


This article was written in collaboration with Amit Goren, Senior Product Marketing Manager at Arize
We’re excited to share that Arize AI and Hugging Face are partnering to help organizations train unstructured models and monitor and troubleshoot those models in production, lowering costs and maximizing performance.
Want to dive right in? Sign up for your free Arize account and check out our Hugging Face colabs.
Tools That Paved the Way
The transformer architecture, first introduced in 2017 in the paper “Attention Is All You Need,” has taken the natural language processing (NLP) field by storm and supplanted many previous architectures. It is so good at capturing patterns in long sequences of data that it is being used beyond NLP, in both computer vision and reinforcement learning. These transformer models are hungry for huge amounts of data – so much that their use would likely be prohibited from individuals with domestic hardware/machines.
Thanks to transfer learning, we are able to download a pre-trained model trained on a generic dataset on a generic task. All that is left to do is to fine-tune that model with your specific dataset to perform a specific task. Transfer learning allows almost anyone to obtain SOA results on their specific problem. If only the AI community had an ecosystem that allowed for collaboration… Enter Hugging Face!
Transformer architecture and transfer learning have made it possible for the AI community to focus on a consistent set of tools to achieve state of the art results, and Hugging Face has positioned itself as the center of that ecosystem, invaluable for the community.
Techniques for visualizing embeddings have also come a long way in the past few decades, with new algorithms made possible by the successful combination of mathematics, computer science and machine learning. The evolution from SNE to t-SNE and UMAP opens up new possibilities for data scientists and machine learning engineers to better understand their data and troubleshoot models.
When it comes to understanding the underlying structure of the data your model is dealing with as well as how your model is interpreting and acting on that structure, neighbor graph algorithms such as UMAP are great tools for the AI community. Arize allows its users to observe this topological structure on the fly using their interactive UMAP implementation with both 2D and 3D views. Teams can quickly visualize their high dimensional data in a low dimensional space to isolate new or emerging patterns, underlying data changes, and data quality issues.
What Is Hugging Face?
Hugging Face is on a mission to democratize state-of-the-art machine learning.
The Hugging Face Hub makes the latest innovations coming from the global AI community accessible and easy to use. With a community-driven Hub, Hugging Face provides model implementations through an open-source library and model files, also known as checkpoints. In the Hub, ML teams can easily find the most optimal pre-trained or fine-tuned model to solve their business needs. Similarly, teams can find or contribute datasets based on their use case. The Hugging Face Hub represents the global contribution of thousands of open source contributors who have provided new changes, features, model architectures, and more.
In addition to democratizing AI through a community-driven, open sourced hub, Hugging Face is removing the barriers of cost and time when it comes to training deep learning models. Building tools for Transfer Learning, Hugging Face Transformers provides APIs to easily download and fine-tune state-of-the-art pre-trained models, reducing compute costs and time from training a model from scratch. Hugging Face also offers a no-code solution, AutoTrain, to fine tune models on a specific dataset. Users just need to upload a dataset, and they will get state-of-the-art models back that are already fine-tuned, evaluated, and deployed. Lastly, Hugging Face offers an Inference API, helping teams improve and iterate on their models.
What is Arize?
Arize is an ML observability platform that enables teams to log models with both structured and unstructured data to detect, root cause, and resolve model performance issues faster. Tracing a model issue through the data it is built and acts upon is a time-consuming feat. With Arize’s purpose-built workflows for root cause analysis, teams can reduce time-to-resolution for even the most complex models. With tools such as automated monitors for drift, data quality, and performance, bias tracing to root out algorithmic bias, and powerful dashboards, teams can quickly catch model and data issues, diagnose the root cause, and continuously improve performance for their products and business.
Arize’s latest release, includes the support of embeddings to monitor and troubleshoot unstructured data models. By monitoring embeddings of their unstructured data, teams can proactively identify when their data is drifting, and troubleshoot using Arize’s interactive UMAP visualization to identify new patterns, detect data quality issues, or export segments for high-value labeling.
Challenges with NLP Models
Challenge 1: The Bias Problem / Our Responsibility / Large Language Models Dangers
While public access to large language models (LLMs) is at the core of the democratization of AI, these models don’t come without possible dangers. If misused, or used without human supervision, LLMs can operate with harmful bias issues.
These problems have been clearly documented in the literature over the past several years. Finding solutions to these issues is particularly difficult when dealing with LLMs. Currently, the community does not have a full comprehensive solution to this critical problem, nor help to mitigate the potential harm that could arise.
Challenge 2: Monitoring / Data Patterns / Data Quality
According to multiple estimates, 80% of data generated is unstructured images, text, or audio. Despite this, ML teams spend the most time and money training deep learning models and lack the tools to monitor and troubleshoot them in production. Unfortunately, ML teams working with unstructured data end up shipping models blind as a result. Arize helps lower ML teams’ cost and time training, monitoring, and troubleshooting unstructured data models.
Solution: Improving the Unstructured Data Workflow with Hugging Face and Arize
Arize and Hugging Face tackle these problems head on and are committed to making sure the whole AI chain is transparent in its design with insight and monitoring of production data, ensuring that AI is never blind.

Starting with the dataset, thanks to the Hugging Face Hub everything is public and transparent. In the Dataset Card you can see where the data is sourced from and can check the dataset quality with the respect to metrics that measure bias risk.
When it comes to models, it is key that their architecture is open sourced in the Hugging Face Hub. But, once we know their architecture, can we know how they are performing? Can we observe how models understand the inputs? Arize can help teams observe model performance in production. Arize measures drift by comparing euclidean distance of production data to a baseline and alerts ML teams that there may be a new pattern, an underlying data change, or data quality issue.
Troubleshooting unstructured models is simple with Arize’s interactive UMAP implementation. The 2D and 3D views enable teams to easily visualize their high dimensional data in a low dimensional space. This embedding visualization helps ML teams understand the topological structure of their data and how their model is understanding that structure to make decisions. It can help you identify human errors on construction of the training data, which once fixed can improve your model without touching its architecture.
Code Example: Obtain Embeddings From a Transformer Model
There is not a one-size-fits-all approach for computing embeddings. Depending on the problem at hand and the architecture of the model, you may choose to compute your embeddings in different ways and compare them to see which version of the embedding is best for you and your problem. In this section, we will go through how to obtain one embedding vector representing a sentence. At the end, we will put it all together so we can obtain embedding vectors for the entire dataset.
Embeddings are, in essence, a dense vector representation of the inputs made by our model. Thus, we will need to run inputs through our model and obtain outputs, from which we will extract embedding vectors. For this extraction to be possible, these outputs should contain, in addition to the classification logits, the activation values of the hidden state layers.
Specifically, the vector components are obtained from the activation values of the hidden layers of your model. Hence, we will need to run the input text through our model to obtain the outputs.
First, let’s tokenize the input text:
input = tokenizer(input_text)
Once we have the tokenized input, we can pass it through our model. We use no_grad() because we are not in the training phase, hence we do not need the gradients for back propagation.
with torch.no_grad():
# Get model outputs from batched inputs
output = model(**inputs)
This output should contain, in addition to the classification logits, the activation values of the hidden state layers. We can select the hidden state layers as we would in a dictionary (to be able to obtain hidden states, we need to pass `output_hidden_states=True` when we instantiate the model using Hugging Face’s 🤗Transformer library):
# Get hidden states from model output
hidden_states = out.hidden_states
# Shape (num_hidden_states, seq_length, hidden_size)
The shape of the hidden_state tensor is (num_hidden_states, seq_length, hidden_size), where:
- Num_hidden_states represents the number of hidden states layers present in the model.
- Seq_length is the chosen token sequence length established. If our tokenized text has more(less) tokens, the sequence will be truncated(padded) before passed to the model.
- Hidden_size represents the size of each hidden layer. As mentioned above, embedding vectors are arrays with values equal to the activation values on the hidden layers. Hence, since a hidden layer has hidden_size activation values, this parameter gives you the embedding dimensionality. For instance, the BERT model has a hidden_size of 768, and a consequent embedding dimension of 768.
Next, we choose to select the last hidden state layer to form our embeddings. You could choose other options, such as the average of all hidden layers, the maximum, the minimum, or any other combination of your liking. We kept it simple and chose the last layer.
# Select last hidden state layer
last_hidden_state = hidden_states[-1]
# (seq_length, hidden_size)
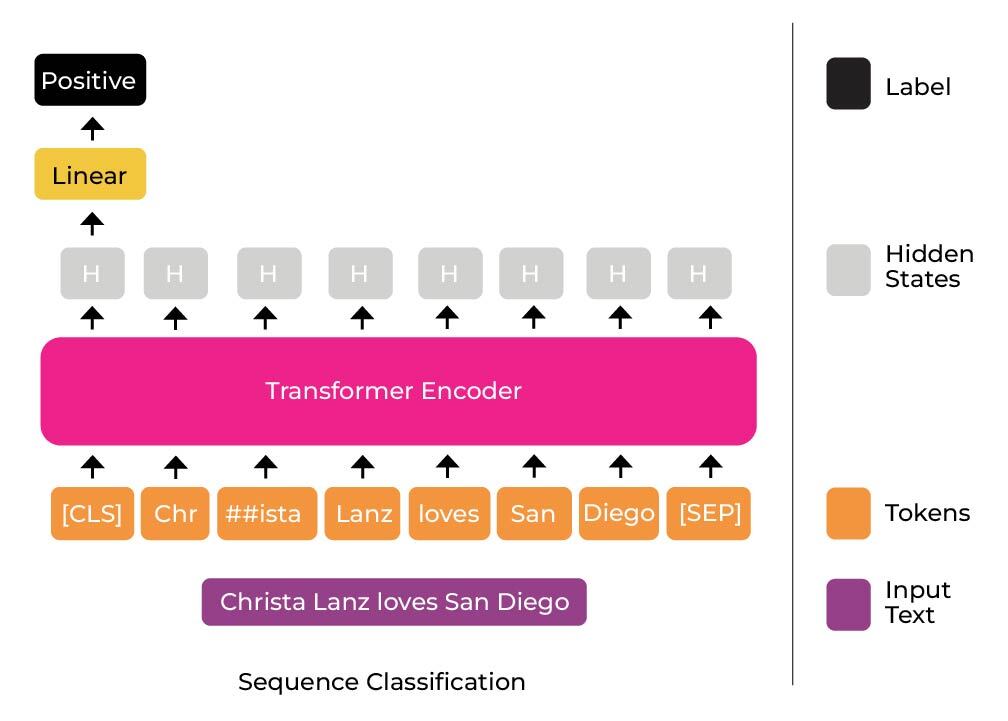
The shape now has been reduced to (seq_length, hidden_size), the last hidden state layer contains one embedding vector per token in the tokenized input. Here you have another opportunity to generate your embeddings in different ways. For instance, you could average out all the embedding vectors of all the tokens. Being a sentiment classification problem, and having used a BERT-like tokenizer, we chose to select the embedding vector associated with the [CLS] token, also known as the classification token (in sentiment classification problems, the [CLS] token embedding is fed to a feed-forward neural network to perform the classification and return the logits).
.
# Select CLS token vector, across the batch
embeddings = last_hidden_state[:,0,:]
# (hidden_size)
This is a method used in the original BERT paper, and is illustrated in the image below. In sentence classification, you often pass the embedding vector associated with the [CLS] token to a feed-forward neural network to obtain the classification predictions. In our case, we also extract that vector as a representation of the input sentence for observability using Arize.
Now you know how to calculate an embedding vector from input text. However, you will also probably want to calculate embeddings for batches of data at once. The code snippet below gives an example of how you could calculate embedding vectors representing sentences in a sentiment classification problem, for input batches.
And there you have it, this is how we chose to calculate embedding vectors, representing input sentences, in a sentiment classification problem. As we discussed above, even within the same use case, there are many opportunities for design decisions. In our sentiment classification tutorial, we have a function like the one above with more ways of computing embeddings implemented – check it out!.
To learn more about how to generate embeddings in other NLP use cases or in computer vision, check Arize’s example tutorials in the company’s documentation.
How Can You Help Make AI More Transparent?
Using Arize
Many times, knowing the architecture of a model is not enough to know a-priori how it’s going to perform on a specific use-case. Arize allows you to observe your model’s performance, see how it interacts with your data, and visualize your dataset’s topological structure. Arize can help you identify problems that were not possible to notice before, allowing you to report back to the community and make public changes to your dataset and/or model in a public setting such as the Hugging Face Hub.
Using Hugging Face
Hugging Face’s Hub has thousands of models and datasets, open sourced for you to see and use. If you are working on a specific use-case, you may detect problems with the way the data was sourced, problems with the data itself, possible improvements on the model, etc. Making these observations and possible improvements public is a fantastic way to help the community strive for better AI.
Start Your Journey
Want to get started? Check out Hugging Face’s Hub and sign up for your free Arize account.