugging for coding agents
Agent-native development
Run agent-native workflows across Cursor, Claude Code, OpenCode, and beyond to debug, evaluate, and improve agents faster.
View Docs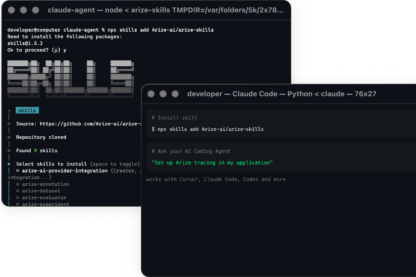
Alyx
Your AI engineering agent
Debug your agents with Alyx
Like Cursor or Claude Code, but for AI engineering. Alyx runs evals, debugs issues, and improves your agents. Give it a problem. It fixes it.
View Docs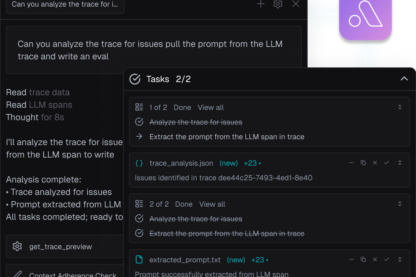
adb
The datastore for GenAI traces
The most scaled platform to store agent trajectories and context.
ADB stores in open formats to connect natively to BigQuery, Databricks, or Snowflake via DataFabric.
View Docs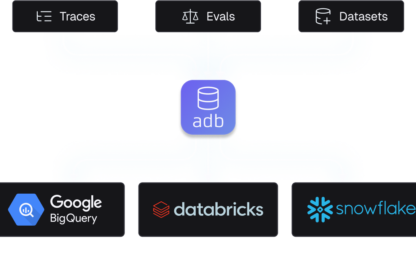


Open Source
Built on open source & open standards.
Host locally. Trace every LLM call, run evals, and keep control of your data with the leading open-source eval and observability tool.
The open-source leader in GenAI semantic conventions. Built on OpenTelemetry. Instrument once, no proprietary trace format.
Created by AI engineers, for AI engineers.
"Arize has been a strong partner in helping us operationalize Al workflows and demos quickly."
Huayi Li
Principal Machine Learning Engineer | AtlassianGet the latest on AI & Observability
Sign up for our newsletter, The Evaluator—and stay in the know with updates and new resources:

FAQ