- Build a movie recommendation agent using the Mastra framework and OpenAI models
- Instrument and trace your agent with Phoenix
- Create a dataset and upload it to Phoenix
- Define LLM-based evaluators to assess agent performance
- Run experiments to measure performance changes
- Iterate on the agent and re-run experiments to observe improvements
- A free Arize Phoenix Cloud account or local Phoenix instance
- An OpenAI API key
- Node.js and npm installed
Walkthrough
We will go through key code snippets on this page. The full implementation is available here:GitHub Repository
src/experiments
Agent Overview
The movie recommendation agent is built with Mastra and provides personalized movie recommendations using three specialized tools:- MovieSelector: Finds recent popular streaming movies by genre
- Reviewer: Reviews and sorts movies by rating
- PreviewSummarizer: Provides concise summaries for movies
Agent Structure
The agent is configured with clear instructions to use all three tools in sequence:Setup and Running the Agent
1
Install Dependencies
@ai-sdk/openai- OpenAI SDK for AI SDK@mastra/core- Mastra core framework@mastra/arize- Arize Phoenix Tracing integration@arizeai/phoenix-evals- Arize Phoenix Evals TS Library@arizeai/phoenix-client- Arize Phoenix Client library
2
Configure Environment
Create a
.env file in the root directory:3
Run the Agent
Start the Mastra dev server:Navigate to the Mastra Playground to interact with the movie recommendation agent. All agent runs, tool calls, and model interactions are automatically traced and sent to Phoenix.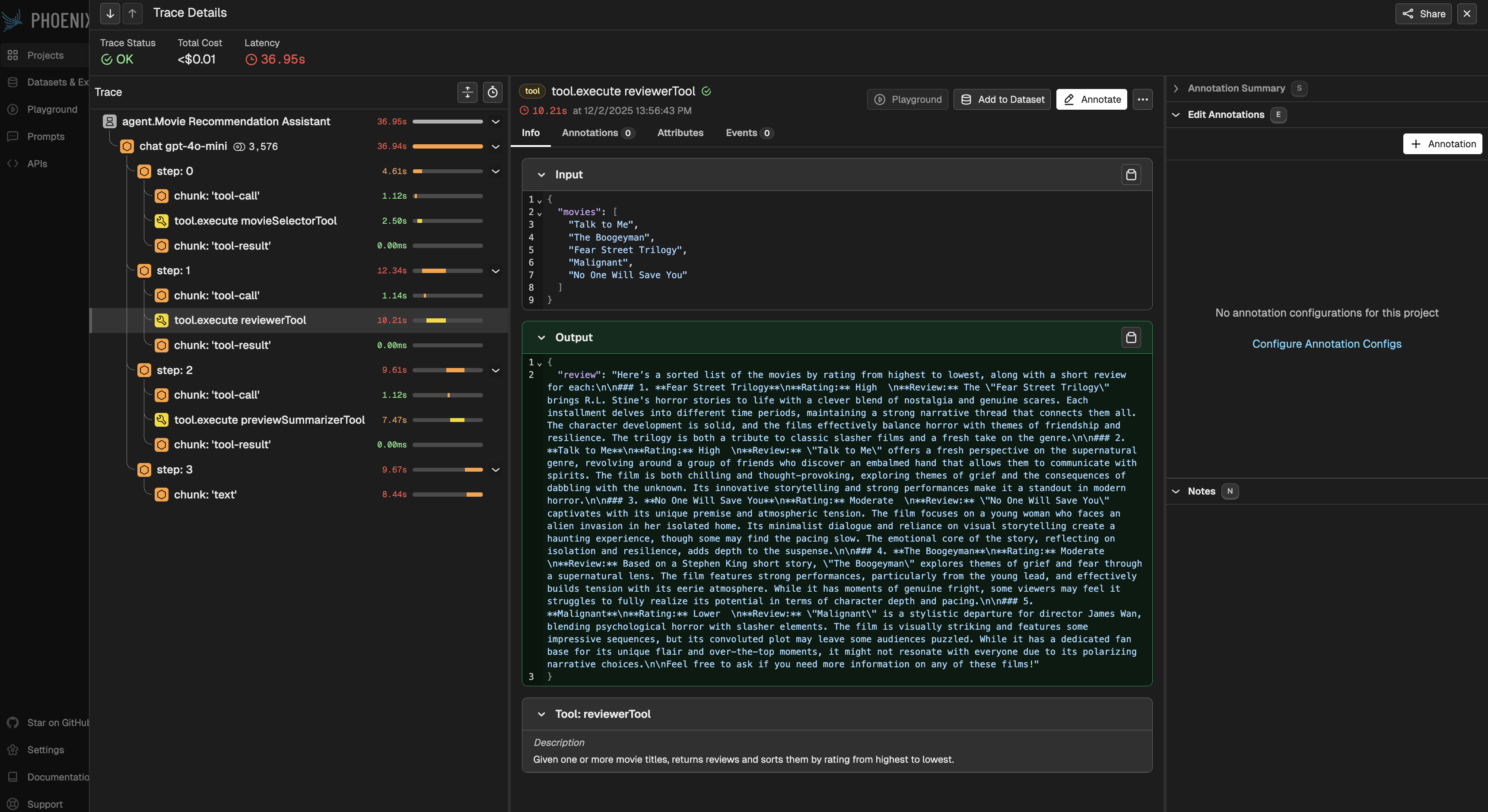
Setting Up Experiments
To systematically evaluate and improve the agent, we’ll set up experiments using Phoenix. This involves three main components:- Task Function: Wraps the agent to execute on dataset examples
- Dataset: Collection of inputs to test the agent
- Evaluators: Metrics to measure agent performance
The file for setting up the experiment is
src/experiments/configure-experiments.tsStep 1: Define the Task
The task function takes a dataset example and returns the agent’s output:Step 2: Create the Dataset
In order to experiment with our agent, we first need to define a dataset for it to run on. This provides a standardized way to evaluate the agent’s behavior across consistent inputs. We will use a small dataset for demo purposes:createOrGetDataset function will either retrieve an existing dataset by name or create a new one, making it safe to re-run the setup code.

Step 3: Define Evaluators
Next, we need a way to assess the agent’s outputs. This is where Evals come in. Evals provide a structured method for measuring whether an agent’s responses meet the requirements defined in a dataset—such as accuracy, relevance, consistency, or safety. In this tutorial, we will be using LLM-as-a-Judge Evals, which rely on another LLM acting as the evaluator. We define a prompt describing the exact criteria we want to evaluate, and then pass the input and the agent-generated output from each dataset example into that evaluator prompt. The evaluator LLM then returns a score along with a natural-language explanation justifying why the score was assigned. This allows us to automatically grade the agent’s performance across many examples, giving us quantitative metrics as well as qualitative insight into failure cases.{{variable}} for template variables, which Phoenix will automatically populate with the input and output from each experiment run.
Running the Experiment
With the task, dataset, and evaluators defined, we can now set up the experiment. This code is found insrc/experiments/run-experiments.ts :
- Run the task function on each example in the dataset
- Execute the evaluators on each task output
- Record all traces, spans, and evaluation results in Phoenix
- Provide aggregate metrics across all examples
Viewing Results in Phoenix
Once the experiment completes, open Phoenix to explore the results. You’ll be able to:- View Full Traces: Step through each agent run, including all tool calls and model interactions
- Review Aggregate Metrics: Understand overall performance across the dataset
- Examine Evaluation Results: See the LLM-as-a-Judge explanations for each eval
Iterating on the Agent
After analyzing the experiment results, you may identify areas for improvement. Let’s walk through an iteration cycle.1. Error Analysis
Review the traces and evaluation results to identify patterns:- Are certain types of queries performing poorly?
- Are tool calls being made correctly?
- Are the recommendations relevant to user requests?
MovieSelector tool isn’t returning movies that are highly relevant to the user’s specific criteria.
2. Make Improvements
Based on your analysis, update the agent code. In this case, let’s enhance theMovieSelector tool’s prompt to provide more relevant recommendations. Navigate to the file, src/mastra/tools/movie-selector-tool.ts, and find the prompt:
Before:
3. Re-Run the Experiment
After making changes, re-run the experiment with a new name to track the improvement:- Did the relevance scores improve?
- Are there fewer incorrect recommendations?
- What patterns changed in the evaluation explanations?
