



In our latest AI research paper reading, we hosted Santosh Vempala, Professor at Georgia Tech and co-author of OpenAI’s paper, “Why Language Models Hallucinate.”
This paper offers one of the clearest theoretical explanations to date of why AI models make up facts — connecting hallucinations to classical misclassification theory and statistical calibration.
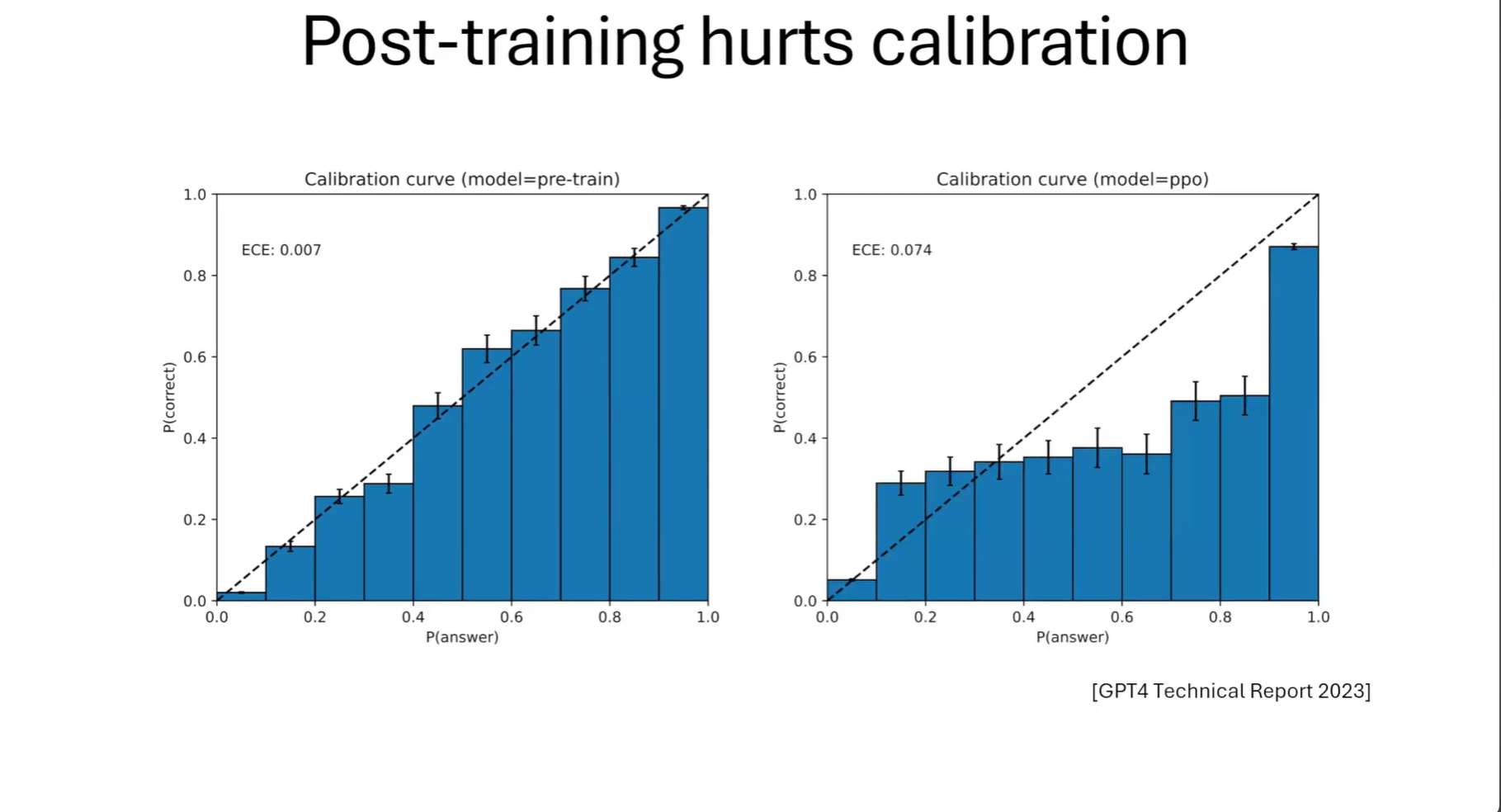
The conversation explored how hallucinations emerge during pre-training, why post-training doesn’t always fix them, and what it might take to teach language models when to simply say, “I don’t know.”
🎥 Watch the Talk
Why Language Models Hallucinate — OpenAI Paper Explained by Santosh Vempala
Key Takeaways from the Paper
- Pre-training encourages hallucinations.
Models maximize the likelihood of training data, which often rewards plausibility, not accuracy. When data is limited, false-yet-plausible statements naturally emerge. - Hallucinations are mathematically predictable.
The team proved that hallucination rate ≥ 2 × misclassification rate − correction terms, directly linking language generation errors to classification difficulty. - Calibration explains why LLMs “sound right” but are wrong.
Minimizing log loss ensures calibration. The model’s probabilities align with correctness, but not necessarily truth. - Post-training should penalize “confidently wrong” answers.
When “I don’t know” is scored the same as wrong answers, models are incentivized to guess rather than abstain. Adjusting scoring fixes this bias. - Behavioral calibration matters.
Encouraging abstention through behavioral scoring (rewarding uncertainty and penalizing confident errors) is key to reducing hallucinations long-term.
Highlights from the Talk
(Edited for clarity and brevity)
Santosh Vempala:
“Pre-training encourages hallucinations because language models are designed to replicate the distribution of their data, not to validate truth. If they haven’t seen every possible true statement, they’ll inevitably generate false but plausible ones.”
“Post-training is where we can change behavior. If we treat ‘I don’t know’ as neutral and wrong answers as penalized, the model learns restraint.”
“Our main theorem shows that hallucination rate is at least twice the misclassification rate minus a correction term — meaning, if your classifier can’t tell fact from fiction, your generator will hallucinate.”

Calibration vs. Accuracy
Santosh Vempala:
“Calibration I’ve already mentioned what it is — rather than being accurate, where you’re precise about every probability, you just want to say that on days when you say it’s going to rain 20%, on all those days, it actually rains 20% of the time.”
“Calibration is a much easier goal than being accurate. You could simply output, for every document, the average probability in the training distribution — the same answer every time — and it would still be calibrated.”
“After pre-training, language models are very well calibrated. But calibration is a weaker goal than accuracy.”
“Pre-trained models are often beautifully calibrated — but that just means they’re consistently confident in being wrong.”

Pre-Training vs. Post-Training Dynamics
Santosh Vempala:
“Pre-training is designed to match the data distribution over the training data documents. It will calibrate with the training distribution, but once you encounter something unseen, you hallucinate.”
“Pre-training encourages hallucinations — and this can be proved formally. Post-training should penalize errors more severely than uncertainty.”
“Post-training today is an art with sophisticated techniques and human effort. But one issue is that wrong answers and abstaining are scored the same — just like in the SAT today. If that’s the case, why would you ever abstain?”
“What we’d like to do is have the language model answer only when sufficiently confident — say, respond only if you’re at least t confident. You could also change evaluation scoring to encourage this.”
Practical Recommendations
Santosh Vempala:
“A correct answer should get a score of 1.
‘I don’t know’ should get 0.
A wrong answer should get a negative score — minus t over (1 minus t).”
“The choice is designed so that it doesn’t make sense to guess unless you’re at least t confident. The expectation would be below zero.”
“We call this behavioral calibration — the model should answer ‘I don’t know’ when its confidence is less than the target confidence for that context.”
“Pre-training produces predictive language models — great at predicting text, even getting things like grammar right. But post-training should produce generative models that don’t hallucinate and know when to abstain.”
“We should invert the incentive: reward uncertainty, penalize wrongness.”

💬 Audience Q&A
Q: Are hallucinations architecture-specific?
A: “No. The phenomenon is statistical, not architectural. Even transformers will hallucinate if unseen data exists.”
Q: Can we measure when a model is incentivized to guess?
A: “Yes — monitor how often confidence and abstention move together. If confidence rises but abstention doesn’t, the model’s reward structure is misaligned.”
Q: Are creative outputs hallucinations?
A: “In creative tasks, hallucination is contextual. The model isn’t factually wrong — it’s generating beyond the data, which can be intentional.”