



If we were to give the year 2025 an AI-appropriate appellation, it would probably be ‘the year of the agents.’ Building atop the startling advances in generative language and image models, there is now an ecosystem of agentic workflows exploding into existence, powering tectonic shifts in the way day-to-day work is handled in industries as diverse as education, healthcare, finance, and software engineering.
But managing the inputs and outputs of these models – figuring out what gets them to work well under different conditions, scaling reliably, handling regulated data, etc. – is an enormous challenge. That’s why there’s a new suite of tools being developed to observe how models respond to different prompts, how they behave at different points in a pipeline, and how they change over time.
This piece is targeted at AI-first engineers and product managers seeking more robust and repeatable ways of taming the complexity (and utilizing the power) of AI agents. Let’s dig in!
Why Does This Matter?
There are a few reasons why a comparison of this kind is especially timely. An obvious one is the staggering proliferation of cutting-edge foundation models. In the few short years since the release of ChatGPT, generative AI has become all but ubiquitous in technical knowledge work, meaning that it’s become especially important to think about the prompt optimization techniques we all use to get useful output from the inscrutable matrices of floating-point numbers.
Another is that LLMs present unique challenges around prompt versioning, testing, and optimization. Because the underlying models are stochastic, there’s a non-trivial challenge associated with figuring out what ‘good’ and ‘bad’ performance even means, to say nothing of hallucinations, bias, toxicity, and so forth.
For these reasons, it’s worth compiling a list of the major tools available to work with prompts, version them, optimize them, and evaluate their efficacy.
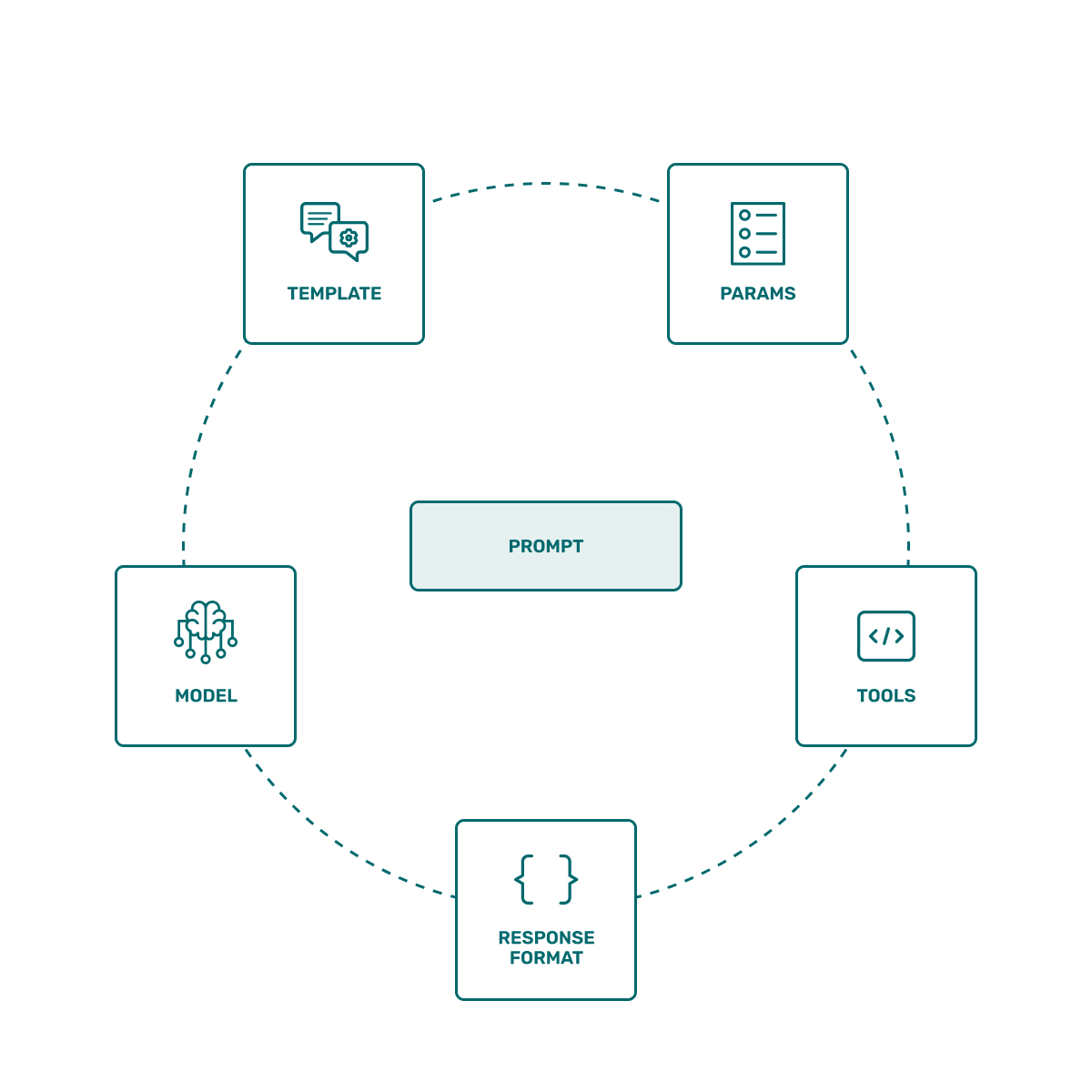
How are the Prompt Testing Platforms Evaluated?
Several dimensions were used to assess the platforms listed below. Because we prize portable evaluations and know that many teams want to maintain control over their performance data, we looked for platforms built on standards such as OpenInference and OpenLLMetry, as this practice makes it easier to adapt as the space changes. Closed platforms might still be included, if they stand out enough along some other dimension.
For the same reason, we prioritized offerings that are highly interoperable, able to interface with different model providers, frameworks, and ecosystems without extensive updates and rewrites. With new models dropping weekly and an unrelenting pace of development being set across the entire industry, it’s important for an observability and optimization tool to grow alongside your team.
Speaking of growth, we also looked for tools that are suitable for the initial, exploratory phase as well as the robust, enterprise-deployment phase. It should be relatively easy to throw together an initial trace to get a read on how a workflow is functioning, but also to then scale up to much larger volume analyses.
Finally, we like a prompt testing platform to have both self-hosted and managed varieties. Some organizations operate under regulatory or security constraints that prevent cloud-only deployment; platforms offering both options provide flexibility for different governance environments and risk profiles.
Tools and Prompt Optimization Platforms
With all that having been said, the following are the tools and platforms we think offer the services, integrations, and adaptability needed by teams trying to wrangle high performance out of modern LLMs. We’ll get into more detail in the sections below, but in brief, the standouts include (listed in alphabetical order): Arize AX, Arize Phoenix, DSPy, Fiddler AI, Helicone, PromptLayer, Prompthub, and Promptmetheus. Together, these were the ones that held the most promise for those wanting to peer into the black box of their LLM tooling, offering a mix of platforms targeted at enterprise and small teams, open-source and managed options, scalability, and functionality.
Arize AX
Representing the most comprehensive observability platform on the market, Arize AX is an enterprise-grade offering built from the ground up on open standards and requiring just a few lines of code to set up.
Here, for example, is the process of setting up a basic evaluation.
# install dependencies
pip install arize openai pandas 'arize-phoenix[evals]'
# Create the client
from arize.experimental.datasets import ArizeDatasetsClient
arize_client = ArizeDatasetsClient(api_key=ARIZE_API_KEY)
# Create the dataset (or add your own)
import pandas as pd
from arize.experimental.datasets.utils.constants import GENERATIVE
# Example dataset
inventions_dataset = pd.DataFrame({
"attributes.input.value": ["Telephone", "Light Bulb"],
"attributes.output.value": ["Alexander Graham Bell", "Thomas Edison"],
})
# Create Arize dataset
dataset_id = arize_client.create_dataset(space_id=ARIZE_SPACE_ID, dataset_name = "test_dataset", dataset_type=GENERATIVE, data=inventions_dataset)
# Define a task
import openai
def answer_question(dataset_row) -> str:
invention = dataset_row.get("attributes.input.value")# ex: "Telephone"
openai_client = openai.OpenAI()
response = openai_client.chat.completions.create(
model="gpt-4.1",
messages=[{"role": "user", "content": f"Who invented {invention}?"}],
max_tokens=20,
)
return response.choices[0].message.content
# Define your evaluators
from arize.experimental.datasets.experiments.types import EvaluationResult
def is_correct(output, dataset_row):
expected = dataset_row.get("attributes.output.value")
correct = expected in output
return EvaluationResult(
score=int(correct),
label="correct" if correct else "incorrect",
explanation="Evaluator explanation here"
)
# Run the experiment
arize_client.run_experiment(
space_id=ARIZE_SPACE_ID,
dataset_id=dataset_id,
task=answer_question,
evaluators=[is_correct], #include your evaluation functions here
experiment_name="basic-experiment",
concurrency=10,
exit_on_error=False,
dry_run=False,
)
Good For
- Arize AX is compatible with any framework and model. Community edition of the product includes most features needed for prompt testing, experimentation, evaluation.
- It’s built with scalability in mind, with the associated Arize Database (adb) achieving sub-second queries even on hundreds of millions of spans.
- It’s built for the enterprise, with robust RBAC, SOC 2 controls, advanced encryption, and air-gapped deployment options available from the beginning.
- AX comes bundled with an AI assistant designed to help teams spot problems and repair gaps quickly.
Limitations
- Getting all relevant telemetry data does require some initial setup (via OTel or the Arize SDK).
- AX is a managed service with strong opinions about how data is stored and accessed. For domains that operate under strict data residency requirements, like finance and healthcare, an on-prem AX deployment or Arize Phoenix may offer a better self-hosted option.
Arize AX has a number of specific features aimed at making prompt optimization and testing easier, including:
- Version control on different prompts – As time goes on you may find that you want to track versions of a prompt, rolling back changes if you see degradations in performance.
- Prompt learning refers to the practice of improving on prompts by testing their effectiveness against evaluations and making gradual tweaks. Arize offers support for this process natively.
- Test prompts on multiple spans or traces at once – The Arize playground gives you the ability to check several prompts against relevant data at once, speeding up development.
- AI-driven prompt writing – Alyx, Arize’s built-in agent can offer general feedback on a prompt, or help you with more target requests (i.e., ‘enhance clarity,’ ‘adjust the tone of this’).
- Support for testing agent tool calls, images and multimodal inputs, versioning, experimentation, evaluation, and monitoring cost and latency for the usage of models across different providers.
Arize Phoenix
Arize’s Phoenix platform is a powerful, Otel-native, open-source tool for observing and evaluating LLMs. It has options for self-hosting, leaving control of your stack in your hands.
Here’s sample code for registering a tracer with Phoenix (we’ve omitted the installation and set up here); as you can see, it’s very straightforward:
from phoenix.otel import register
tracer_provider = register(
project_name="my-llm-app",
auto_instrument=True,
)
tracer = tracer_provider.get_tracer(__name__)
Good For
- Arize Phoenix has support for asynchronous workers, scalable storage, and a plugin system out of the box, making it production-ready from the start.
- Because it’s open source and easy to use, Phoenix is a great choice for experimenting before deciding whether you want to use a managed solution later on.
- Supports debugging complicated workflows, such as those built on RAG and agents, without any extras.
- Phoenix makes it easy to integrate evaluations into your analytics process.
Limitations
- You’ll need to manage the associated infrastructure yourself, so Phoenix may not be suitable for teams without the requisite experience.
- To access the full suite of security and access functionality (such as those pertaining to SSO, RBAC, etc.) requires upgrading to Arize AX.
Arize Phoenix has a number of specific features aimed at making prompt optimization and testing easier, including:
- Prompt management – Prompt management allows you to create, store, and modify the prompts you use to interact with LLMs, and, when done programmatically, it becomes easier to improve, reuse, and experiment with variations.
- Prompt docs in code – With Phoenix as your prompt-management backend, prompts can be handled as code with our Python or TypeScript SDKs, making them feel and act like the rest of your tech stack.
- Span replay – Phoenix’s Span Replay functionality allows you to return to a spot in a multi-step LLM chain and replay a single step to see if you can achieve a better result.
- Similar to AX, offers support for versioning, experimentation, evaluation, and monitoring cost and latency for the usage of models across different providers.
DSPy
Though one could classify DSPy (short for “Declarative Self-improving Python”) under ‘Prompt Management,’ it’s clear the team is attempting to make it into something grander, a tool that, according to their documentation, amounts to an entire “…framework for building modular AI software.” DSPy is meant to take AI architects and AI orchestration engineers from fiddling around with prompt strings to building real software around LLMs.
You’ll note that this shift in mindset is reflected in the slight syntactic differences in installation and configuration:
# pip install -U dspy
import dspy
lm = dspy.LM("openai/gpt-4o-mini", api_key="YOUR_OPENAI_API_KEY")
dspy.configure(lm=lm)
Good For
- Severs the link between choices about specific foundation models and choices about broader software architecture, making it possible to build more maintainable systems.
- Offers optimization packages, such as SIMBA (Stochastic Introspective Mini-Batch Ascent), able to tune both prompts and the underlying models they interact with.
- Supports a robust ecosystem (i.e. for DSPy tracing) that furthers open-source research on AI and AI-first software.
Limitations
- DSPy is not a toy; though it isn’t that complicated, it will take some time to learn both the syntax and the broader shift in mindset required by DSPy. To those unfamiliar with ML pipeline design and programmatic prompt optimization, it can be heavy sledding.
- It comes with a small amount of optimization overhead. Though the compiler-style approach to re-optimizing weights through iterative updates favored by DSPy is powerful, it can be compute- and resource-intensive.
- There are DSPy integration boundaries; though it interfaces with popular model APIs, it’s not a drop-in orchestration layer by itself.
- You may need to work with other offerings for more ambitious coordination work.
- DSPy might be overkill for early prompt optimization and prompt engineering work.
Fiddler
Fiddler AI offers an an enterprise-focused observability and monitoring platform built around traditional machine learning and those powered by newer large language models. Billing themselves as a unified stack for “agentic observability,” they offer insight into everything from sessions and agents to traces and spans.
Good For
- Fiddler AI covers a broad array of model types, including tabular machine learning, computer vision, and some workflows oriented towards LLMs and generative AI.
- It has strong monitoring and explainability capabilities, offering eagle-eyed engineers data drift, outlier detection, and analytics, along with diagnostics for fairness and bias.
- The platform is built for production, covering multi-cloud or on-premises deployment and secure environments of the kind used by governments and heavily-regulated industries.
- The platform has features for LLM-specific risks.
- It has plug-ins with existing infrastructure, data sources, model frameworks, and so on, meaning it obviates the need to build a whole new pipeline from scratch.
Limitations
- Given Fiddler AI’s breadth and focus on enterprise customers, for small, exploratory prompt-testing setups, it might be unwieldy.
- For the same reason, it’s probably overkill if your only purpose is prompt formulation and iteration.
- Since Fiddler AI is built around enterprise deployments and secure environments primarily around traditional ML, there’s often technical overhead involved that’s prohibitive for leaner teams. If you only need a simple tool for testing prompt variants, the ratio of value to time invested may be less favorable.
Helicone
Helicone is an AI app debugging platform for teams working with large language models, with support for logging, versioning, experimentation, and monitoring cost and latency for the usage of models across different providers.
Integration is straightforward, achievable with just one line of code:
from openai import OpenAI
client = OpenAI(
api_key=OPENAI_API_KEY,
base_url=f"https://oai.helicone.ai/v1/{HELICONE_API_KEY}"
)
Good For
- Helicone has sunk engineering work into making it a snap to roll out their platform; their documentation has samples showing how to start logging requests with single-line changes to a base URL.
- Helicone offers prompt version tracking, experiment comparison (of, say, multiple prompt variations across multiple models) and evaluation of prompt outputs.
- It’s designed to work with a bevy of LLM providers, rather than requiring you to confine your ambitions to the ecosystem of a single model provider.
- Because Helicone tracks usage metrics related to token counts, cost, and latency, monitors sessions and traces across multi-step workflows, and supports caching, it gives you ways to find and mitigate your cost sinks.
- Because Helicone operates under an Apache 2.0 open-source license and can be self-hosted via Docker and Helm, it may be compelling to companies concerned with privacy and compliance.
Limitations
- Helicone doesn’t bill itself as a deep “automated prompt-optimizer”; in contrast to certain other, dedicated prompt-engineering tools, in other words, Helicone can’t algorithmically generate new prompt variants for (at least not to the same extent).
- Reviewers have noted that its parameter tuning options are less comprehensive than competitors.
- The UI and feature set expose a depth that’s likely better-suited for technically-oriented teams; running custom evaluators or integrating evaluation sets may require coding.
- Even though there is support for self-hosting, full-scale enterprise deployment (especially for extremely high call volumes or multi-agent systems) may still require significant engineering lift.
- For teams whose primary need is very lightweight prompt testing, Helicone’s full suite may be too much compared to leaner options.
- While it supports multi-model and multi-provider workflows, advanced features like multi-agent orchestration or multi-agent graphs, deep prompt parameter tuning, or guardrail features may be far off on the roadmap or require specialized add-ons.
PromptLayer
PromptLayer is a popular platform designed to help teams track, version, test, and deploy prompts – and agents – through a straightforward, visual-first interface. Its purpose is to act as a layer between the code you’ve written internally and the model API calls being used throughout, capturing metadata, logging requests, and facilitating various prompt-heavy workflows.
Good For
- PromptLayer captures each API request in a searchable dashboard, along with relevant metadata and tracing capability.
- It offers tools allowing you to create prompt templates, version them, track changes, and compare usage across different versions.
- A key selling point of PromptLayer is that it enables team members (including non-engineers or people like AI product managers) to view prompt evolution, reuse templates, and monitor usage metrics.
- It focuses in particular on empowering subject matter experts, who are often the best-equipped to assess the quality of a model’s outputs.
Limitations
- PromptLayer is more geared toward prompt management and overall observability than deep, end-to-end automation of prompt optimization. If you’re focused on workflows that revolve around variant generation and automated tuning, other tools might offer more options.
- Because it integrates into code and captures metadata, you’ll get more out of PromptLayer if you have structured prompt workflows and consistent ways of using APIs, as against ad-hoc experimentation (though it might help with that too).
- For smaller teams, or very lightweight prompt testing, the full feature set may be overkill.
PromptHub
PromptHub is a prompt engineering platform aimed at managing prompts end-to-end, from discovery, versioning, testing, deployment, and sharing across a community. This last is worth underlining (literally and figuratively), as it’s so distinctive. PromptHub aims to be a kind of “Wikipedia for prompts” (WikiPrompt? PromptoPedia?), where teams and individuals collaborate on prompt development, share their templates, and work in tandem to test and iterate.
Here’s an image illustrating what PromptHub’s prompt versioning looks like, and it will be familiar to users of the Github process:

Good For
- PromptHub lets you host prompts privately (for your team) or publicly (for the community), track prompt versions, and manage deployment.
- Beyond storage, PromptHub offers features like automatic prompt generation, prompt iteration (wherein you refine prompts in collaboration with an AI offering feedback), and tools for prompt enhancement. It prides itself on building “prompt engineering best practices” directly into the interface, so you – theoretically – will never write a bad prompt again.
- Because there’s a community-driven element, you can discover prompt templates, benchmarks, and best practices, which can speed up your attempts at experimentation.
- PromptHub is a good tool for prompt engineering workflows that include both experimentation and team-wide prompt governance.
Limitations
- While PromptHub has good support for testing and iterating on prompt design iteration, it may not provide the heavy-duty observability or low-level logging provided by a dedicated monitoring platform. If you require deeper analytics around cost and latency, or hallucination monitoring or custom online evals, you might need add-ons or supplemental tools.
- Community-driven prompt sharing is a double-edged sword; while you do get access to many templates, you may also deal with varying quality, insufficient documentation (or no documentation at all), or templates that are insufficiently tailored to your particular domain.
Promptmetheus
Promptmetheus aims to be an IDE, designed to enable the composition, testing, optimization, and deployment of LLM prompts.
Good For
- Promptmetheus supports modular prompt composition, meaning you can break prompts into blocks and variants, mix and match as needed, test alternatives, and visualize how each variant behaves.
- The platform supports testing across different LLM providers, estimating cost and latency for each, and evaluating standard prompt performance metrics.
- Because it maintains version history for each prompt variant and allows shared workspaces, Promptmetheus may work for teams seeking a collaborative tool.
Limitations
- The interface and feature set are fairly rich, and might present a learning curve that’s relatively steep compared to simpler prompt-editing tools; users new to prompt engineering may need time to adopt it.
- While it handles prompt optimization well, if your workflow is almost exclusively focused on production monitoring of cost, drift, etc., you might still need to investigate observability tools.
Conclusion
In response to the growing complexity of AI systems, the prompt testing and optimization ecosystem has matured rapidly over the past year. What began as halting attempts to build simple tools for logging or comparing model outputs has changed, by imperceptible degrees, into landscape of observability stacks, experimentation environments, and governance frameworks of a bewildering variety.
All told, this means there’s a shift toward treating prompts, evaluations, and agentic workflows as first-class engineering artifacts.
Choosing between the platforms on offer will depend on your unique context. You may need enterprise-grade governance observability, or a robust community of enthusiasts who can offer feedback; you may need support for air-gapped on-premises deployment, or it may be more important for you to have structured optimization and programmatic pipelines.
Regardless, the context offered here will hopefully help you make the right decision.