




Drag Your GAN: Interactive Point-Based Manipulation on the Generative Image Manifold

Sarah Welsh
Contributor
Introduction
In this paper reading, we dive into “Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold.” Drag Your GAN introduces a novel approach for achieving precise control over the pose, shape, expression, and layout of objects generated by GANs. This approach allows users to “drag” any points of an image to specific target points — in other words, it enables the deformation of images with better control over where pixels end up to produce ultra-realistic outputs. Or, as the abstract describes it: “Through DragGAN, anyone can deform an image with precise control over where pixels go, thus manipulating the pose, shape, expression, and layout of diverse categories such as animals, cars, humans, landscapes, etc.”
You may have seen videos of the point and drag image manipulation on social media. In one recording of the tool, a dog was edited by dragging its ears upward, and a lion with a closed mouth was edited by dragging its nose and chin in opposite directions. It’s a pretty revolutionary approach to image editing, and we go into some of the details of that here.
Join us every Wednesday as we delve into the latest technical papers, covering a range of topics including large language models (LLM), generative models, ChatGPT, and more. This recurring event offers an opportunity to collectively analyze and exchange insights on cutting-edge research in these areas and their broader implications.
Watch
Dive in:
Transcript
Aparna Dhinakaran, Co-Founder and Chief Product Officer of Arize AI: Let’s get started. What I thought we’d do today is just go through the paper. There’s a ton of really cool visualizations that this paper has. Let’s start there so we can all build up some excitement about how cool this paper’s work is, and then we can jump in and go through the paper and what was the implementation behind the paper?
So first things first this is Drag Your GAN. This was the first time that they brought together interactive point based–so being able to actually interact with the GANs and manipulate the image, which is kind of like the novel concept behind it. What I thought we should do is just start with some videos. So you can all see what’s possible. Here, let’s see the main demo first. This is one where they’re manipulating an image of a dog. The red points here are what they’re calling the handle points. So it’s where it starts, and then they’re moving it so you can see with the ears they’re moving it towards the blue points. So you’re kind starting with the handle point, you’re moving it towards your target points.
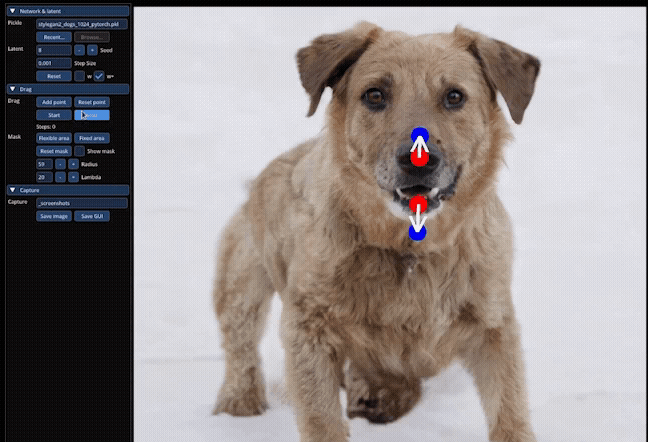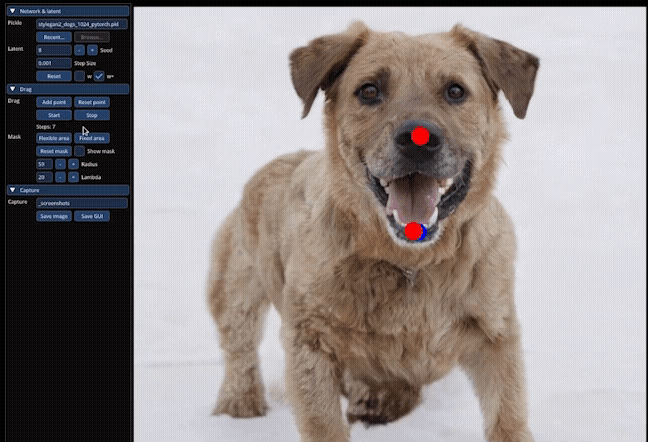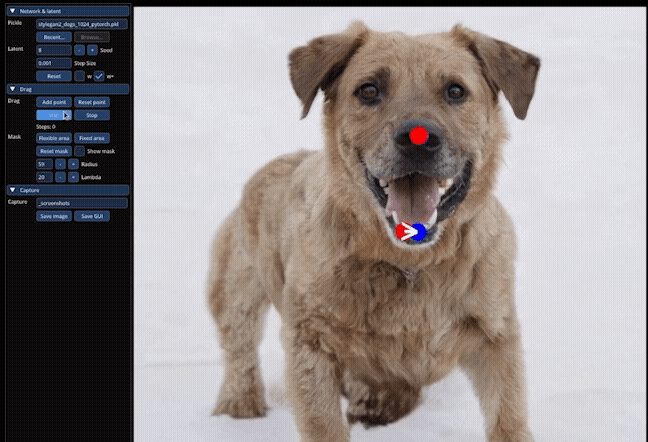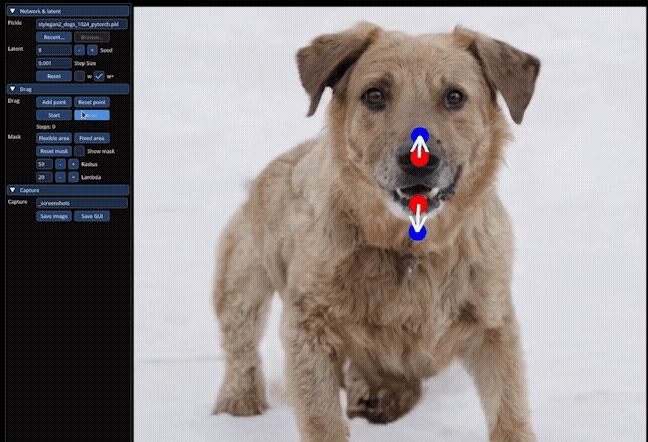
We’ll compare a couple of examples they do. They actually opened up the dog’s jaw, showing the teeth. And so like in this example, here, you’ll notice this is this target point here, and you’ll notice that the setting behind is also getting adjusted properly.
This is just a fun one to watch.

So they’ve tried this on sets of animals. They’ve done this for humans. They’ve done this for landscapes. And it’s actually kind of interesting just how rich the feature space behind this was that the model was able to use to actually track next positions and get it right like you move the lips over. Okay, the teeth should go like it, just new to kind of do that which is really, really cool. And this, what they’re doing here is, they’re drawing a mask, so they only want manipulations to be in that certain region.
So let’s take a look at these.
Jason Lopatecki, Co-Founder and CEO of Arize AI: It’s pretty amazing that when the extends address, it understands the folds, understands gravity, or maybe not gravity, but understand how it should look as you extend it, like there’s so much structure that’d understood about the thing you’re moving from just a picture that I think surprised a lot of us in what you could actually do with this.
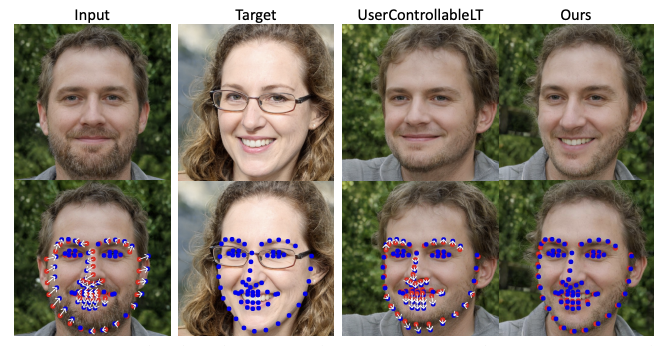
Aparna: Yeah. And maybe let’s just start there, actually. Like, for example, there’s a really good image [see image of people above]. So they were comparing. This is the input. This was the target. And in this input, here again, the red points are again all of your handle points, The blue points are where you want kind of your target points, maps to target points, and then this is kind of a benchmark. This is kind of the most comparable thing in the past user controlled by it and the name of another approach, and here it moved the parts of the face, but it didn’t highlight the teeth, which was there in the target. And so, just to give you an example of like it, even with the manipulations that the user wants, it’s still able to kind of more realistically produce more realistic images of what actually would have happened if you had dragged it which is really, really, phenomenal.
Jason: I mean, it’s fascinating when you think about what must be understood by the latent structure. Because what you’re doing is you’re updating the latent structure that’s generating this by moving the latent structure a little bit. And the fact that by latent structure it’s kind of what the model knows about this face? Well, it knows there should be teeth near the lips, because when you move the lips away, generate the teeth so like there’s just.. I think we’re really, really impressed by what does it show? It shows how much is in latent space and known, and what, by moving and manipulating those embeddings in latent space that it can actually do in the picture.
Aparna: Well, just what I thought we could do is maybe just start with a little bit of like what was there in the past? Just walk down the paper. What was there in the past? What was the novelty and the method that this one approach? And then we can jump into some of that just kind of follow the flow of the paper. I don’t know if you wanted to. If you want to show some, there’s some really cool experiments with this one, so I don’t know if you want to spend a little bit more time just on the experiments first.
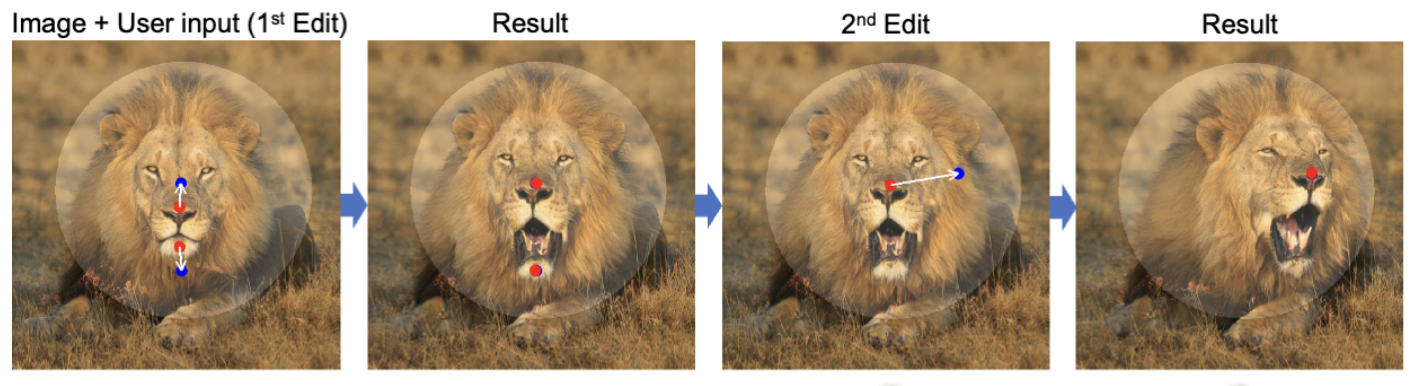
Jason: I think the lion generating its teeth or some of those are pretty amazing. [See image above]. We could start at the beginning. The older methods to me felt very rough in control. So you could do something you can in paint, you can change something. But grabbing physically something in the image and moving it, that feels completely unique in the set here. It’s just amazing.
There are two things the authors talk about, which is in the previous way of doing things. There’s two big problems. One was knowing first how to edit the latent space. But then, since you’re doing it in small increments, you’ve also got to follow your point. So there’s another challenge of point tracking, making sure the point you then grab to do the next movement, the next, small movement matches the physical object’s point where it is where you moved it to. So it’s kind of like major problems being solved in the paper. One is the movement of the embedding and the other one was finding the point of the object in the new space in the incremental space you’ve created.
So, there’s two different problems that we’re solving.
Aparna: It’s just drawing a mask, so they’re saying, only have the manipulations within the face. So not the rest of the image. So I’ll keep playing here. But you’ll see it only sticks to manipulations there.
Jason: Yeah. It’s amazing. This is all being manipulated. What else, what other manipulations of the picture could you do versus just translations or movements?
Aparna: Yeah. I can go into the paper. I just feel like these are so cool to watch. It’s amazing to learn how much it has to know in order to know about the embedding space or the feature space to really do this properly.
Jason: You notice how some of the folds came down how the folds came down? The fold was there and extended it. You kind of know things like if you look at the right arm there. How it knows the fold should extend. It’s just a physical structure that exists in the real world. This, you know, is not so obvious in a picture, when you just look at the pixels. But the point is, I think it’s trained on so many images that understand some of the physical things that we would, you know ourselves naturally.
Aparna: I’ll just do one last one and then we can hop into the paper, but this is one with landscapes. I thought this one was really cool because of the shadows. Which, you can move the water down, and like it extends the shadows and the images above. There’s a couple here where they add in. It’s like moving from sunlight to sunrise, or things like that. Who has to know what’s normal? What’s possible? Okay, I don’t know.
Jason: It’s pretty amazing.
Aparna: This is really cool. Right? Like as the trees grow, the shadows are increasing. So there’s so much that it just has to know. This is a good one.
Jason: Yeah. A question arises: is there a sense that this model is a model of the world? It’s a good question. There’s Yann LeCun, he’s kind of like that big on the world model. My take is it definitely models portions of the world? Is it a true world model? Feels like a very high level debate. But there definitely is some model of the world. I just don’t know if it’s exactly what you know that doesn’t have enough information about having been through enough experiences. I think of all the things we’ve seen, how many days we’ve seen gravity go down, or things fold, or the way a dress falls – we’ve just seen a lot of those. And at some point you’ve got this model of things that you think is true and I think it’s built some model of things enough to be able to move things around. I don’t know if you probably would say it’s got a human level model of the world. Probably not. But it’s got enough to do quite a lot – and more than most people probably think.
Aparna: Let’s start with what is novel about this paper compared to the past. The authors kind of broke up the world of GANs into a couple of key tenets. First is to really call it unconditional gans style GAN, style GAN – two where you can’t really edit the actual images. So you can’t really take in human input and manipulate. These existed in the past, where the user receives some kind of call it segmentation map and asks it to actually generate photorealistic images.
And yeah, I think there’s another one that they were talking about here: you can take semantics from one sample to almost style transfer. We’re taking semantics from one image applied over to another image. One of the key points in this paper is that this is one of the first times that users can give a handle point and give a target point. When you can manipulate the actual image using just these two inputs, you’re really answering from a method perspective: How does it work?
Anything else you wanted to add there, Jason?
Jason: I think it’s fairly unique in its ability to tightly control what you wanted to do, grab a point in the space and move it like that. That feels very novel. And then I think the approach they did is pretty novel too, in terms of the technique.
Aparna: Yeah. So that right here, with the first to connect the point based, edging problem to the intuition of discriminative GAN features and design, a concrete method. So that’s kind of what was unique about this paper and what it does is you dive into the actual method. It breaks it up into a component of point-based manipulation. And then a component around motion supervision. So what does that actually mean? So first is the point based manipulation. So in this case, over here there’s kind of the handle point. There’s the target point. And I think the part that was interesting was that every time you saw an adjustment–it does a first step, It readjusts, there are questions like: Where does the new handle point now get placed? And that was something that the team, actually the team behind the paper. Actually, I think there was a lot of detail in the paper about well, you manipulated the image? And they actually used the feature space in the new kind of image that was created to come up with the new handle point, and that was really novel, because then each step you’re kind of editing that handle point to move towards the target point but we’ll dive into that–they go into depth during the methods section. But every single step here is basically updating each iteration updating where that red point is as it moves closer and closer to the blue point.
Jason: That was my take as well that if you go up there, there’s two steps which are like the motion supervision, which kind of moves W. to W. Prime, and there’s point tracking which gets you there. You move your handle to the right, the right spot, and then you kind of move it again and do the same thing over and over again. And then the magic of the WW Prime was probably the next section.
I feel like lots of papers, you start to get the heavy math section –it took me a couple of reads–what it looks like is there’s something called a feature map, which is typically a 2D map in an image model– you can see it there– It’s typically a 2-D map which is based upon an activation of pixels based upon training data. Normally it’s a map based upon activations in the real image. My understanding was if you were to move the maps slightly towards T, which is what? They create a vector D that’s in that direction. You look at the difference between the two maps and that difference is that if below is the. At that point, they look at the feature map, at the current point. You’re on a feature map and a slight movement in the direction you’re going… Look at the difference between those, which is the loss function below. And then the magic is once you have that loss function, you create a gradient. So, you back propagate that loss through the network. They lose one term there. So they only hold one term. As mentioned below, they only hold the movement term as they calculate the gradient, and then the gradient gives you the update term for the WW Prime. That’s my read of It. There’s a feature map, a new feature map created in a direction, there’s a difference, a gradient created. And then the gradient helps you update.
Aparna: Yeah, I think the part that was interesting was that they dive into a little bit of this like mumbo jumbo loss function basically one feature map versus in like the new. I don’t know if I should call this like P Prime, or whatever, but like the new spots, feature map. And then I think the motion supervision loss here is just trying to optimize toward how close is it to T, while still maintaining the discriminative abilities of the next point. And I think that’s what they’re trying to optimize for here at that. That was my read of basically this loss function here. I don’t know if that was yours, too?
Jason: Yeah that was my thought too. And someone has you know any thoughts and applications in 3D space, or even higher dimensions.I don’t see how I can do this, and you know I well, I guess 3D space the feature maps are based upon a 2D model. So Could you use this for those I think you absolutely could. I think it kind of like the way this works. It almost moves a a model of an object through your image. That’s a little bit of what’s happening here.
Aparna: Even if I think about video, it’s different frames of images that are sped together in a really fast way, and so the applications for 2D might be more prominent than speeding them and adding them together. You can kind of get the 3D. But I don’t know if there’s a lot of experiments done in the space of manipulation in general.
Jason: Yeah. One of the things I was thinking is whether you can grab eyelids and make the eyelids close. Do I really even need to specify the points? Could I just say, close the eyelids like, and that would be more of an understanding of how eyelids work and where do eyelids reside in latent space? What does closed mean? There’s a deeper thing here where you’re using a pretty cool technique to that that works really well. But like, where does this go? If you understood what the latent space was, could you do it without the handle points?
Aparna: One of the key lines I just highlighted that we were talking about was “the key idea is that the intermediate features of the generator are very discriminative, such that a simple law suffices to supervise motion here.” And so in here, what I’m thinking about is basically the feature maps – like the intermediate feature maps that it maps to are so discriminative that a simple loss function suffices to supervise motion. What do you think they mean by “are so discriminative”?
Jason: Yeah, I think what it means is the features can mean anything right? They could be an eyeball. Features and latent space can mean anything. And your question is something like what feature would I edit to move an object right? Instead of creating an eyeball, what feature would I add it to actually move it left or move it right? Sometimes that thing might be so complicated, like a simple linear loss you know, linear subtraction won’t be minimizing a simple difference between won’t capture the idea of motion. Could it capture the idea of something else? But I think their point was there’s really simple features here that capture motion and if you minimize the difference between those and WW. Prime, it would actually capture exactly the motion. So I think that’s what it means.
Aparna: This section got really deep in the math. Do you want to go through a little bit of the experiments? We could talk through some of the experiments? Or do you want to spend a little bit more time in the actual method itself?
Jason: I think there’s a bit on point tracking that was pretty interesting, which is the second part, which is like: Okay, you’ve now you move W, you’ve generated an image, how do you get back your handle?
Aparna: Okay, we can. Let’s go through that part.
So in this case here, this is basically after they’ve gotten W. Prime. So here, this is where they jump into the nearest neighbor part. To actually do this is post-nearest neighbor where they jump into the actual point tracking.
So I think my takeaway from this section was that the new point that was actually in W Prime, the new point from the feature map, after the loss was done, and they got to the new P…My take of this was that it’s actually once it has the feature patch it then does a nearest neighbor, and then identifies using shift to patch loss. What the new P point over here should be.
So it’s almost like it’s generated a space of all of the possibility selections will be this, should I have all look like this, should the crease be over here, and then it takes just the nearest neighbor to identify what the next handle point should be. And that’s kind of how it lands on the next key point.
Jason: I feel like that’s a really good explanation. It’s like a nearest neighbor. Search to find the across the feature map of a difference to define the point that matches it closest to.
Aparna: If I just take the line example it wasn’t totally obvious to me that, for example, the jaw would open like when they pulled in separate directions. You know, I thought, well, how are they gonna do that? One’s moving up and one’s moving down. And it wasn’t totally obvious to me until I saw the video. Oh, well, if the mouth opens, then you can kind of get up and down. And so the part there that was really interesting. It’s the first one that is P one P. I’m calling it P. Prime now and then the next P. Like the jaw P to the top P Prime. And so it’s almost going through it, maybe it’s doing it and that’s how it optimizes. But there’s a landscape image where it did all of them all at once. And so there’s some loss function where it’s maximizing what’s realistic and all of the possible feature spaces.
Jason: The point tracking approach was, it sounds like novel as well in this – it sounds like most point tracking doesn’t work in feature map latent space. It works; it looks like there’s a lot of approaches, point tracking. This is a unique one for using latent space to to actually track the point.
Aparna: Yeah, I think the part that was really interesting for me was, well, they’re balancing. If you have multiple hand multiple P’s multiple handle points, you have to optimize for that. Each of the P’s also move towards their target in a realistic way. And you’re maintaining a kind of nearest neighbor for each one of those P’s and so like these examples here, I’ll only show one.
But as it got to like an example of right here, where there are multiple P’s and multiple P’s being able to perform nearest neighbor on all of these P’s and then get to kind of the new point. And how, how does it optimize that? I mean that was really. I think part of what was interesting to me is, how is it balancing or optimizing for all of these all at once? Right? When you look at it as a single point it seems a lot easier. But when you’re looking at it as multiple points, it looks a lot more complicated under the hood.
I think next we can go through some of the experiments and then talk through some of that in the paper.
So they did a couple of different experiments where first they compared against style GAN. And then they actually compared against Raft, which was the most state-of-the-art for point tracking. So they compared it to Raft, which is kind of the state of the art and point tracking. And then they compared it against user control Bell T, which is kind of the state of the art in manipulation up until that point. But this paper kind of combined point tracking and manipulation together, that were the two benchmarks that they used here. And I actually thought it was interesting like, this is Raft, for instance. And Raft was going through. And this is an example where they had the input. They’re trying to move the lion red point over to the blue point and basically comparing the approaches here. Some of these, the lion is right on top of the blue point here, there’s just a little bit of still misses, or somewhere. The scenery was a little bit off, still in Raft. And so that’s interesting. Seeing how their approach differs slightly from the previous approaches.
Aparna: The authors afterward had a discussion about what the potential of this might be. Obviously some of the social impacts of this type of technology are likely once deployed. Any takeaways for you, Jason, on just the application potential of this?
Jason: I don’t know if people have been following Adobe Firefly. I think it’s Firefly. It’s pretty amazing. I can imagine tons of stuff in an image around just the flexibility to take a picture and then not get the perfect pose, and then edit that pose, or change it. And I think the future is also not just point by point picking, but the whole fact that you can manipulate latent space and find features that in this case means just movement – like there’s an object, and I can move this object and so I see a big future of understanding latent space and doing these movement, doing these manipulations without even handles or different ways of discovering what is, what in space, and making edits on that. And like it, it’s just to me was kind of eye opening on the potential
Aparna: it was interesting they mentioned things like out of distribution manipulation. Or you showed some words like “Our approach has extrapolation capability for creating images out of the image training image distribution extremely open mouth greatly in our field.” It’s what we’re highlighting. It can be extrapolated for images, not necessarily within the training data set. And then they called out some of the limitations of still things like training data. So being able to give it a variety of…it says, handle points and textualist regions sometimes suffer for more drift in tracking. So mentioning the kind of texture in the handle points was helpful, but just interesting where this could go as areas for improvement with this paper.
Jason: I feel like every week there’s something that drops. It looks like magic. This one definitely feels like magic.
Aparna: A lot of depth in this one. But I think the biggest take away from this one was being able to actually use point based tracking to do image manipulation. So identifying a couple of points, using that to actually manipulate the image. And I’m curious if this is actually used in something like Adobe or Photoshop, or things like that, where you can go pull this use, you know, this kind of capability becomes easier for, like movie editors or things like that, so that’ll be exciting to see that.
Thanks for joining another paper reading. See you on the next one!