



In our latest live AI research papers community reading, the primary author of the popular paper A Watermark For Large Language Models (John Kirchenbauer of University of Maryland) walked us through the thinking behind the paper, technical approach, and key takeaways.
The paper’s proposed watermark can be embedded with negligible impact on text quality, and can be detected using an efficient open-source algorithm without access to the language model API or parameters. It works by selecting a randomized set of “green” tokens before a word is generated, and then softly promoting use of green tokens during sampling.
▶️ Watch
Dive In
Listen To the Podcast
Key Takeaways On the Research
Several findings from this research stand out:
- Watermarking ≠ detection by vibes. It’s a statistical test you can run on text (or images) to decide whether a subtle, intentionally added signal is present.
- How it’s added (text): nudge the logits so “green” tokens are a bit more likely than “red” ones—enough to leave a pattern, not enough to change quality.
- How it’s found: recompute those green/red sets from the prompt and count how often generated tokens land in green; if it’s “too often,” flag it.
- Robustness is graded, not binary. Paraphrasing, editing, and mixing weaken the signal but don’t instantly erase it.
- Images, too. A related “tree‑ring” method perturbs diffusion noise in Fourier space; later you invert the process and look for the ring pattern.
- Cat‑and‑mouse is real. Watermarks can be learned by downstream models (they’re “sticky”), so spoofing/forgery must be considered.
- Practicality: Providers may run watermarks for their data hygiene even if they’re reluctant to expose public detectors.
How the Text Watermark Works
Softly Biasing the Logits
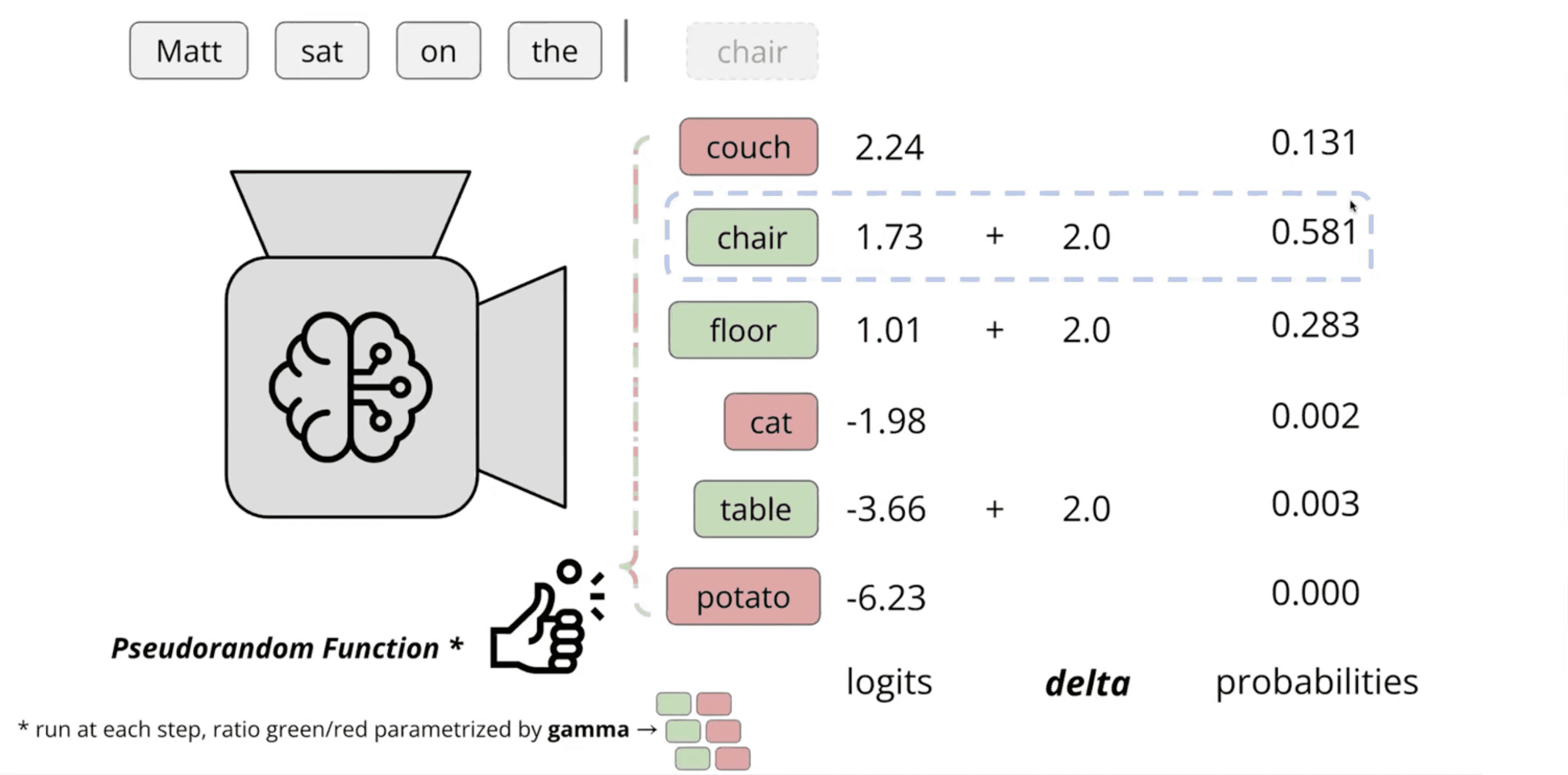
John Kirchenbauer: “Our technique has this nice interpretation of breaking up the vocabulary into green choices—good choices—and red choices—less‑preferred choices—and assigning a little higher likelihood every single time to the green choices for the next word. We still choose things the model thinks are likely to follow the prompt, but in expectation, if enough choices are made, text generated with this system will contain a surprising number of word choices from the preferred set.”
Detecting the Watermark
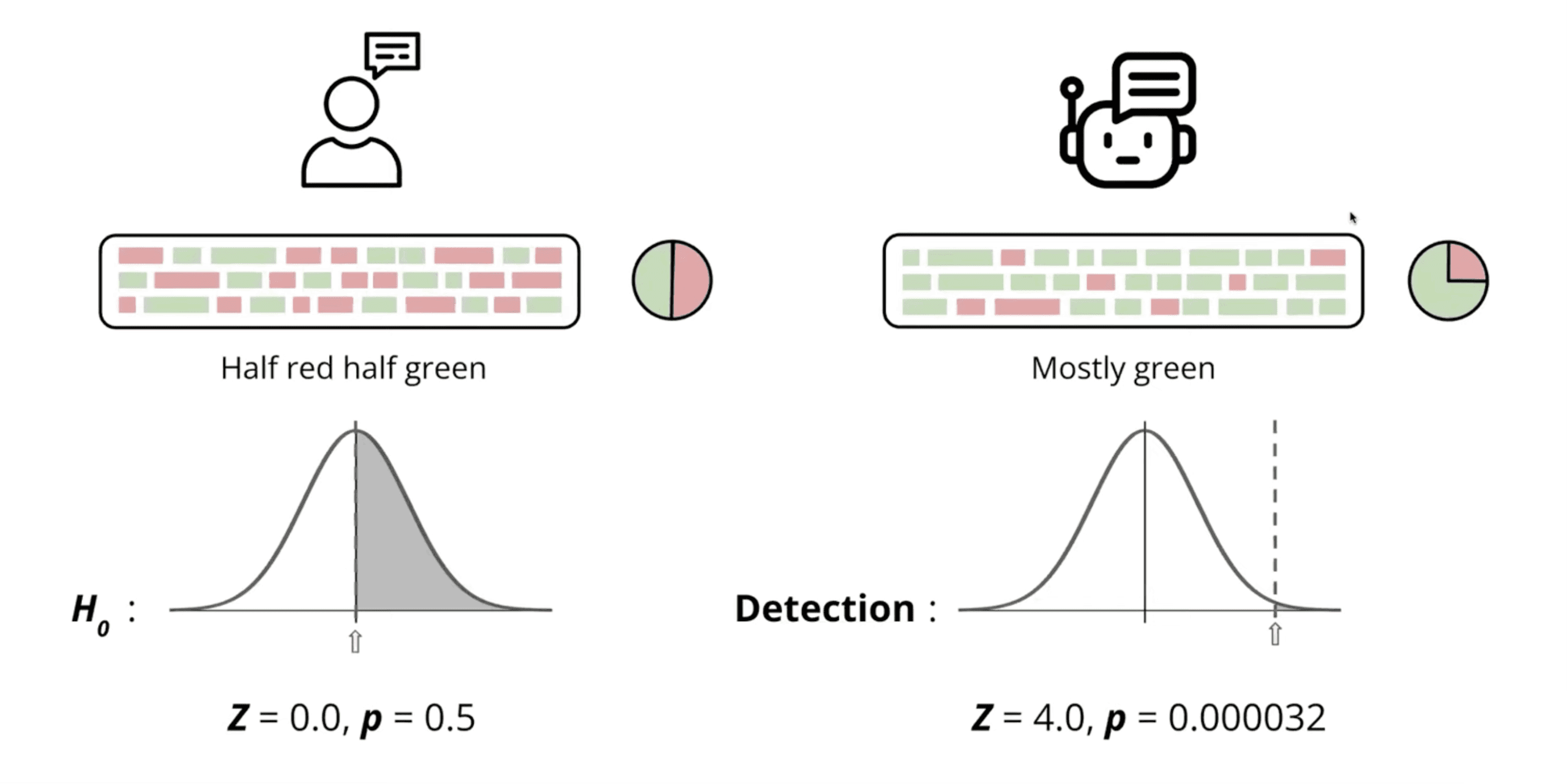
John Kirchenbauer: “If text is written by a real person or by a model that isn’t running our scheme, it’s basically half green and half red. When our system runs, you see a surprising number of greens. That lets us make a statistically grounded confidence estimate that it’s very unlikely the text wasn’t generated with the watermark active.”
Robustness and “Scrubbing”
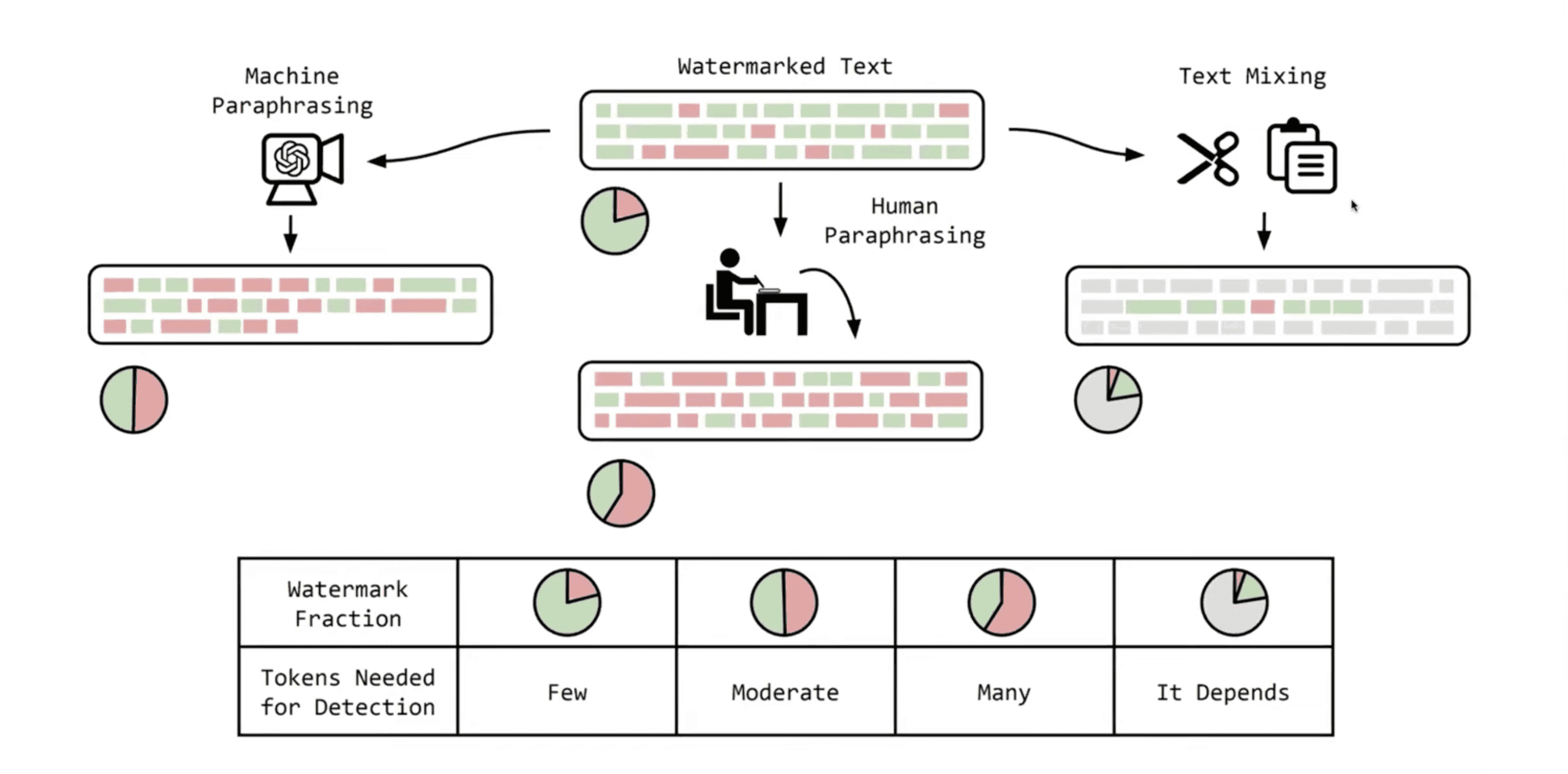
John Kirchenbauer: “If you don’t mess with the text, the signal is extremely reliable. If you run it through another model or a human paraphrases it, the signal degrades predictably, but because it’s baked into individual word choices you still get a somewhat reliable signal. And as long as a significant fraction of the original generation exists—even after copy‑and‑paste—it still shows up.”
How Much Text Is Enough?
John Kirchenbauer: “In our paper it was about fifty words, a short paragraph. By then the chance you’d see all of these slightly biased choices by random chance is extremely low—we were getting p‑values on the order of one in ten thousand to one in a million—and confidence keeps growing with length.”
Tree Rings for Diffusion Models
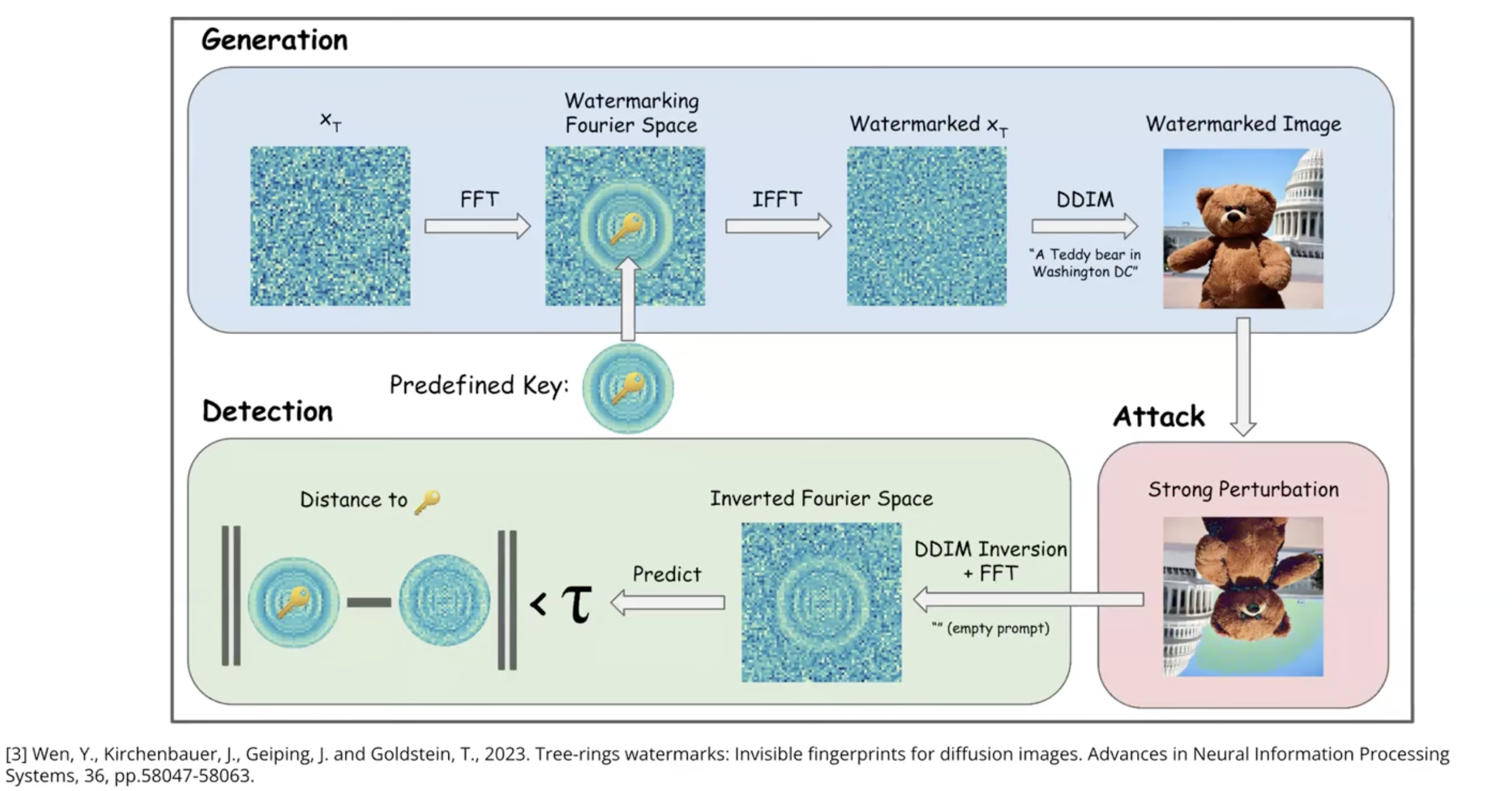
John Kirchenbauer: “We perturb the random noise a little bit in a way that, once the image exists on the internet, we can run an inversion process to turn that image back into the random noise used to generate it—or something close to it—and look for the pattern we put in. It’s not trivial, but because of how diffusion is trained, it’s invertible enough to compare against the pattern.”
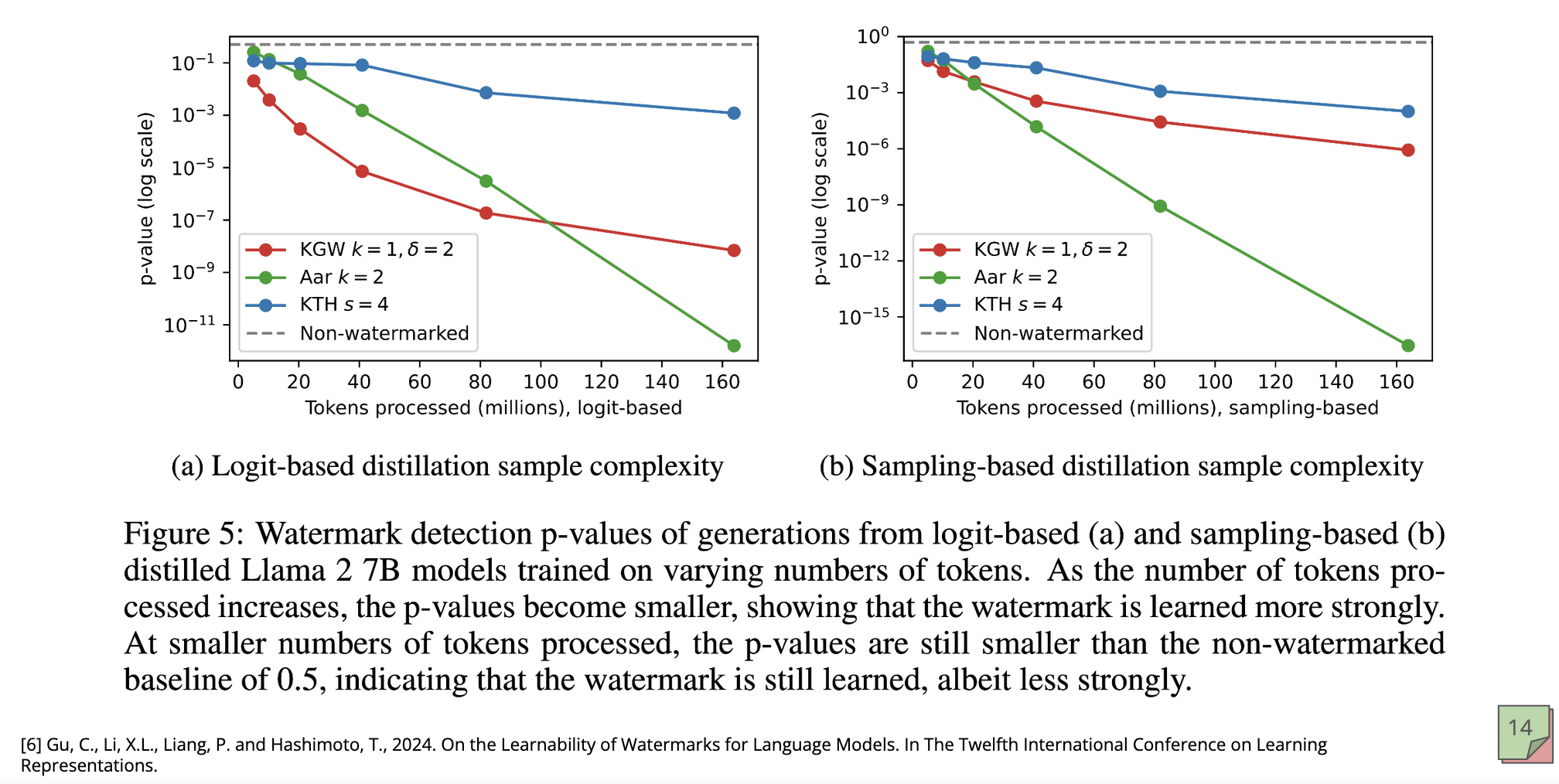
Cat‑and‑Mouse: Spoofing, Distillation, and Sticky Signals
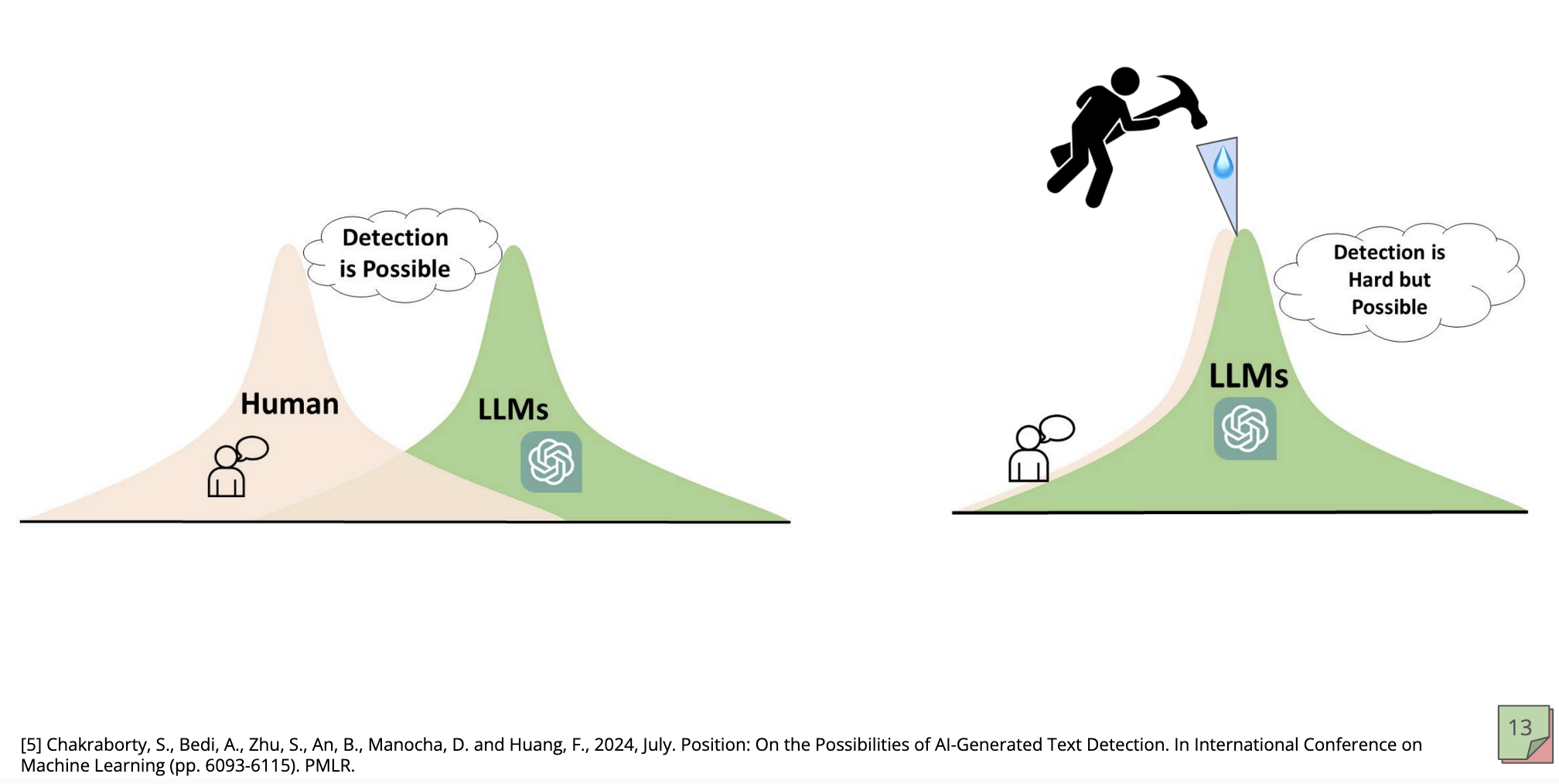
John Kirchenbauer: “Those very specific, hard‑to‑see changes are detectable and learnable. If you train another model on watermarked outputs, the watermark is sticky and shows up in the new model’s generations…The point is to preserve a gap between human and model distributions so detection stays possible as models get more fluent.”
AI Research Papers are hosted bi-weekly by the team at Arize and open to the public; join the Arize Community to get notified about the next reading!