


AI in the Time of Corona

Aparna Dhinakaran
Co-founder & Chief Product Officer
Originally published on Towards Data Science
How to build Resilience in Production AI/ML during Outlier Events & Extreme Environments
Challenges of Extreme Environments
Coronavirus is the black swan of 2020. Not only is the initial on-set of the virus an unexpected extreme outlier event, the human reaction to try to contain the virus is creating massive ripples through systems that run the world — health, business, finance, gig-economy, credit, commerce, auto-traffic and travel to name a few.
Black Swan events pose particular challenges for machine learning (ML) models. ML models are trained on previously seen observations to predict future scenarios. However, today these models are seeing events that are drastically different from what they were ever trained on. Many businesses (especially in credit and finance) have 100’s-1000’s of live production models running in their organization, making incorrect decisions on data that affect their business outcomes tomorrow. The models that are likely to have problems in the coming days/months span credit, home pricing, asset pricing, demand forecasts, conversion/churn models, supply-demand for gig companies, ad pricing, and many more.
Building a model to predict for scenarios that the model has never observed in training data is hard. Standard model training processes throw as much data as possible at models and help fit structures in data that are common across events. A true black swan event does not have sufficient learnable structure across other events, leaving it for people to fill in the data and model gaps. So what do you do?
In this blog post, we will first quantify this black swan event through some of the extreme ranges of data points that are coming into systems. Second, we will address some best practices to stay on top of outlier events through robust monitoring, analysis and troubleshooting of production models.
How Extreme is our Current Environment
Let’s first ask, how extreme is the current environment?
It is VERY EXTREME.
When you look across input feature data today that is coming into production models from weather, unemployment data, traffic patterns, user spend, it will be vastly different from the model’s training data. Let’s quantify it.
First, a look at unemployment data that was just released this week. The reading of 3.28M people filing for unemployment is 4–5x the next highest reading and a +25x sigma event.
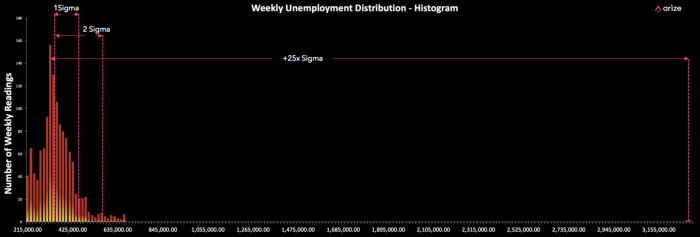
Any model using unemployment data as input and making a decision on this data, is using a feature that is more than 20 Sigmas outside of the expected value. This is an event that would be calculated to happen once every 100,000 years! This is just one example of the range of extreme events that are being fed into models making daily business decisions.
A model is not going to handle every unexpected input perfectly. With that in mind, it’s important to think about the overall systems resilience to these inputs and the ability to troubleshoot as issues arise. The most important thing is for teams to have models that are observable; if you can’t observe, you can’t adapt. This means having instrumented detection+analysis on model decisions.
Model Observability Required:
- Events that are outliers should be detectable and surfaced automatically
- Outliers events should be linked with analytics for troubleshooting the models response
It’s clear unemployment data is going to be drastically out of distribution.
Let’s look at data on auto traffic.
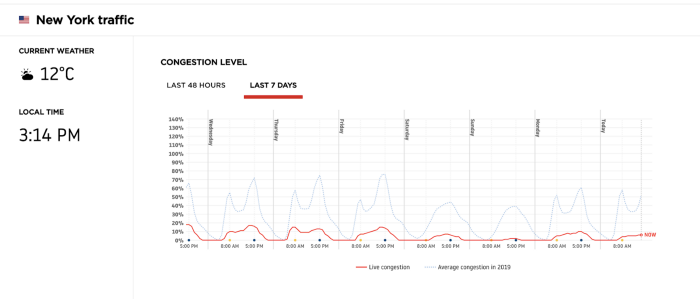
The traffic as measured for New York City from Wednesday (March 18th) to Tuesday (March 24th). The traffic has dropped to about 20% of daily volume last week to anywhere from 1–10% of daily volume.
This drop is way out of the expected daily value and a small fraction of what a model might expect.
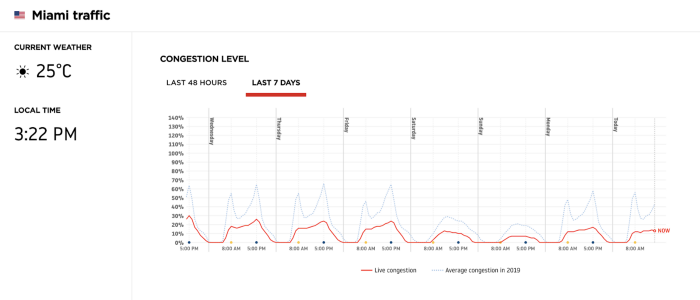
The traffic as measured in Miami hasn’t dropped as much as NYC. It looks like people in Miami are not taking the quarantine as aggressively as NYC. In this case, an ML Model that is making city specific predictions, using traffic volume as an input feature, would have an input variable that varied widely based on the city.
Model Observability Required:
- Monitoring distribution shifts in input data
- Robust splicing and filtering capabilities for model input
Throughout this week, we’ve already seen that AI is not prepared for the events generated from the Coronavirus. Weather forecast predictions have been inaccurate and we are also seeing banks consider how AI models might not handle the market downturn.
Building Resiliency During These Extreme Times
For businesses facing these rapid changes, the AI/ML models currently live in production are trained off of data that is very different from today’s situation.
What should a business do when its models haven’t seen these observations before? In other words, when the past is no longer relevant to the present, how can we predict the future?
As COVID-19 continues to impact many human systems, businesses leveraging AI/ML will have to build resilience into their production environments. As model performance fluctuates, businesses need real-time monitoring of production models to understand how model inputs are changing and where models are falling short.
What Goes In Must Come Out
It all starts with the data coming into the models used to generate predictions.
If there are similarities between the rare event and other extreme events, there are ways you can group predictions together to create a benchmark period and enable analysis. If a rare event has no relation in input data structure to any other group of data in the training set, you still need to monitor how it affects the model.
In the case of COVID-19, these scenarios aren’t just one-off outliers, but millions of quickly evolving trends that are happening across the world in different cities, all with different timelines and reactions. The scale of the unfolding scenario requires lots of different analysis and checks, across many different subgroups of predictions.
Here are some input-level monitors that a AI/ML model should have in production:
- Input checks to determine if values and distributions of features are drastically different than normal benchmark periods
- Checks on single events or small number of recent events detecting out of distribution issues
- Detect if the features your model is most sensitive to, have changed drastically
- Statistics to determine how far off the features are from the training set
How is the Model Responding?
Once you know the input to a model has changed, the next thing to monitor is how the model is responding to extreme inputs.
- Check the models performance for specific subclasses of predictions. Certain sectors such as Energy, Airline or Travel might have significant risk. You need fast online checks against various groups of predictions
- Use prior periods to produce worst case and base case scenarios to then compare against outcomes
- Monitor the predictions in real-time against every new truth event (real world prediction feedback) you receive
- If real world feedback is not possible due to time lags, use proxy metrics — things you can predict and measure to determine the models performance
Best Practices for Production ML Models in Extreme Environments
At Arize AI, we think daily about ML Observability and resilience in production environments. Our goal is to impart some of our learnings to your teams during this uncertain time. The best practice for production ML models is not far off from best practice for production software — building observability tools to understand what is happening when models or software is live to catch issues before it impacts your customers.
From our background deploying AI/ML models across a number of companies, we are sharing some best practices for production ML models during these extreme environments.
1.Track and identify Outlier Events
This includes tracking input data and model performance on outlier events. Annotating these events and being able to filter upon outlier events can help when gathering training data for future extreme environments. It is also important to consider whether to include outlier events in data for future model training. The model will be proactive against future extremes, but it also might think extremes are the new normal.
2. Decide on a Model Fallback Plan
In the past, what does your model do when it has nothing to learn from? Understanding how your model has performed in the past during extreme environments can help understand how your model is performing now. If your model is not performing well, can you set up naive forecasts based on the last N minutes or N Days and compare your model performance to this naive model?
3. Find Look-alike events
Do you have enough observability into past similar events to set up look-alike modeling for this current situation? For example, if your model took in unemployment data as input, you might be able to leverage unemployment data from similar economic downturns, such as the 2008 recession.
4. Build a diverse portfolio of models and compare model performance
Real-time models that are reacting to the external world might be performing better today than batch predictions. Having a diverse portfolio of models enables teams to compare model performance and route traffic to models that are reacting better to extreme environments.
5. When model performance cannot be improved, know the uncertainty of your model’s predictions.
Sometimes, there might not be a good model. In these cases, do you know how uncertain your model is? In this case, consider a Bayesian approach where you return the model’s predictions with its confidence levels.
Stay safe and monitor your models!
References
- Aljazeera: Weather predictions affected coronavirus outbreak
- American Bankers: AI Models could struggle to handle the market downturn
Thanks to Chintan Turakhia, Senior Engineering Manager, Marketplace at Uber for his edits to this piece.