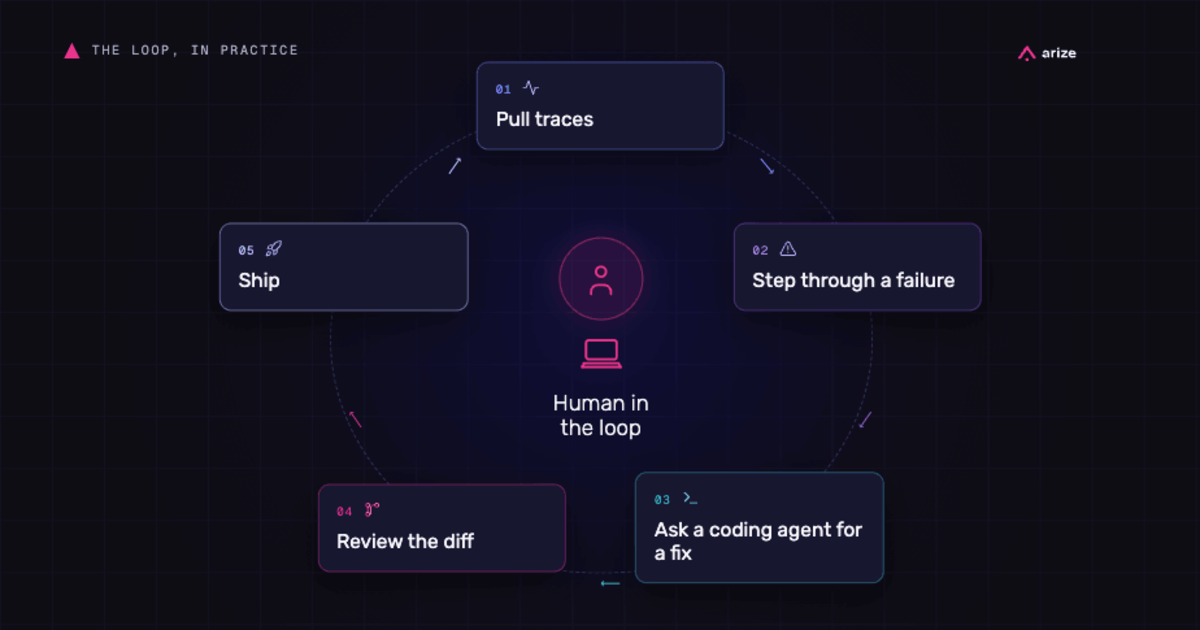
Special thanks to Duncan McKinnon for his contributions to this post
Tracing Groq Applications with Arize
If you’re working with LLMs and using the Groq package to make your model calls, capturing telemetry data is crucial for debugging, monitoring, and improving your system’s performance. In this post, we’ll walk through a quick guide on how to trace a Groq application and visualize telemetry data using Arize Phoenix.
Note: This instrumentor works with both Phoenix and Arize’s enterprise platform.
Setting Up Telemetry Tracing for Groq
In this example, we’ll use Phoenix to capture and visualize telemetry data from a Groq-based application. The first step is to set up a few packages, including Groq, the Arize Phoenix package, and the new Groq Instrumentation Package, which automatically wraps your LLM model calls and tracks key data points such as token usage, model inputs, and outputs.
Step 1: Install and Import the Necessary Packages
To get started, import the necessary packages. In addition to Groq and Phoenix, we’ll use the new Groq Instrumentation Package to auto-instrument your LLM model calls.
! pip install -q openinference-instrumentation-groq groq arize-phoenixStep 2: Set Up Environment Variables
Next, you’ll need to set up your Groq API Key as an environment variable, which allows the Groq package to make the appropriate model calls.
from getpass import getpass
import os
if not (groq_api_key := os.getenv("GROQ_API_KEY")):
groq_api_key = getpass("🔑 Enter your Groq API key: ")
os.environ["GROQ_API_KEY"] = groq_api_key
Once your environment is configured, you’re ready to launch a local instance of Phoenix, which will allow us to capture and visualize the telemetry data.
Step 3: Launch Phoenix Locally
In this step, we’ll launch a local Phoenix instance. Phoenix can be run in multiple ways: you can self-host it, use a cloud version, or run it locally. For this example, we’ll stick to the local version for simplicity.
import phoenix as px
session = px.launch_app()This command will spin up a local URL where Phoenix will run, and it will serve as the central hub for viewing your captured traces. If you’re self-hosting Phoenix, go ahead and skip this step.
Step 4: Connect Your Application to Phoenix
Once Phoenix is up and running, connect your Groq application to Phoenix so that it can send telemetry data. Use the register function for this:
from phoenix.otel import register
tracer_provider = register()
Note: If you’re self-hosting Phoenix, be sure to add the endpoint argument to the register call to point it towards your instance.
Step 5: Auto-Instrumentation with Groq Instrumentation Package
This is where the magic happens. The Groq Instrumentation Package will automatically wrap your Groq calls, allowing you to track important metrics like token usage, latency, and the inputs/outputs of each model call.
from openinference.instrumentation.groq import GroqInstrumentor
GroqInstrumentor().instrument(tracer_provider=tracer_provider)From here on, every Groq call you make will be automatically traced and sent to Phoenix. You don’t have to modify your Groq code to start gathering telemetry—just go about your usual workflow, and the data will be captured seamlessly.
Step 6: Make Model Calls and Capture Traces
Now, you can run your Groq calls and see them show up in Phoenix. Let’s send a few queries:
from groq import Groq
# Groq client automatically picks up API key
client = Groq()
questions = [
"Explain the importance of low latency LLMs",
"What is Arize Phoenix and why should I use it?",
"Is Groq less expensive than hosting on Amazon S3?"
]
# Requests sent to LLM through Groq client are traced to Phoenix
chat_completions = [
client.chat.completions.create(
messages=[
{
"role": "user",
"content": question,
}
],
model="mixtral-8x7b-32768",
) for question in questions
]
for chat_completion in chat_completions:
print("\n------\n" + chat_completion.choices[0].message.content)You should see each call logged in Phoenix, along with all the metadata such as token usage, inputs, outputs, and latency.
Step 7: Visualize Your Traces in Phoenix
Once you’ve executed some queries, you can head over to the Phoenix interface and dive into the telemetry. Each trace will show the details of the inputs and outputs, the model used, and various performance metrics. You can click into individual traces to explore token usage, model latency, and any potential issues that may arise in production.
Phoenix offers a user-friendly UI where you can debug your application, even if it’s handling multiple users or thousands of concurrent queries. It scales seamlessly, capturing all the relevant traces for every model call your app makes.
Beyond simply tracing calls, Phoenix also supports adding labels and evaluations to your traces. This allows you to run deeper analysis on the performance and quality of your LLM applications, offering more insights into your system’s behavior over time.
Why Arize Phoenix?
Whether you’re working with a small prototype or scaling up to production, Arize makes tracing, debugging, and evaluating LLM calls straightforward. It captures everything you need to optimize your application, from token usage to latency and beyond.
And it’s totally free and 100% open-source.
We’d love to hear your feedback, and if you’re already using Phoenix, don’t forget to give us a star on GitHub ⭐️!
Hope you enjoy the rest of your day—happy tracing!