
Three Pitfalls To Avoid With Embeddings

Aparna Dhinakaran
Co-founder & Chief Product Officer
Introduction
Let’s say that you have read a very helpful post demystifying embeddings and you’re really excited. Your social media company can certainly use them, so you fire up your notebook and start typing away. As the clock ticks, excitement turns to frustration and you wonder: how do people even do this?
There are a few gotcha moments with embeddings. No post could ever cover every scenario, but this one will attempt to give you some practical advice in three areas:
- how to version your project,
- how to monitor your embedding once it goes live, and
- how to get an intuitive sense for the quality of your embeddings.
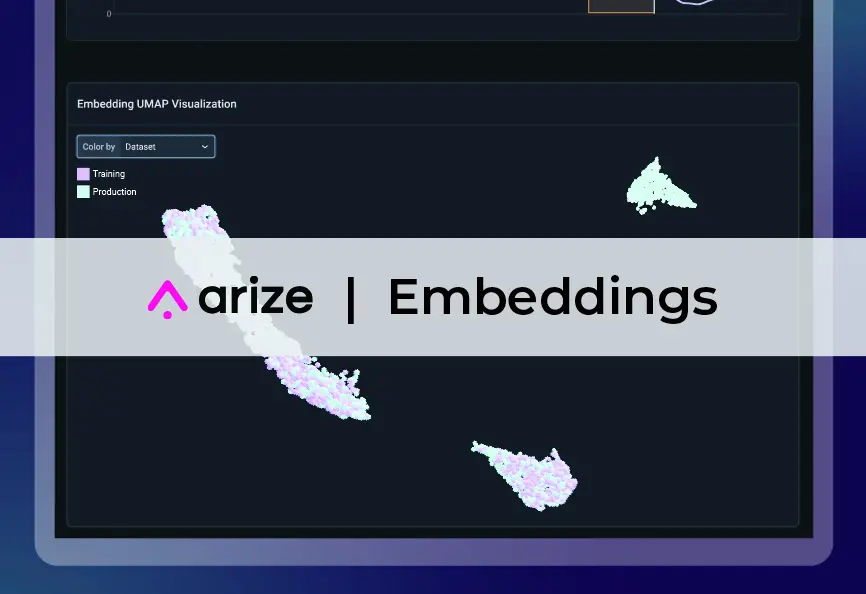
Monitoring Embeddings
Embeddings are not static. It makes sense if you think about it—new concepts appear in the real world all the time, and humanity is constantly updating old paradigms.
Now that your embedding is out, you need a way to monitor it. Most importantly, when does it lose meaning? This is a non-trivial problem, but luckily there is a right answer.
Let’s say your social media company now has an awesome text embedding in production. Being the awesome engineer that you are, you have set up monitoring for your model. You monitor words as they come in and keep track of average distance between cluster centroids. This number has some random fluctuations, but this level is usually predictable, so you can set up a reasonable threshold above which you will receive an alert. This is in part possible because you have a point of comparison with your freshly trained embedding when you first released it.
Conclusion
Embeddings are a powerful tool, but like all power tools, some know-how is essential to wield them properly. Knowing how to properly version embeddings will save you lots of heartache while iterating on your code. Once your embedding is trained, you can begin getting some understanding for how well it does using dimensionality reduction and graphing. Once out in production, appropriate embedding monitoring techniques will ensure consistent value to your customers.
Start Your Journey
Want to learn more? Read about monitoring unstructured data and see why getting started with embeddings is easier than you think. Want to try out embedding analysis and embedding drift monitoring leveraging UMAP 2D and 3D visualizations? Sign up for a free Arize account, and follow along with our colabs.