

Agent Frameworks
AI agents have started settling into recognizable shapes. AI agent frameworks have matured, with foundational model labs having their own in-house agentic frameworks like OpenAI SDK and Google ADK, alongside established players shaping this space, such as LangGraph and CrewAI. In this article, we explore operational behaviors for these frameworks and which ones are the best for different types of use cases. We shall also explore how these platforms can be measured to ensure the maximum ROI by using established and tracing techniques. Choosing the right framework helps you ship a reliable, fast MVP and gives you the observability and clarity needed to understand how your agent behaves in production.
This post is authored by Aryan Kargwal, PhD at PolyMTL
What is an AI Agent Framework?
An AI agent framework acts as the control layer around the model. It establishes the order of operations, determines when to invoke a tool, manages state changes, and directs each step according to clear rules. The agent follows a defined process instead of drifting into ad-hoc behavior.
It also determines how the agent interacts with external systems and stores work in progress. You get a predictable path for execution instead of wiring separate parts by hand. This keeps behaviour steady across environments and gives you a clean surface for debugging when issues show up.
Key Components of an AI Agent Framework
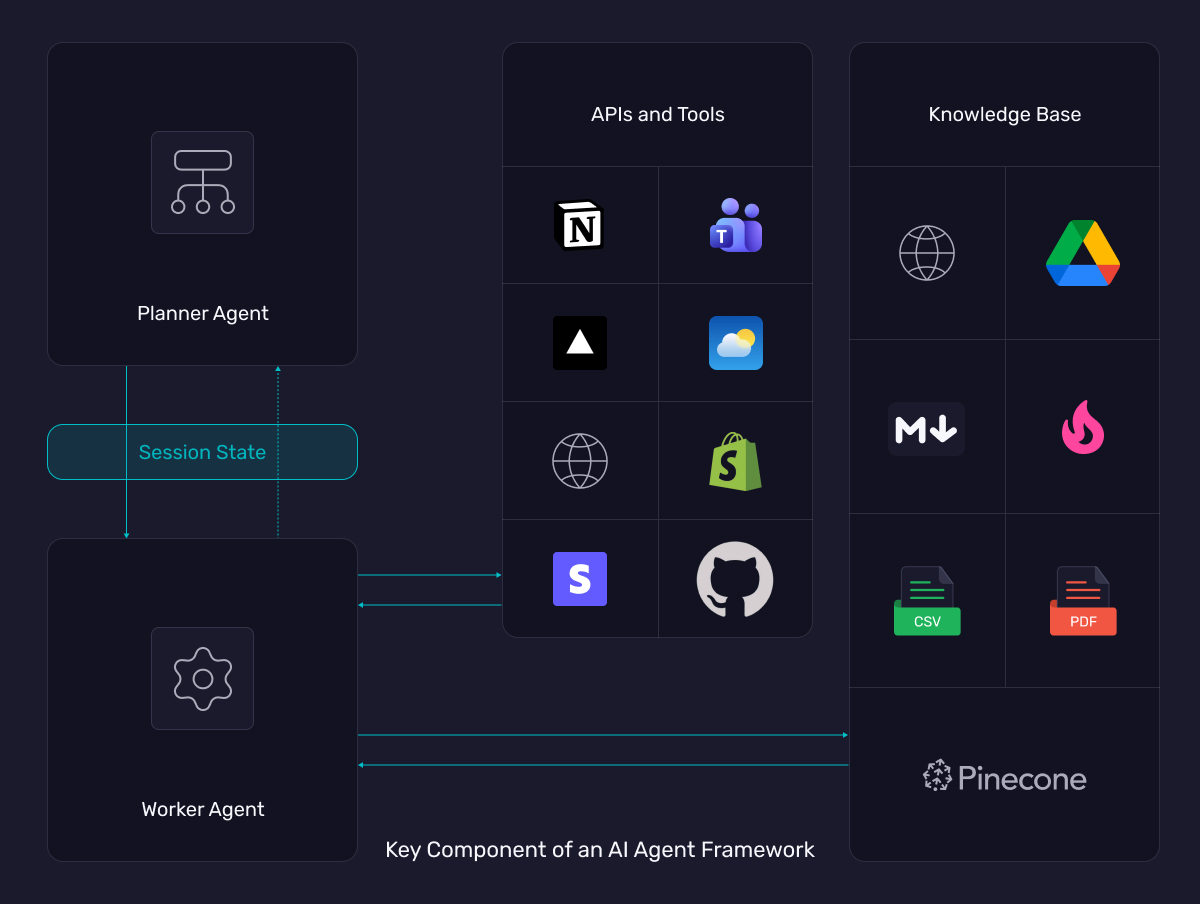
Agent frameworks rely on a small set of core components that guide how work moves through the system. These parts define how an agent decides what to do, executes steps, interacts with tools, stores intermediate results, and exposes a surface for measurement.
- The planner: Chooses the next step, sets the order of execution, and keeps the agent on a steady track.
- The worker: Carries out the step the planner selects and triggers the tool or model operation required for that moment.
- The session state: Stores the values and actions the agent produces along the way so it can continue a task with the right context.
- The APIs and Tools: Routes the agent’s request to the API or service it needs and returns the result in a usable form.
- The evaluation or testing hooks: Record each action as traces and give you points to inspect behaviour or measure output quality.
Key Metrics to Measure your AI Agent
A few signals tell you whether an agent runs well under real use. These metrics cover correctness, speed, stability, tool reliability, and the cost of completing tasks. Tracking them early gives you a clear picture before you start scaling or tuning behavior.
| Metric | What it Measures | Why It Matters |
| Correctness and output quality | How often does the agent produce the expected result or reach the right state | Shows whether the workflow works at all and keeps you from shipping an agent that answers confidently but wrong |
| Latency across each step | Time spent on planning, tool calls, and execution | Helps you see slow points so you can avoid delays that stack up during multi-step tasks |
| Tool success and failure rates | How often do tools return usable results versus errors | Reveals weak integrations or unstable APIs before they cause inconsistent behaviour |
| Looping or stuck behaviour | Cases where the agent repeats steps or never exits a state | Prevents runaway runs, wasted cycles, and user-facing stalls |
| Context rot over time | Whether the agent keeps or loses important information across steps | Helps you detect when memory or state breaks the workflow |
| Cost per successful task | Total spend needed to complete one correct run | Shows if the workflow is sustainable and whether model or tool choices need adjustment |
Top AI Agent Frameworks
CrewAI
CrewAI is built for running agent teams instead of a single loop. You define agents with clear roles and tools, then organize them into a “Crew” that moves through a workflow. Each agent handles a narrow task, and the framework coordinates the handoffs so you don’t wire that routing logic by hand.
You set each agent’s goal, configure how they interact, and use Flows to define the order of work. The runtime handles delegation, retries, memory sharing, and state transitions. It keeps the workflow steady even when a step branches or a tool returns something unexpected.
CrewAI exposes structured logs for agent messages, tool calls, decisions, and task outcomes. This gives you step-level traces to evaluate the multi-agent setup without modifying your workflow and helps you catch stalls, over-delegation, or repeated loops.
CrewAI works best when your use case benefits from multiple focused agents instead of one large controller. Suppose you’re building research pipelines, content systems, or workflows with several independent decision makers. In that case, CrewAI’s structure makes coordination cleaner and gives you a clear surface for inspection when issues show up.
How to trace CrewAI agents using Arize AX
Mastra
Mastra is a TypeScript framework for building agents through typed, workflow-driven development. Each step defines its inputs and outputs, and the framework executes them in sequence. This makes behaviour clear and reduces hidden errors because every transition is explicit.
Developers use Mastra when they want strict typing and a predictable task order. Steps fail fast if arguments don’t match the schema, which helps avoid inconsistent state or untracked failures. The workflow model also makes retries and error handling straightforward.
Mastra fits tasks where stability and repeatability matter. It works well for structured pipelines, automations, and multi-step processes. It is less suited for agents that need open-ended planning or flexible branching.
How to Trace Mastra using Arize AX
OpenAI Agents SDK
OpenAI’s Agents SDK is a thin runtime on top of GPT models rather than a heavy framework. It gives you a small set of primitives – agents, handoffs, guardrails, and sessions – and handles loops and tool calls while keeping conversation state in one place.
You define agents with instructions and tools, then compose them using handoffs or manager patterns instead of wiring your own orchestration layer. The code stays readable while still supporting multi-step and multi-agent flows.
Operationally, the SDK has built-in trace grading and hooks, so every run and tool call, plus each handoff, can be recorded. Arize’s OpenAI Agents cookbook shows how to ship those traces into Phoenix or AX to debug runs and score agent performance over time.
It is a strong fit when you already standardize on OpenAI models and want a supported way to ship agents fast without maintaining your own runtime. If you need provider flexibility or complex graph control, you will likely pair it with other frameworks.
How to trace the OpenAI Agents SDK
LangGraph
LangGraph is a graph-based runtime for building stateful agent workflows. You define nodes as functions and edges as transitions. The framework handles state, branching, and long-running flows so your agent can move through complex work without losing context.
Building with LangGraph feels closer to designing a system than wiring a single agent loop. You sketch the graph of steps, set conditions for each edge, and let the runtime handle checkpoints and recovery. That makes it a good fit for workflows that mix deterministic logic with agentic decisions.
Operationally, LangGraph focuses on durability and control. It offers built-in persistence, shared state across nodes, and human-in-the-loop pauses. It also streams updates as the graph runs, which pairs well with external observability like Arize AX. Arize’s LangGraph tracing guide shows how to instrument runs via the OpenInference integration.
LangGraph is strongest when you need branching workflows, multi-agent setups, or business processes that span sessions. It has more setup cost than a simple agent SDK, but in return, you get explicit control over each transition and a cleaner surface for debugging real incidents.
How to trace LangGraph with Arize AX
Google ADK
Google ADK is a code-first way to build structured, multi-agent workflows. You define a root agent, attach sub-agents, and wire tools and memory into clear steps so the workflow doesn’t drift. Each step has typed inputs and outputs, which keeps execution predictable even when the model improvises.
You route between agents, call tools through defined interfaces, and rely on session memory to keep context stable. The runtime logs every decision, tool call, and state change. When you connect it to Arize AX, you get full traces, tool spans, and step-level evaluations without extra plumbing.
ADK shines when you need branching logic, multi-agent patterns, or workflows that depend on strong memory and detailed telemetry. It’s a good fit for enterprise teams that want structure, observability, and a predictable runtime rather than a loose agent loop.
How to trace a Google ADK agent
AWS Bedrock AgentCore
AWS Bedrock AgentCore is the runtime layer for teams that want to run agents in production without handling infrastructure. You ship your agent as a container, and AgentCore takes care of autoscaling, routing, deployment, and model access. This keeps the operational path simple while letting you keep full control over your agent logic.
AgentCore works with any framework because it doesn’t enforce a planning or execution model. You can run Strands, LangGraph, CrewAI, Autogen, or your own custom stack. The runtime exposes a stable API surface, typed inputs, environment configuration, and IAM-based security, which makes it straightforward to plug into existing AWS setups and observability platforms like Arize AX.
Tooling integrates through the container itself. Your agent calls whatever services it needs — internal APIs, databases, or external tools — without constraints from the runtime. AgentCore focuses on keeping the service online and scaling with demand.
This option fits teams already invested in AWS or teams that want a managed path to production without changing the way they design agents.
How to Trace AWS Bedrock using Arize AX
Strands Agents
Strands is a lightweight, provider-agnostic SDK for building agents with a small footprint. You define tools as Python functions, pick a model provider, and Strands runs the loop that links model responses with tool calls. The setup stays simple, which helps when you want to move fast without pulling in a large framework.
It gives you full control over how actions unfold. You design the order of steps, decide when tools run, and shape the reasoning flow yourself. Smaller agents work with almost no overhead. When you need more structure, you add it directly in code instead of relying on framework rules. The library comes with a great number of tools, which are part of a larger ecosystem of contributors.
The SDK fits well in mixed model environments. Switching between OpenAI, Bedrock, Gemini, or a local model doesn’t require rewriting core logic. It also handles custom backends cleanly. If your stack already depends on internal APIs or services, Strands lets you wire them in without extra layers.
It stays easy to read, easy to change, and easy to embed inside existing systems. It works best for agents that need predictable, controlled execution rather than structured graphs or heavy orchestration. It gives you a direct way to build, deploy, test, and refine an agent without adopting a large ecosystem.
How to Trace Strands AI using Arize AX
LlamaIndex Workflows
LlamaIndex Workflows is an indexing and retrieval engine on top of language-model agents, making it easier to build retrieval-augmented, document-driven agents. Instead of only calling tools or APIs, agents can query structured indexes (documents, databases, knowledge graphs) managed by LlamaIndex, and use those results inside their reasoning. That means the “tools” surface isn’t limited to external APIs — it naturally includes internal knowledge bases and retrieval pipelines.
When you build with LlamaIndex Workflows, flows often combine retrieval + reasoning + tool calls: first fetch relevant context, then plan with the model, then call tools or generate output. This hybrid of retrieval and LLM reasoning gives your agents grounding: output is tied to data, not hallucination. For teams working on document-heavy tasks, search, summarization, or knowledge-driven automation, this can reduce error rates and increase consistency.
Because the workflow is partially deterministic (you control index queries, retrieval steps, and reasoning + tool calls), debugging and evaluation become more structured than with free-form chat agents. Although LlamaIndex doesn’t enforce a strict orchestration engine like a graph framework.
LlamaIndex works well when your agent depends on retrieval or cyclical reasoning. It lets the agent pull fresh context from indexed data instead of relying only on prompts. With Arize AX’s LlamaIndex tracing, those retrieval steps show up beside model and tool calls, so you can see which queries fired, how long they took, and how they shaped the final output.
Autogen
AutoGen is built around the idea of coordinating multiple chat-based agents that speak to each other to complete a task. You define agents with roles, tools, and functions, then use AutoGen’s conversation engine to control how they exchange messages. The framework handles the back-and-forth, tool routing, and stopping conditions so you don’t write that logic yourself.
One agent plans, another executes, and extra workers can step in for retrieval, code execution, or validation. The control you get over message flow and termination rules keeps the conversation from spiraling or looping.
AutoGen exposes each message, tool call, and interaction, which you can trace through Arize AX using the OpenInference integration. You get a clear view of where agents stall, repeat work, or fail to coordinate. AutoGen works best when your workflow benefits from multiple focused agents instead of one monolithic controller.
How to trace AutoGen using Arize AX
Which AI Agent Framework is the Best for You?
Agent frameworks look the same on the surface, but the way they work is very different.
- The controller and worker loops decide how an agent advances through a task.
- The API and tool-calling path determines how external systems respond under load.
- The memory layer shapes how well the agent keeps context and avoids context rot.
These three parts decide which framework fits your use case and how it behaves once real traffic hits it.
Orchestrator and Worker Behavior
Agent frameworks differ most in how they decide the next step and how they execute it. With the core thinking still that of an orchestrator and worker-type agent, which can be a hybrid system depending on the framework. How these two parts interact greatly determines whether the system feels stable, predictable, and easy to debug once it has been deployed.
| Framework | Controller Behaviour (How control decisions are made) | Worker Behaviour (How actions run) |
| OpenAI Agents SDK | The runner owns the loop. It picks the next step based on LLM output, handoff rules, and session state. No custom routing logic. The behaviour itself runs on the Responses API running in tandem with OpenAI. | Workers are sub-agents or tools. Each invocation is one atomic step: model call, function call, or handoff. No parallelism. |
| LangGraph | Control is the graph. Nodes fire based on conditions you define. Edges determine branching, retries, and exits. The persistence layer allows this to work by defining checkpoints that then eventually become a part of the graph execution. | Workers are node functions or subgraphs. They run deterministically and can branch, pause, or emit commands for child graphs. |
| LlamaIndex Workflows | Control sits in your workflow code. The agent loops through “retrieve → reason → act” steps you define, rather than a strict graph engine. | Workers are retrieval calls, model calls, and any custom tools you wire in. Steps run sequentially, and you manage looping or branching yourself. |
| Google ADK | Root agent evaluates the state and routes to sub-agents. Typed steps enforce strict transitions. Controller acts like a workflow engine with guardrails. | Workers are structured in steps with typed IO. Each step is validated before and after execution. Strong bias toward predictable output. |
| AutoGen (Microsoft) | The conversation manager selects the next speaker based on the group chat state. Control emerges from dialogue patterns rather than explicit routing. | Workers are agents that respond to messages. Each response can call a tool, request validation, or hand off implicitly via conversation turns. |
| CrewAI | Manager agent plans, delegates, and validates. The controller decides when roles switch and how tasks flow between agents. Feels like a small PM. | Workers are role agents with narrow responsibilities. They execute tasks, update shared context, and return results for validation. |
| Mastra | Workflow defines control. Steps run in the declared order, with branching when configured. Typed transitions catch bad inputs early. | Step functions run as workers with strict IO. Retries and errors are explicit and handled at the step level. |
| AWS Bedrock AgentCore | No built-in controller. Your containerized agent defines all planning and sequencing. AgentCore only executes and scales it. | Workers are your code paths. Each request triggers your model calls, tools, or logic exactly as written. |
| Strands Agents | The agent loop drives control. You decide when to call the model, when to run tools, and how the flow advances. | Tools and model calls act as workers. Each runs one at a time with no built-in branching or parallel execution. |
API and Tool-Calling Behavior
Most agents don’t talk to a hundred tools. In practice, they hit a handful of APIs, sometimes through n8n or a custom backend. The framework decides how these calls are wired, how arguments are validated, and where errors surface. That behaviour matters more than raw tool count.
| Framework | How tools and APIs are wired | Behaviour you should expect |
| OpenAI Agents SDK | Tools are registered as functions or OpenAI Actions, then attached to agents. You can configure them in code or through the Agents Playground, which is handy for quick iteration with product or ops teams. | Tool calls run inside OpenAI’s runtime. You see a clean schema, arguments, and responses, but less control over low-level retries. For more complex stacks, teams often front tools with a single backend or n8n flow. |
| LangGraph | Tools are normal Python or TypeScript functions wrapped as nodes. Each tool node can call external APIs, internal services, or a gateway that fans out to multiple systems. | Failures and retries stay local to the node. You decide how to handle timeouts or fallbacks. Many teams expose one internal API per node instead of wiring raw SaaS tools directly into the graph. |
| LlamaIndex Workflows | Tools sit around retrieval: the agent queries indexes, vector stores, or structured sources first, then calls APIs or functions from your code when needed. | Retrieval and tool calls share one loop. Behaviour leans heavily on index quality, query design, and how you chain tools after context is fetched. |
| Google ADK | Tools are declared with typed signatures and can target Vertex AI tools, HTTP endpoints, or internal services. The SDK enforces schemas and validates inputs and outputs. | Tool calls produce structured telemetry by default. You get clear spans for each call, which makes it easier to trace failures or slow vendors. In heavier stacks, ADK often points at an internal gateway rather than vendor APIs directly. |
| AutoGen (Microsoft) | Tools are Python functions or wrappers that agents can call inside a chat turn. Each agent can have its own tool set, and tools can perform API calls, code execution, or retrieval. | Tool calls happen inside the dialogue. If a tool struggles, the conversation can stall or loop. Many teams hide real systems behind one tool entrypoint to keep the surface area small and easier to guard. |
| CrewAI | Tools are attached to agents through config or code. They can rely on LangChain tools, HTTP requests, or custom Python functions that talk to upstream APIs and services. | Manager agents decide when to call a tool versus another agent. Tool-heavy crews often route everything through a small number of composite tools so that retries, auth, and vendor quirks live outside the CrewAI layer. |
| Mastra | Tools run inside typed workflow steps. Each step can call external APIs, internal services, or a gateway. | Calls stay predictable because each step enforces inputs and outputs. Errors surface fast and are easy to isolate. |
| AWS Bedrock AgentCore | Tools are not wired at the runtime level. Your agent calls APIs or backends directly from inside the container. | Behaviour depends entirely on your code. Retries, fallbacks, and failures follow whatever logic you implement. |
| Strands Agents | Tools are Python functions decorated for agent use. They can call APIs, databases, or external systems with no extra layers. | Calls run one at a time through the loop. No built-in routing or orchestration, so behaviour stays direct and easy to inspect. |
Memory Layer
Memory decides how long an agent can stay coherent. Frameworks differ in how they store session state, how they share context between workers, and where the actual knowledge base lives. In practice, most teams lean on one RAG stack and pass pointers, not raw documents.
| Framework | How memory and session state work | How knowledge bases usually plug in |
| OpenAI Agents SDK | Sessions hold conversation history and tool results. Handoffs can filter context to keep runs cheap and safe. | Most teams front a single RAG or search service and expose it as one tool, not multiple raw KB calls. |
| LangGraph | State is stored as checkpoints keyed by thread or graph node. You can “time-travel” or resume from any point. | KB access is usually wrapped in dedicated nodes that call RAG services or vector DBs and return compressed answers, not full docs. |
| LlamaIndex | Memory lives in indexes and vector stores rather than long chat history. Sessions often re-query data instead of relying on a growing transcript. | Knowledge bases plug in as LlamaIndex indexes. Expect good grounding when data is clean, but sensitivity to stale, sparse, or noisy documents. |
| Google ADK | Memory ties into session objects and can use Vertex AI memory stores for durability and typed state. | ADK often points at Vertex Search, custom RAG APIs, or internal stores. KB access is just another typed tool with strict schemas. |
| AutoGen (Microsoft) | Each agent keeps its own chat history; the group chat transcript acts as shared context. | KB access is handled by tools or retrieval helpers. Most real setups hide RAG behind one or two tools to avoid bloating the transcript. |
| CrewAI | Crew state combines manager context and per-agent memory. You can configure different memory backends for short- and long-term state. | Knowledge bases plug in through LangChain-style tools or custom retrievers. Teams usually centralize onto one RAG pipeline exposed as a small tool surface. |
| Mastra | Mastra supports “Memory” as a built-in feature along with agents, workflows, RAG, and tools. | Mastra supports RAG and Memory integration as first-class elements of its agent/workflow system. |
| Amazon Bedrock AgentCore | Offers both short-term memory (raw events/conversation history per session) and long-term memory (persisted across sessions, extracting user preferences, etc.) to enable context awareness and personalization. | KB or knowledge-base access is generally managed by treating memory + retrieval as tools/services. AgentCore handles the underlying storage and retrieval infrastructure, decoupling knowledge retrieval from raw DB calls. |
| Strands Agents | Provides session management via built-in session managers (e.g. file system or S3) that persist conversation history, agent state (key-value store), and tool results; this supports both single-agent and multi-agent systems. | Strands can integrate with Amazon Bedrock AgentCore Memory (or similar) via a session manager wrapper. When used together, you get short-term + long-term memory, exposed as tools. |
FAQs
What is the best open-source AI agent framework?
There’s no single winner; Mastra is great for TypeScript, and there’s also CrewAI, LangGraph, CrewAI, AutoGen, and other open-source options each fit different control-flow styles and workloads.
What is the best free AI agent framework?
Most major frameworks are free; the best one is the one that matches your routing needs, tool surface, and memory setup.
How can I start learning about AI agents?
Start with a simple tool-calling agent, then experiment with frameworks like OpenAI Agents SDK or LangGraph to understand how real control loops and state behave.
Do AI agents need memory?
Yes, without session state or scoped memory, the agent loses context and breaks on anything longer than a single call.