When To Build Custom Evaluators
Arize-Phoenix ships with pre-built evaluators that are tested against benchmark datasets and tuned for repeatability. They’re a fast way to stand up rigorous evaluation for common scenarios. In practice, though, many teams work in specialized domains — such as medicine, finance, and agriculture — where models depend on proprietary data and domain knowledge and the expectations for accuracy are necessarily high. In these settings, a custom evaluator aligned to your label definitions is often the right path.
How To Build Custom Evals
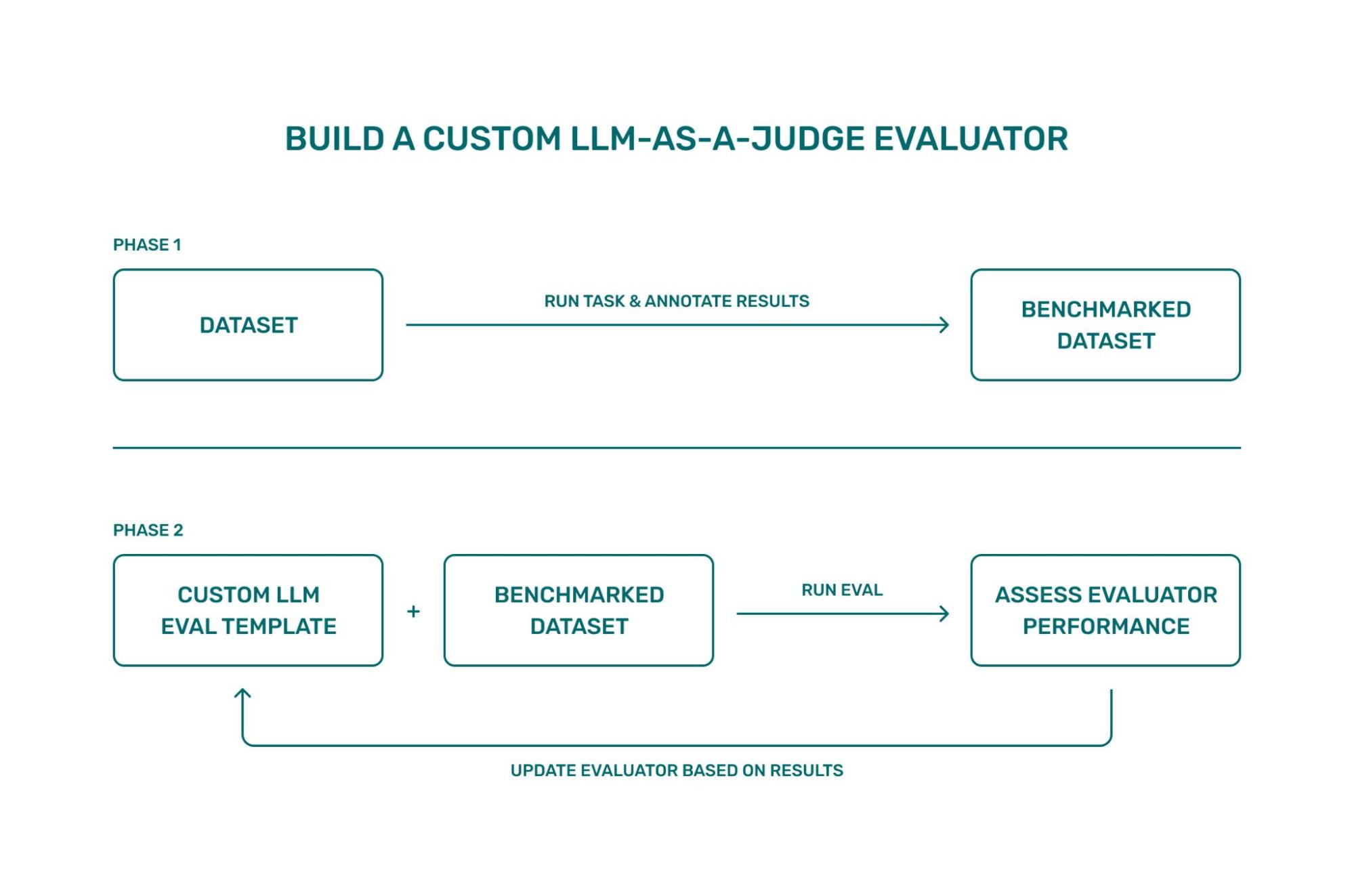
Today, we’re debuting several new tutorials showing how to build that evaluator end-to-end in both Arize AX and Phoenix. Learn how to instrument tracing, generate a small set of realistic examples, and annotate them to create a benchmark dataset.
The benchmark dataset should be designed to represent a wide variety of use cases. One way to do this is by looking at spans from production and pulling different types of examples.
From there, you define an evaluation template with clear label definitions (or scores for numerical analysis), run an experiment to compare the LLM judge’s labels to your annotations, and iterate on the template where the results disagree.
The goal is a judge that reflects how your application defines quality. By starting with a well-labeled dataset and tightening the template through quick iterations cycles, you can reach a level of evaluator performance that generalizes to your broader workload — whether you’re validating summaries, checking citation correctness in RAG, or assessing multi-step agent behavior.
Tutorials
You can run this notebook in either Phoenix or Arize AX.
| Context | Jump In | What You Need To Get Started | What This Covers |
| Arize Docs | Notebook | OpenAI key + free AX account (signup) | Configure tracing; generate traces from receipt images; annotate accuracy labels to form a benchmark dataset; export to a dataframe and create a dataset in AX; define an evaluation template with clear label definitions; run an experiment with a judge model; iterate on the template (tighten label rules; add a brief example); compare results across experiments. |
| Phoenix Docs | Notebook | OpenAI key + Phoenix account (signup) | Basically the same thing but with Phoenix! Auto-instrument to collect traces; annotate spans to build a benchmark dataset; upload the dataset; define a ClassificationTemplate with fixed label definitions; apply llm_classify with a judge model; run the experiment; refine the template (stricter criteria; optional one-shot example); review evaluator performance across iterations. |