

Monitor Unstructured Data with Arize

Aparna Dhinakaran
Co-founder & Chief Product Officer
Want to try it out? Sign up for your free account, and follow along with our tutorial.
We are incredibly excited to announce the first release of our embedding drift monitoring and embedding analysis product. This offering and the architecture that underpins it are the culmination of over a year of work and research, and we could not be prouder to launch a beta version of the product today.
Why Embeddings?
We see embeddings as fundamental to AI and deep learning. Embeddings are the core of how deep learning models represent structures, mappings, hierarchy and manifolds that are learned by models. They proliferate modern deep learning from transformers to encoders, decoders, auto-encoders, recommendation engines, matrix decomposition, SVD, graph neural networks, and generative models — they are simply everywhere.
Embeddings predominate because they are fundamental to how the next generation of models work. Given the industry has only scratched the surface in understanding what and how information is compressed and mapped into embeddings, we hope that what we are building will usher in the next generation of analytical systems focused on embeddings and offer practitioners world class tools to troubleshoot models and data.
As a company focused on building software to help humans understand how AI works, fix it when it’s broken, and improve it, it was natural to move in this direction — but not obvious from the start. It has been an amazing journey over the last year scaling to track hundreds of billions predictions a month across hundreds of platform users and we have learned a lot, channeling those learnings into an architecture for embedding analysis that is the first of its kind.
What We Are Hearing From Top Machine Learning Teams
According to multiple estimates, 80% of data generated is unstructured images, text, or audio. Unfortunately, ML teams working with this unstructured data are shipping models blind.
Here are several key challenges of working with deep learning models identified from conversations with clients and top ML teams:
- ML teams lack visibility into what’s happening to the data when an unstructured data model is put into production. With no monitoring for drift or performance, picking up on upstream data quality issues or change in the data is practically impossible.
- Deep learning models are expensive to train. Since labeling is expensive, ML teams often only label as much as 0.1% of their data. When models are then put into production, it often results in new patterns emerging that the model hadn’t encountered in training. Gone unnoticed, these new patterns lead to performance degradation.
In conversations with top ML organizations, we are also seeing a growing number that have structured and unstructured inputs combined into one model. As more teams head in this direction, they require an ML observability solution that spans both structured and unstructured models.
Arize Releases Embeddings Support
With this release, teams can log models with both structured and unstructured data to Arize for monitoring. By monitoring embeddings of their unstructured data, teams can proactively identify when their unstructured data is drifting. Troubleshooting is simple with interactive visualizations to help isolate new or emerging patterns, underlying data changes, and data quality issues.
Arize’s interactive UMAP implementation with both 2D and 3D views enables teams to quickly visualize their high dimensional data in a low dimensional space. By visualizing drift between embeddings with production data layered on top of training data, teams are able to see groupings of embeddings and easily identify patterns or data that were not present in training.
Armed with the raw data tied to each embedding, teams also have the actionable insight they need to troubleshoot their deep learning models. Whether exporting a problematic segment for high-value labeling or identifying upstream data quality issues to dig into, ML teams are no longer in the dark when shipping their unstructured data models.
Example Workflow Using Arize
Embedding representations hold the key to workflows that allow teams to continually improve models and data. Internal embedding representations can be extracted from almost all types of deep learning models, giving an internal glimpse at what the model is “seeing.”
Let’s walk through an example of ML Observability for unstructured data in Arize. In this example, an ecommerce company has a model with both structured data, such as age and gender, alongside unstructured data, such as text reviews of its products, to better understand its consumers’ reactions to its product offerings.
The ecommerce company generates embeddings that represent the text reviews it receives, training its model on sentiment classification. The model reads a review and classifies the emotion as positive, neutral, or negative.
By logging the model to Arize, the company can monitor for drift and performance across all of their inputs, structured and unstructured.
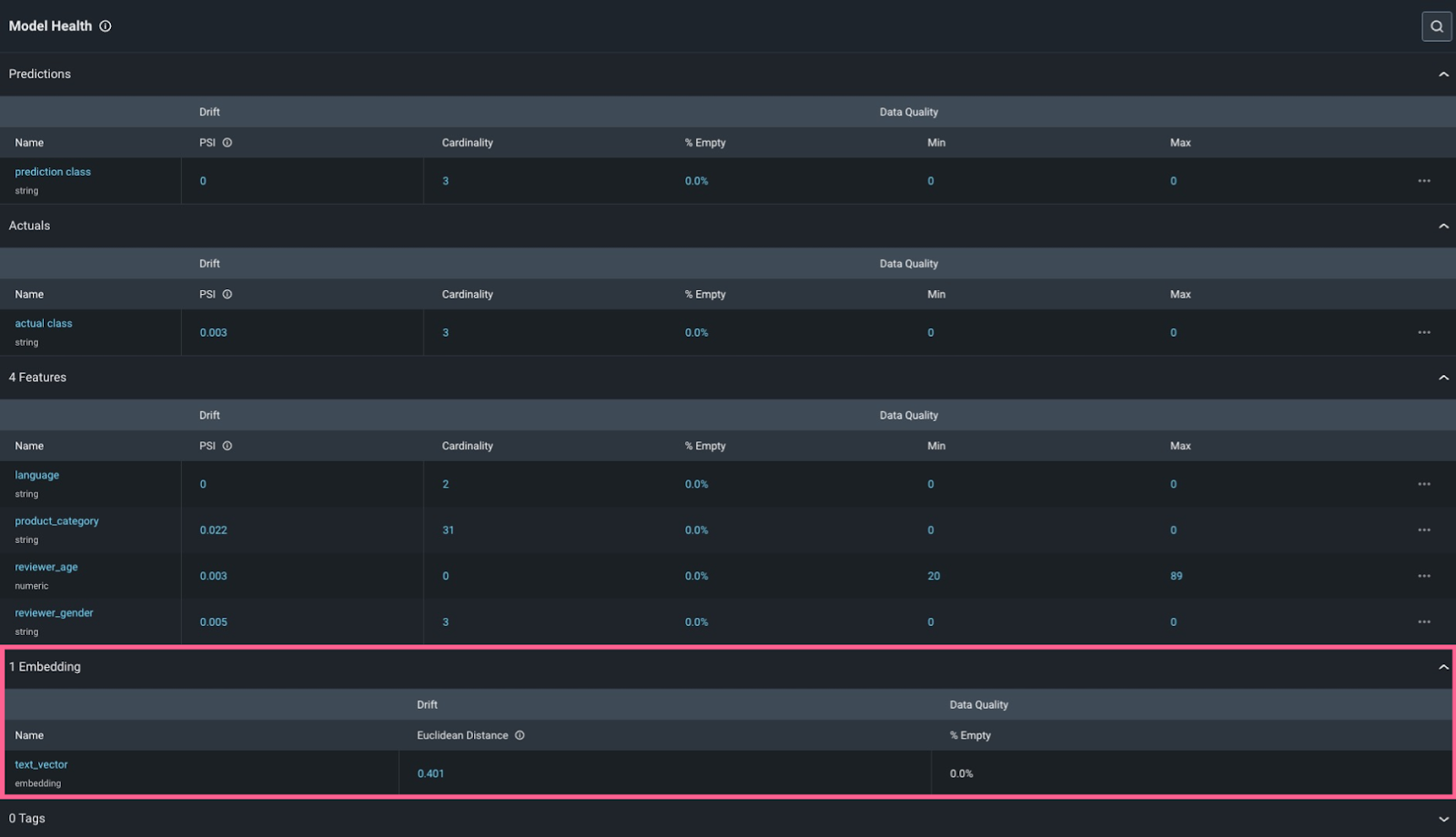
Embedding model input in Arize
By clicking into the embedding feature, we can see that there has been an increase in drift.
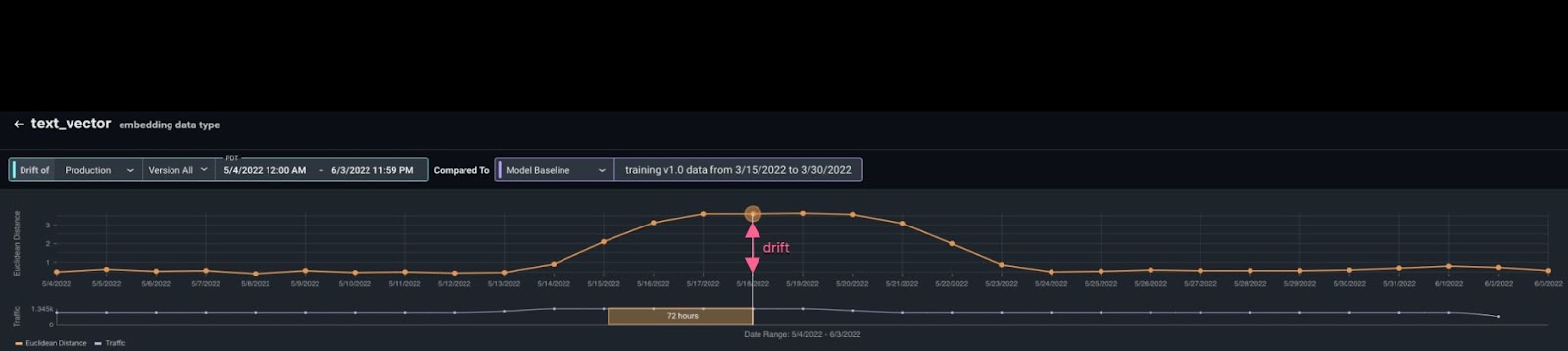
Embedding drift
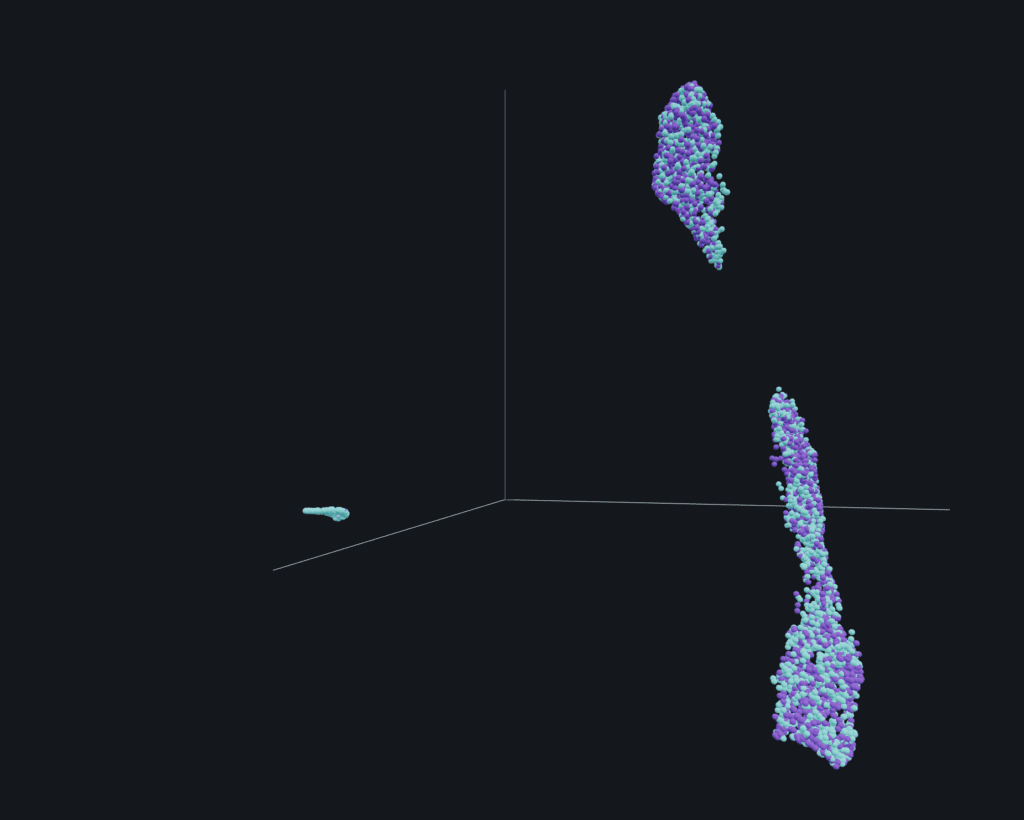
To better visualize what may be happening with the data in order to troubleshoot, Arize generates a 2D → 3D UMAP.
By visualizing their embeddings on a UMAP plot with production embeddings overlaid over training embeddings, the company sees there is a new pattern in production that was not present in training.
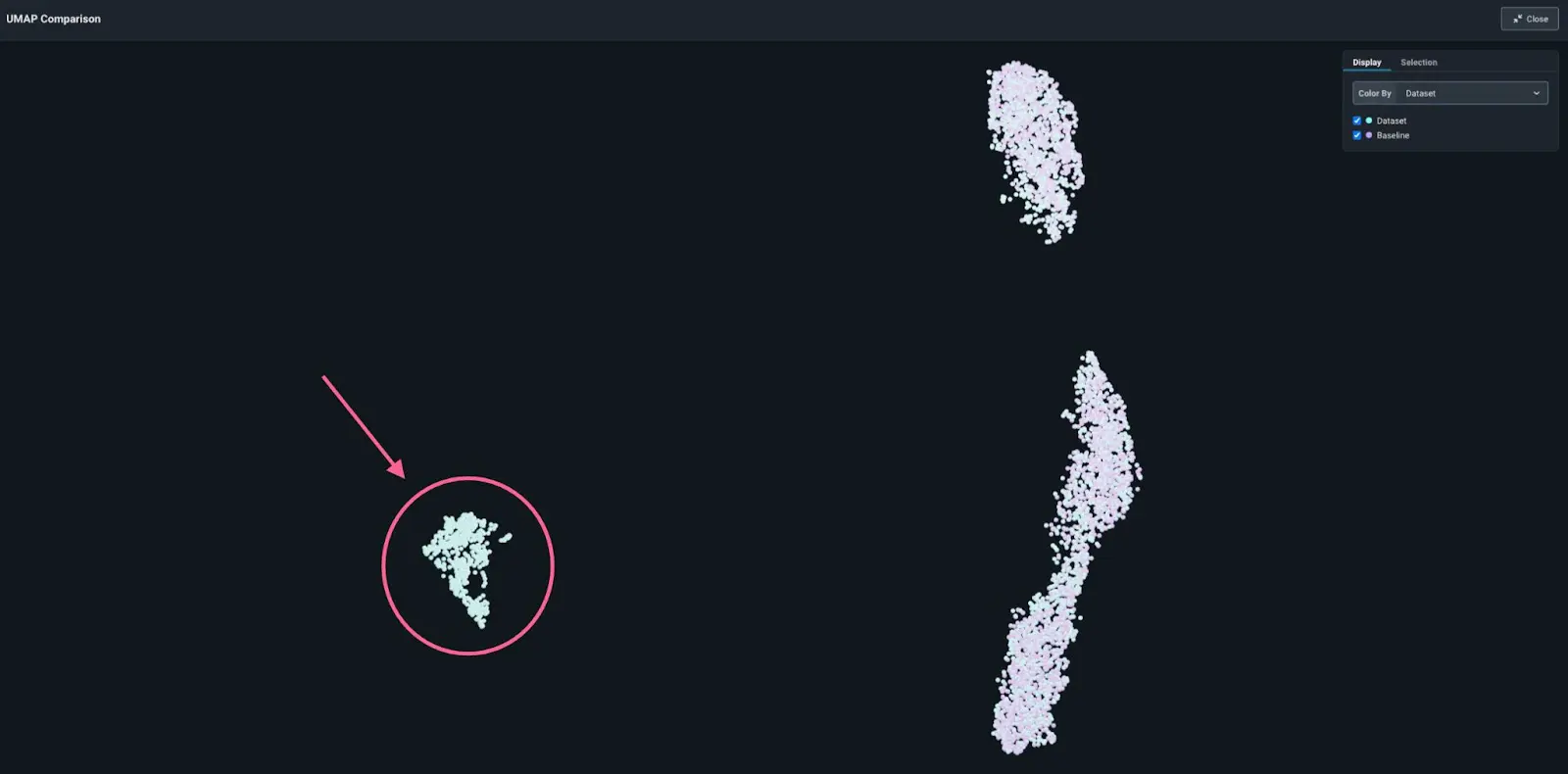
2D UMAP visualization: new pattern identified
Clicking into this new area and looking at the raw text in the reviews, we see that these reviews are in Spanish. Since the team’s ML model was only trained on English, the model cannot correctly classify the sentiment of these reviews. With this new insight, the team can go and retrain their model to include Spanish so that they can understand the sentiment of all their customers – not only their English-speaking ones.

3D UMAP visualization: embedding from production selected, raw data shows review in Spanish, actual label doesn’t match predicted
Conclusion
So many amazing technology innovations are happening in the unstructured data space, from DALL-E 2 to GPT-3. As AI gets more and more complex, Arize is here to help troubleshoot even the most complex of models. We’re so excited to continue moving the industry forward with this release.
Want to learn more about embeddings and unstructured data and hear from leading ML teams such as OpenAI, Hugging Face, Pachyderm, and Labelbox? Watch the on-demand Arize:Observe Unstructured sessions here.