



This article is co-authored by Mikyo King, Founding Engineer and Head of Open Source at Arize AI, and Xander Song, AI Engineer at Arize AI
Building a baseline for a RAG pipeline is not usually difficult, but enhancing it to make it suitable for production and ensuring the quality of your responses is almost always hard. Choosing the right tools and parameters for RAG can itself be challenging when there is an abundance of options available. This tutorial shares a robust workflow for making the right choices while building your RAG and ensuring its quality.
This article covers how to evaluate, visualize, and analyze RAG using a combination of open-source libraries including:
- Ragas for synthetic test data generation and evaluation
- Arize AI’s Phoenix for tracing, visualization, and cluster analysis
- LlamaIndex for building RAG pipelines
For the purpose of this article, we’ll be using data from arXiv papers about prompt-engineering to build the RAG pipeline.
ℹ️ This notebook requires an OpenAI API key.
Install Dependencies and Import Libraries
Run the cell below to install Git LFS, which we use to download our dataset.
!git lfs installInstall and import Python dependencies.
!pip install "ragas<0.1.1" pypdf arize-phoenix "openinference-instrumentation-llama-index<1.0.0" "llama-index<0.10.0" pandasimport pandas as pd
# Display the complete contents of dataframe cells.
pd.set_option("display.max_colwidth", None)Configure Your OpenAI API Key
Set your OpenAI API key if it is not already set as an environment variable.
import os
from getpass import getpass
import openai
if not (openai_api_key := os.getenv("OPENAI_API_KEY")):
openai_api_key = getpass("🔑 Enter your OpenAI API key: ")
openai.api_key = openai_api_key
os.environ["OPENAI_API_KEY"] = openai_api_keyGenerate Your Synthetic Test Dataset
Curating a golden test dataset for evaluation can be a long, tedious, and expensive process that is not pragmatic — especially when starting out or when data sources keep changing. This can be solved by synthetically generating high quality data points, which then can be verified by developers. This can reduce the time and effort in curating test data by 90%.
Run the cell below to download a dataset of prompt engineering papers in PDF format from arXiv and read these documents using LlamaIndex.
!git clone https://huggingface.co/datasets/explodinggradients/prompt-engineering-papersfrom llama_index import SimpleDirectoryReader
dir_path = "./prompt-engineering-papers"
reader = SimpleDirectoryReader(dir_path, num_files_limit=2)
documents = reader.load_data()An ideal test dataset should contain data points of high quality and diverse nature from a similar distribution to the one observed during production. Ragas uses a unique evolution-based synthetic data generation paradigm to generate questions that are of the highest quality which also ensures diversity of questions generated. Ragas by default uses OpenAI models under the hood, but you’re free to use any model of your choice. Let’s generate 100 data points using Ragas.
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context
TEST_SIZE = 25
# generator with openai models
generator = TestsetGenerator.with_openai()
# set question type distribution
distribution = {simple: 0.5, reasoning: 0.25, multi_context: 0.25}
# generate testset
testset = generator.generate_with_llamaindex_docs(
documents, test_size=TEST_SIZE, distributions=distribution
)
test_df = testset.to_pandas()
test_df.head()You are free to change the question type distribution according to your needs. Since we now have our test dataset ready, let’s move on and build a simple RAG pipeline using LlamaIndex.
Build Your RAG Application With LlamaIndex
LlamaIndex is an easy to use and flexible framework for building RAG applications. For the sake of simplicity, we use the default LLM (gpt-3.5-turbo) and embedding models (openai-ada-2).
Launch Phoenix in the background and instrument your LlamaIndex application so that your OpenInference spans and traces are sent to and collected by Phoenix. OpenInference is an open standard built atop OpenTelemetry that captures and stores LLM application executions. It is designed to be a category of telemetry data that is used to understand the execution of LLMs and the surrounding application context, such as retrieval from vector stores and the usage of external tools such as search engines or APIs.
import phoenix as px
from llama_index import set_global_handler
session = px.launch_app()
set_global_handler("arize_phoenix")Build your query engine.
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.embeddings import OpenAIEmbedding
def build_query_engine(documents):
vector_index = VectorStoreIndex.from_documents(
documents,
service_context=ServiceContext.from_defaults(chunk_size=512),
embed_model=OpenAIEmbedding(),
)
query_engine = vector_index.as_query_engine(similarity_top_k=2)
return query_engine
query_engine = build_query_engine(documents)If you check Phoenix, you should see embedding spans from when your corpus data was indexed. Export and save those embeddings into a dataframe for visualization later in the notebook.
from phoenix.trace.dsl.helpers import SpanQuery
client = px.Client()
corpus_df = px.Client().query_spans(
SpanQuery().explode(
"embedding.embeddings",
text="embedding.text",
vector="embedding.vector",
)
)
corpus_df.head()Relaunch Phoenix to clear the accumulated traces.
px.close_app()
session = px.launch_app()Evaluate Your LLM Application
Ragas provides a comprehensive list of metrics that can be used to evaluate RAG pipelines both component-wise and end-to-end.
To use Ragas, we first form an evaluation dataset comprised of a question, generated answer, retrieved context, and ground-truth answer (the actual expected answer for the given question).
from datasets import Dataset
from tqdm.auto import tqdm
import pandas as pd
def generate_response(query_engine, question):
response = query_engine.query(question)
return {
"answer": response.response,
"contexts": [c.node.get_content() for c in response.source_nodes],
}
def generate_ragas_dataset(query_engine, test_df):
test_questions = test_df["question"].values
responses = [generate_response(query_engine, q) for q in tqdm(test_questions)]
dataset_dict = {
"question": test_questions,
"answer": [response["answer"] for response in responses],
"contexts": [response["contexts"] for response in responses],
"ground_truth": test_df["ground_truth"].values.tolist(),
}
ds = Dataset.from_dict(dataset_dict)
return ds
ragas_eval_dataset = generate_ragas_dataset(query_engine, test_df)
ragas_evals_df = pd.DataFrame(ragas_eval_dataset)
ragas_evals_df.head()Check out Phoenix to view your LlamaIndex application traces.
print(session.url)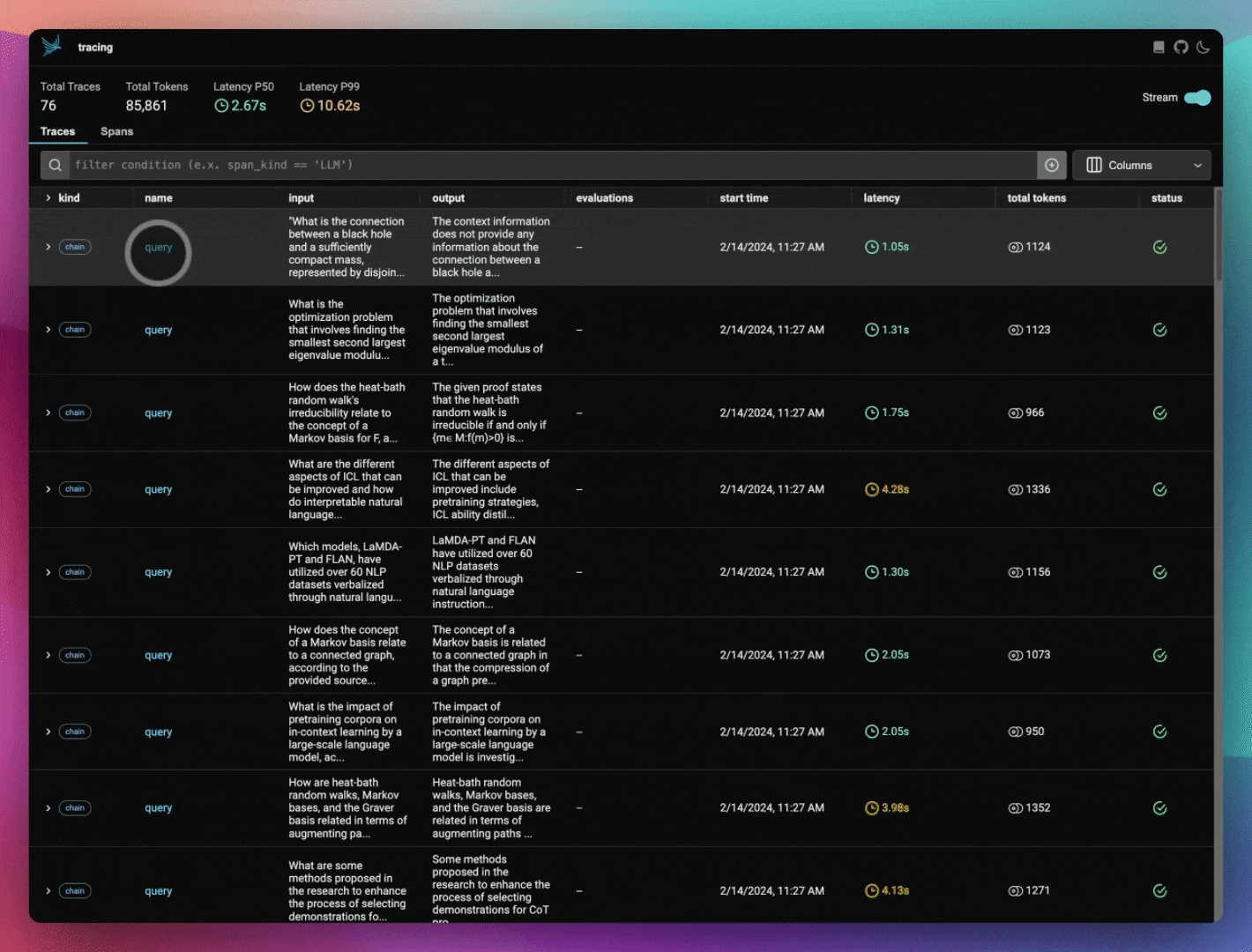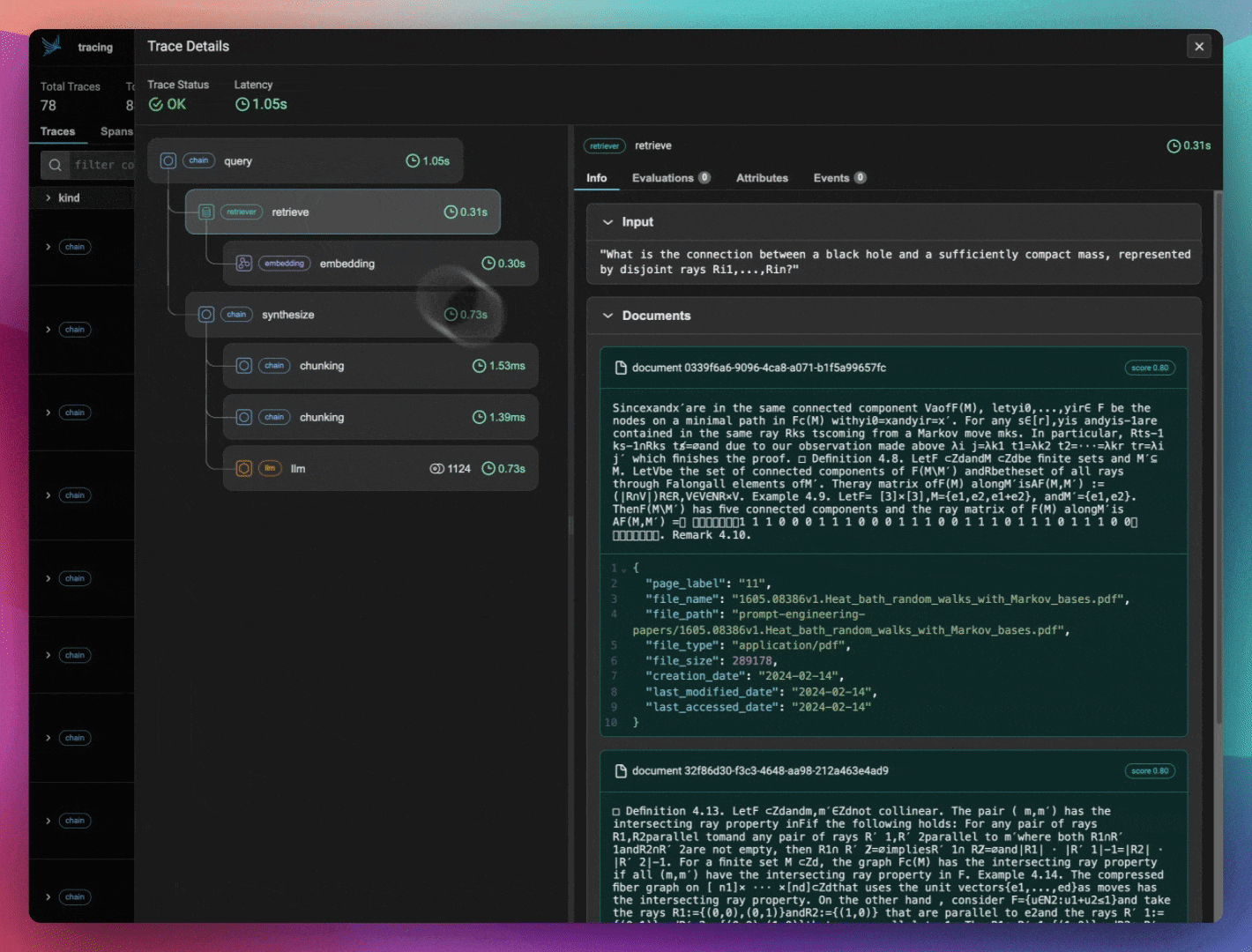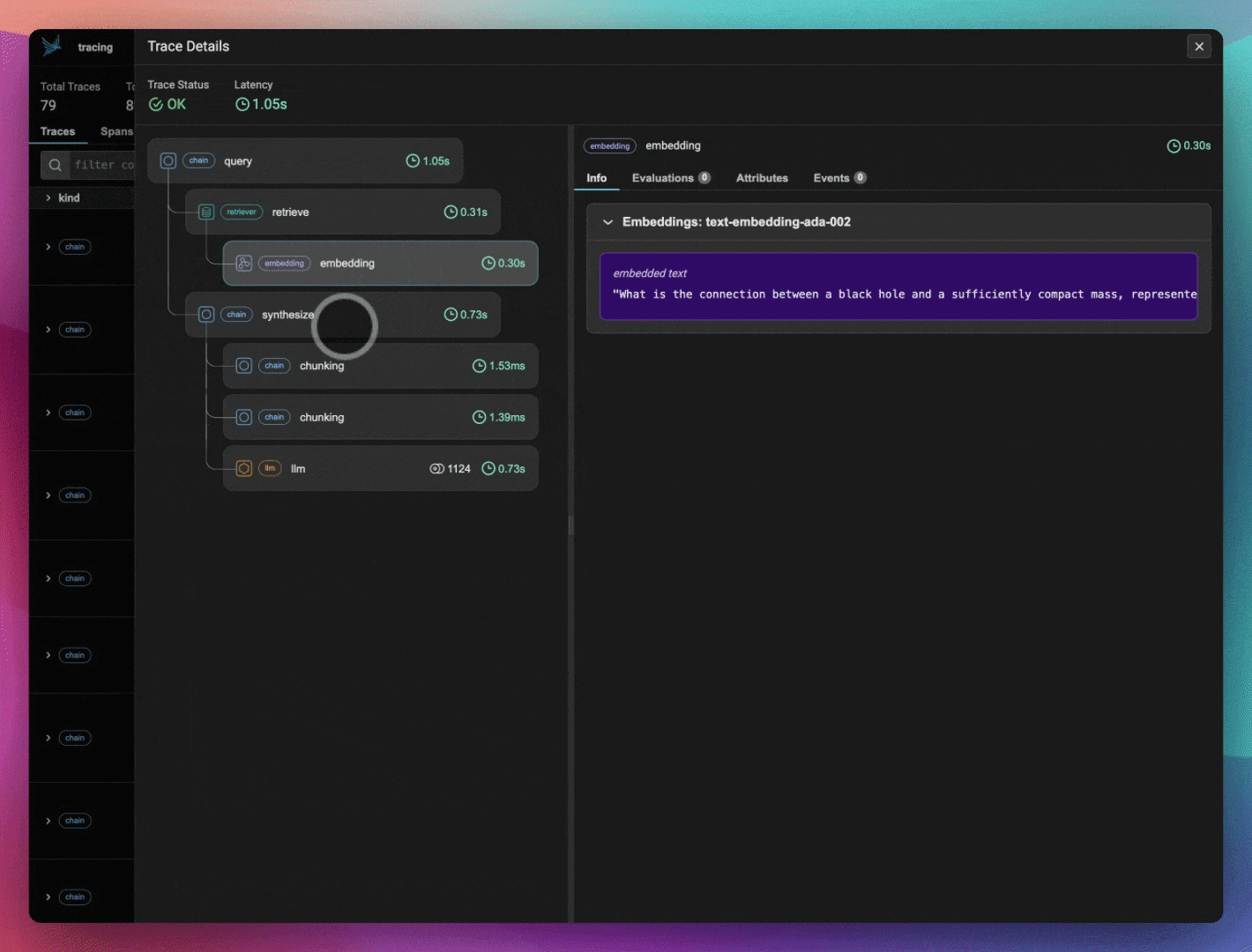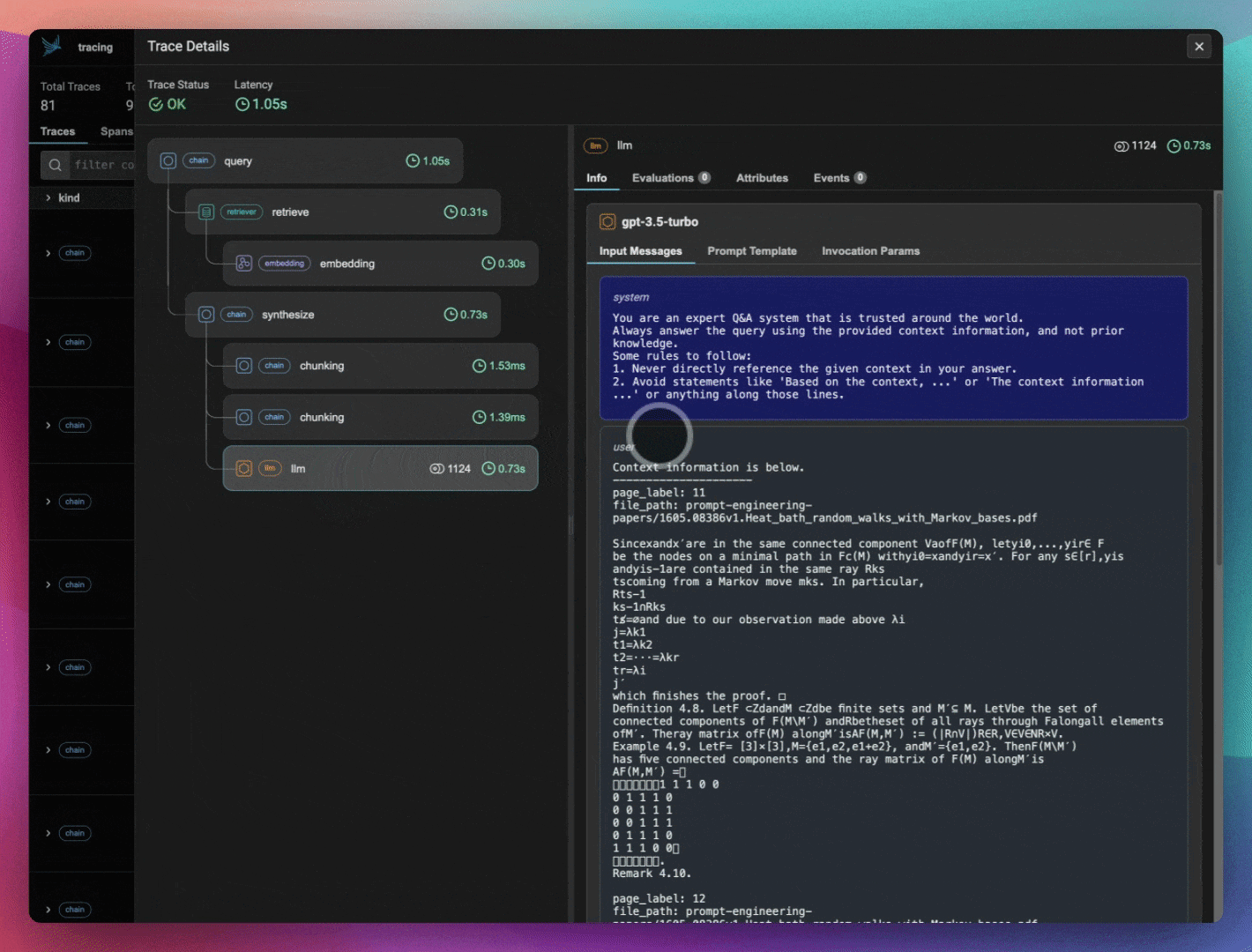
We save out a couple of dataframes, one containing embedding data that we’ll visualize later, and another containing our exported traces and spans that we plan to evaluate using Ragas.
# dataset containing embeddings for visualization
query_embeddings_df = px.Client().query_spans(
SpanQuery().explode(
"embedding.embeddings", text="embedding.text", vector="embedding.vector"
)
)
query_embeddings_df.head()from phoenix.session.evaluation import get_qa_with_reference
# dataset containing span data for evaluation with Ragas
spans_dataframe = get_qa_with_reference(client)
spans_dataframe.head()Ragas uses LangChain to evaluate your LLM application data. Let’s instrument LangChain with OpenInference so we can see what’s going on under the hood when we evaluate our LLM application.
from phoenix.trace.langchain import LangChainInstrumentor
LangChainInstrumentor().instrument()Evaluate your LLM traces and view the evaluation scores in dataframe format.
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_correctness,
context_recall,
context_precision,
)
evaluation_result = evaluate(
dataset=ragas_eval_dataset,
metrics=[faithfulness, answer_correctness, context_recall, context_precision],
)
eval_scores_df = pd.DataFrame(evaluation_result.scores)Submit your evaluations to Phoenix so they are visible as annotations on your spans.
from phoenix.trace import SpanEvaluations
# Assign span ids to your ragas evaluation scores (needed so Phoenix knows where to attach the spans).
eval_data_df = pd.DataFrame(evaluation_result.dataset)
assert eval_data_df.question.to_list() == list(
reversed(spans_dataframe.input.to_list()) # The spans are in reverse order.
), "Phoenix spans are in an unexpected order. Re-start the notebook and try again."
eval_scores_df.index = pd.Index(
list(reversed(spans_dataframe.index.to_list())), name=spans_dataframe.index.name
)
# Log the evaluations to Phoenix.
for eval_name in eval_scores_df.columns:
evals_df = eval_scores_df[[eval_name]].rename(columns={eval_name: "score"})
evals = SpanEvaluations(eval_name, evals_df)
px.Client().log_evaluations(evals)If you check out Phoenix, you’ll see your Ragas evaluations as annotations on your application spans.
print(session.url)
Visualize and Analyze Your Embeddings
Embeddings encode the meaning of retrieved documents and user queries. Not only are they an essential part of RAG systems, but they are immensely useful for understanding and debugging LLM application performance.
Phoenix takes the high-dimensional embeddings from your RAG application, reduces their dimensionality, and clusters them into semantically meaningful groups of data. You can then select the metric of your choice (e.g., Ragas-computed faithfulness or answer correctness) to visually inspect the performance of your application and surface problematic clusters. The advantage of this approach is that it provides metrics on granular yet meaningful subsets of your data that help you analyze local, not merely global, performance across a dataset. It’s also helpful for gaining intuition around what kind of queries your LLM application is struggling to answer.
We’ll re-launch Phoenix as an embedding visualizer to inspect the performance of our application on our test dataset.
query_embeddings_df = query_embeddings_df.iloc[::-1]
assert ragas_evals_df.question.tolist() == query_embeddings_df.text.tolist()
assert test_df.question.tolist() == ragas_evals_df.question.tolist()
query_df = pd.concat(
[
ragas_evals_df[["question", "answer", "ground_truth"]].reset_index(drop=True),
query_embeddings_df[["vector"]].reset_index(drop=True),
test_df[["evolution_type"]],
eval_scores_df.reset_index(drop=True),
],
axis=1,
)
query_df.head()
query_schema = px.Schema(
prompt_column_names=px.EmbeddingColumnNames(
raw_data_column_name="question", vector_column_name="vector"
),
response_column_names="answer",
)
corpus_schema = px.Schema(
prompt_column_names=px.EmbeddingColumnNames(
raw_data_column_name="text", vector_column_name="vector"
)
)
# relaunch phoenix with a primary and corpus dataset to view embeddings
px.close_app()
session = px.launch_app(
primary=px.Dataset(query_df, query_schema, "query"),
corpus=px.Dataset(corpus_df.reset_index(drop=True), corpus_schema, "corpus"),
)Once you launch Phoenix, you can visualize your data with the metric of your choice with the following steps:
- Select the vector embedding,
- Select Color By > dimension and then the dimension of your choice to color your data by a particular field, for example, by Ragas evaluation scores such as faithfulness or answer correctness,
- Select the metric of your choice from the metric dropdown to view aggregate metrics on a per-cluster basis.
Recap
Congrats! You built and evaluated a LlamaIndex query engine using Ragas and Phoenix. Let’s recap what we learned:
- With Ragas, you bootstraped a test dataset and computed metrics such as faithfulness and answer correctness to evaluate your LlamaIndex query engine.
- With OpenInference, you instrumented your query engine so you could observe the inner workings of both LlamaIndex and Ragas.
- With Phoenix, you collected your spans and traces, imported your evaluations for easy inspection, and visualized your embedded queries and retrieved documents to identify pockets of poor performance.
This notebook is just an introduction to the capabilities of Ragas and Phoenix. To learn more, see the Ragas and Phoenix docs.
If you enjoyed this tutorial, please leave a ⭐ on GitHub: