


Our latest paper reading provided a comprehensive overview of modern AI benchmarks, taking a close look at Google’s recent Gemini 2.5 release and its performance on key evaluations, notably the challenging Humanity’s Last Exam (HLE). For those who missed the live session, we’ve compiled the essential highlights and key takeaways.
This recap covers Gemini 2.5’s architecture, its advancements in reasoning and multimodality, its impressive context window, and a discussion on how benchmarks like HLE and ARC AGI 2 help us understand the current state and future direction of AI.
You can also access the full recording below, or listen to the audio.
Watch
Listen
Learn More
Summary
A significant portion of our discussion this week focused on Google’s recent Gemini 2.5 release, the latest and a highly capable model in their Gemini lineup. This model is designed with an emphasis on deep, structured reasoning for tackling intricate problems, rather than solely on fluent text generation. As a competitor to other leading models like OpenAI’s GPT-4 and Anthropic’s Claude 3, Gemini 2.5 contributes to the ongoing advancements in reasoning, extensive context understanding, and multimodal capabilities. Key improvements in Gemini 2.5 include its enhanced reasoning abilities, covering multi-step logic, deductive thinking, and stronger mathematical encoding. Initial benchmark results for the experimental Pro version indicate consistent progress over prior Gemini models and a competitive standing relative to GPT-4 and Claude 3.
Multimodality and Massive Context: Defining Features
Mirroring its cutting-edge contemporaries, Gemini 2.5 features a comprehensive multimodal architecture, adept at processing and generating various input and output formats, including text, images, audio, video, and code. Google’s ambition is to achieve a more seamless integration across these diverse modalities, enabling Gemini to, for instance, interpret a chart, analyze an image, or reason based on audio and video content.
A truly remarkable advancement is its dramatically extended context window, reaching an impressive 1 million tokens in its experimental form. This surpasses models like Claude 3 (around 200k tokens) and GPT-4 Turbo (approximately 150k tokens). This expanded context window empowers the model to process entire books, lengthy legal documents, and extended conversations with greater efficacy, maintaining information coherence throughout.
We also talked about whether this massive context window could potentially reduce the reliance on Retrieval-Augmented Generation (RAG) in certain applications, simply by allowing more data to be directly fed into the model’s context.
Benchmarking the Beast: Where Does Gemini 2.5 Excel?
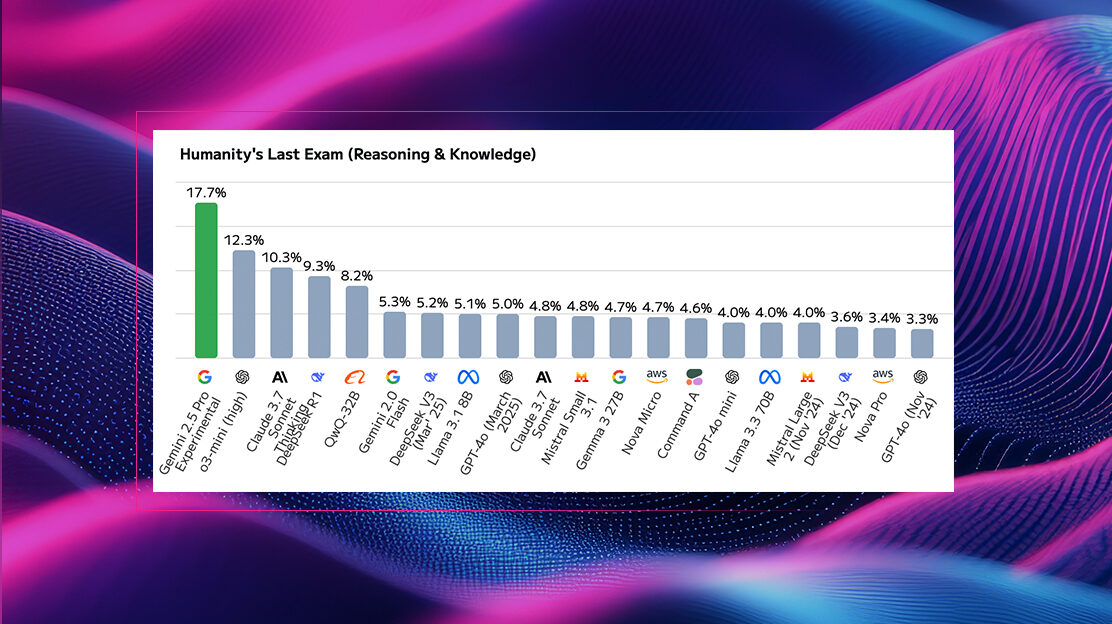
We looked at a compelling chart from Google showcasing Gemini 2.5’s performance against other prominent models, including GPT-4, Claude, Grok, and DeepSeek. Key highlights revealed Gemini’s leading score on the intriguing “Humanities Last Exam” (HLE) with 18.8%. While this percentage might appear modest, it signifies a notable lead over other top-tier models that are currently struggling to break into double digits. In STEM and coding benchmarks, such as math and science (e.g., AIME), Gemini demonstrates strong competitive performance, often scoring at or near the top. Furthermore, it emerges as a clear leader in multimodal tasks, as evidenced by its performance on MMMU.
Humanity’s Last Exam
Humanity’s Last Exam (HLE) has received a lot of attention, prominently featured in Gemini 2.5’s launch. As AI systems gain increasing power, evaluating their true intellectual capacity necessitates moving beyond rudimentary trivia and basic math problems. HLE is specifically designed as a novel benchmark to assess how effectively models can reason, solve complex problems, and exhibit expert-level thinking. This challenging test comprises approximately 3,000 questions spanning over a hundred diverse fields and subject areas, meticulously crafted by human experts.
The fundamental objective of HLE is to determine if AI models can transcend surface-level knowledge and forge the intricate connections that human experts intuitively make across various domains. Interestingly, even advanced models like GPT-4.0 have achieved very low scores on HLE (around 3%). While a DeepMind research paper reported a higher score of 26%, these results collectively underscore the significant gap that still exists between current AI capabilities and genuine expert-level comprehension.
HLE is rapidly becoming a “north star” for guiding the development of deeper, more meaningful AI capabilities. HLE questions often demand specialized background knowledge– one example might be a Classics question requiring the translation of Roman script.
A Broader Perspective on the Benchmark Ecosystem
We also discussed other widely used AI benchmarks across diverse categories, including coding proficiency, agent tool utilization, logical reasoning, mathematical problem-solving, and tasks specific to visual and audio processing.
A new trend to note: many of the benchmarks highlighted in recent model announcements, including those in the Claude 3.7 release, were also prominent in the GPT-4.0 announcement over a year prior. This observation raises a crucial question: are AI models genuinely making strides in fundamental abilities, or is progress being, at least in part, driven by optimizing performance specifically for existing benchmarks?
The concept of Goodhart’s Law is important here: “When a measure becomes a target, it ceases to be a good measure.” This prompts a critical consideration for the AI community: are we inadvertently building models to simply excel on a select set of benchmarks, or are we truly striving to create higher-performing models that demonstrate robust capabilities across a broader spectrum of real-world applications?
ARC AGI 2: Probing Basic Human Cognition
ARC AGI 2 is a more recent benchmark specifically designed to target common weaknesses prevalent in existing AI models. In contrast to HLE’s expert-level inquiries, ARC AGI 2 focuses on tasks that are intuitively straightforward for humans but prove surprisingly challenging for current AI, such as symbolic interpretation, compositional reasoning, and the application of contextual rules. Examples included pattern matching with geometric shapes and puzzle-solving based on visual cues. Remarkably, humans typically achieve 100% success on these ARC AGI 2 tasks. Current state-of-the-art models, including GPT-4.0, demonstrate very low, single-digit performance on this benchmark. This stark contrast with benchmarks like HLE ignites an intriguing debate about which types of metrics should be prioritized – those that assess deep, expert knowledge or those that evaluate more fundamental human cognitive abilities.
Key Takeaways
- Gemini 2.5 marks a significant advancement, particularly in reasoning capabilities, multimodal understanding, and context window size, demonstrating competitive performance against leading models.
- Humanity’s Last Exam (HLE) is emerging as a vital benchmark for evaluating deep, expert-level reasoning in AI models, highlighting a substantial gap in current capabilities.
- An ongoing discussion exists within the AI community regarding whether current development is truly leading to general performance improvements or if models are increasingly being optimized for existing benchmarks, raising concerns related to Goodhart’s Law.
- ARC AGI 2 offers a distinct perspective on AI evaluation by focusing on tasks that are intuitively easy for humans but challenging for current models, testing more fundamental cognitive abilities.
- The selection of benchmarks and the interpretation of their results are critical in accurately understanding the true progress and inherent limitations of AI models.