






As ML pipelines evolve and become integral to business decisions, more and more data gets consumed and transformed during the lifecycle of building and deploying models. Mobileye, as an isolated example, has collected over 200 petabytes of data to power its self-driving car efforts – or 16 million one-minute videos, each consisting of thousands of frames. Many recommendation engines process tens of billions of inferences per day. These are just two examples, but clearly ML pipelines solidly live in the realm of “big data.”
To process this data, Kafka is one of the most widely used pub/sub frameworks to power event-driven pipelines. It has several benefits including allowing asynchronous processing, transforming, persisting, and ultimately inferring with these events. From a purely engineering perspective, this decoupling and scalability allows parallel processing of all of these events while lowering overall lag between data ingestion to the ultimate prediction. Kafka also has many other benefits including its relative reliability, fairly easy configuration and operation, and – if implemented correctly – its ability to ensure idempotency. As our chief architect says, “all datasets are streams, some are just bounded.”
Now that we established that Kafka along other pub/sub solutions like Gazette can be crucial parts of ML pipelines, the natural next step is to observe these inputs and predictions that drive millions or billions of model predictions every day to ensure your model is performing optimally.
Model Pipelines Using Kafka
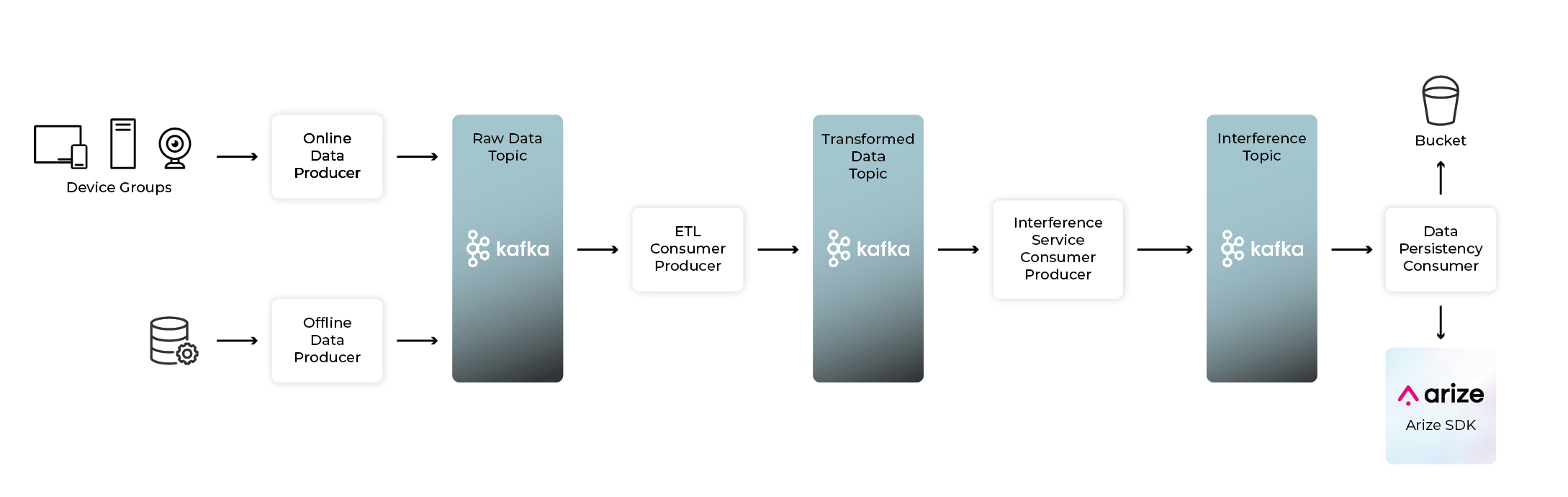
Kafka messages in the example above can be thought of as consisting of a model’s input features, its relevant metadata (also known as tags in the Arize platform), and the predictions themselves. Ingestion of this data into the Arize platform can be done in two ways. The first is Arize’s native Object Store Integration, which will be a topic of a future blog. The second and more event-streaming focused way, which we are covering in this blog, is leveraging a simple Kafka consumer which consumes a micro-batch of incoming events and publishes them to Arize so you can observe your model in real time.
In the following example, we consume a microbatch of up to 100,000 events, or up to 10 seconds. These are arbitrary configuration choices and should match your use case. We consume these events, deserialize them, and batch them together prior to sending them over the wire into the Arize platform. Since we previously established idempotency is important on any production system of record, this micro-batching amortizes any round-trip overhead. Furthermore, notice that we disable automatic partition offset commits and manually commit the offsets after data has been persisted at the Arize edge. This ensures no data loss in the case of service disruption in any step of the process. Consumers can be set to consume all partitions on a topic, or for larger clusters can be set to consume specific partitions – allowing for parallelization of the consumer and further increasing throughput for truly large data processing, ensuring data is always ingested in real time and minimizing any potential latency. The Arize platform is architected to scale with the load. The Arize team comes from some of the largest data streaming companies in the world – including Adobe, Apple, Google, Lyft, Slack, and Uber just to name a few – so if you need to, or simply want to, go ahead and add a consumer per partition and see how fast you can ingest all your data.
Built to Scale
Arize is built to scale, and we provide several easy and simple ways to ingest data. Kafka event streams is just another simple example of how you can quickly integrate Arize in your existing pipeline for real-time and scalable model monitoring without employing sampling techniques. Once your ground truths come in – which may take a few seconds in the case of advertising or months in the case of churn or fraud models, for example – you can simply send this data into Arize using the SDK (e.g this Kafka example) or File Import Jobs and the platform joins your ground truths with the original predictions. This unlocks ML performance tracing, a crucial step in improving your models.
Sign Up for Your Free Account
Want to try this out? Sign up for your free account, peruse our docs, and join our vibrant Slack community. We’re happy to engage and get you on the path of improving your models and truly understanding the why and how of your models.