


Co-Authored by Chris Cooning, Head of Product Marketing & Hakan Tekgul, ML Solutions Engineer & Cam Young.
TL;DR: An evaluation harness is the standardized infrastructure that decides what gets evaluated, runs the evaluation, and acts on the result. If you’ve seen an agent harness that coordinates LLM calls, retrieval, and tool use for a workflow, this is the same idea applied to evaluation: selecting data, running scoring methods, and routing the results. It’s the architectural backbone of a production AI evaluation practice because it turns evaluation from a one-off script into a repeatable system for scoring, routing, and improving AI behavior.
Most teams start agent evaluations manually.
That works when the question is narrow and the sample size is small: inspect 10 outputs, label a few failures, tweak the prompt, and run it again. But that workflow breaks down quickly. Ten examples become 100. A test set becomes 1,000. One experiment becomes five prompt or model variants. Then the system starts receiving production traffic, and evaluation has to keep up with live traces, failed tool calls, edge cases, and regressions before they reach users.
That scale changes the job of evaluation. You need more than human review, vibe checks, or one-off scripts. You need an evaluation harness that coordinates the inputs, scoring methods, and actions around evaluation.
An agent harness coordinates the steps an agent takes across LLM calls, retrieval, tools, and handoffs. An evaluation harness applies the same orchestration pattern to quality: it decides what behavior to inspect, how to score it, and what should happen when the score comes back.
That is the difference between checking outputs and operating an evaluation system.
Evaluation harnesses: a short definition
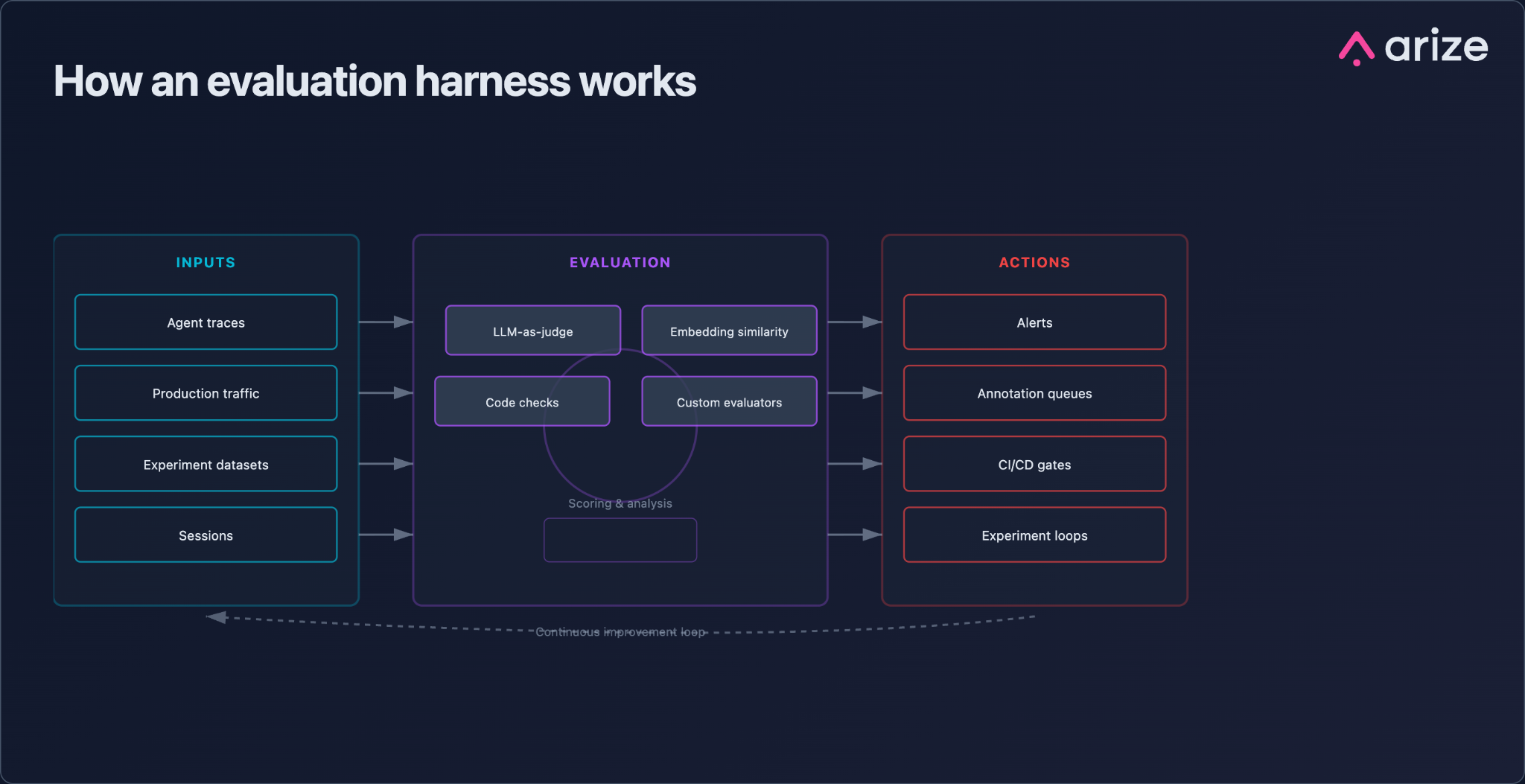
An evaluation harness is a three-stage pipeline that defines:
- What gets evaluated (the inputs)
- How it gets scored (the execution)
- What happens next when scores come back (the actions)
Those three stages are consistent whether you’re running a single hallucination check on one LLM call or an always-on quality program across millions of agent traces. The harness is what makes the practice repeatable, inspectable, and scalable beyond one engineer’s local script.
Why evaluation harnesses aren’t just benchmark runners anymore
If you searched this term two years ago, you likely landed on a description of EleutherAI’s lm-evaluation-harness or Stanford’s HELM. were built for model evaluation: load a model, run it against standardized benchmarks, and compare the results. Depending on the model and domain, that might mean general knowledge benchmarks like MMLU, reasoning benchmarks like GPQA or AIME, coding benchmarks like HumanEval or SWE-bench, or agentic task benchmarks like Terminal-Bench and OSWorld.
That definition still applies to pre-training and model research, where the goal is to compare model performance on standardized tasks. But production AI applications need a broader version of the pattern because the thing being evaluated is no longer just a model.
The AI systems being built today are agents, RAG pipelines, voice applications, copilots, and multi-step workflows. Their behavior depends on retrieved context, tool calls, memory, routing, user state, and the sequence of decisions made along the way. A correct final answer may come from a flawed trajectory. A failed final answer may trace back to a bad retrieval result, a malformed tool call, or a missed handoff.
That means failures show up across spans, traces, trajectories, and sessions rather than in static benchmark rows. Evaluating these systems requires a harness that can run on live execution data, support multiple scoring methods, and trigger downstream actions such as alerts, annotation queues, CI/CD gates, or experiment workflows.
That is the modern evaluation harness: a superset of the benchmark-runner definition, not a replacement for it.
Evaluation harness vs. benchmark runner: a primer
These terms get conflated because many early evaluation harnesses were built for benchmark running. Tools like lm-evaluation-harness and HELM helped researchers load a model, run it against standardized datasets, and compare results across common tasks.
That is still a valid kind of harness, but it is narrower than what production AI systems need.
Here’s a quick primer to explain the difference:
| Benchmark runner | Evaluation harness | |
|---|---|---|
| Evaluates | A model | A system (agent, RAG pipeline, workflow) |
| Inputs | Static academic datasets | Live traces, production slices, test queries or cases, golden datasets |
| Scoring | Accuracy vs. ground truth | Multi-method: LLM-as-Judge, code, embeddings, custom |
| Unit of work | Single prompt/response | Spans, traces, trajectories, sessions |
| Closes the loop | No. Produces a report. | Yes. Triggers alerts, queues, gates, experiments. |
| Example | lm-eval-harness, HELM | Arize AX |
Both are useful, but they serve different parts of the AI development lifecycle.
A benchmark runner helps you compare models against shared industry tasks. That is useful when you are choosing a base model, validating pre-training progress, or checking general capability.
An evaluation harness helps you understand how your specific application behaves on your specific task, with your prompts, tools, retrieval system, users, and production data. That is what you need once an AI application is being tested, shipped, monitored, and improved.
Most teams need both: benchmark runners to compare models, and evaluation harnesses to operate production AI systems.
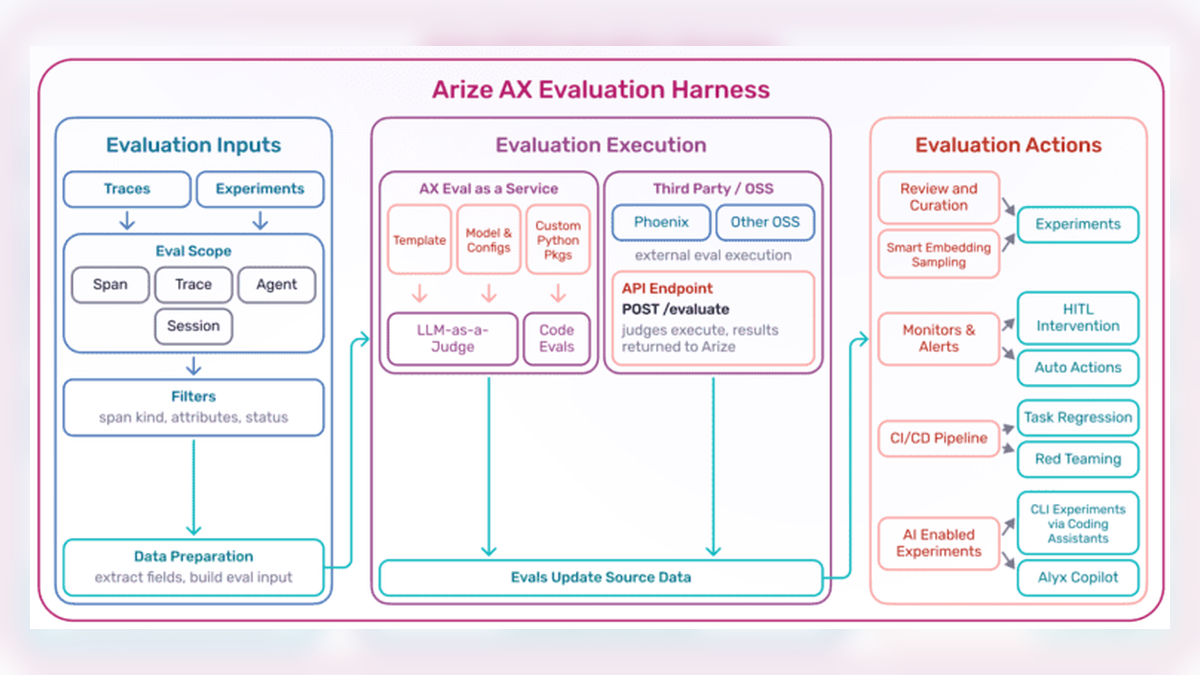
Stage 1: Define evaluation inputs
Inputs define the scope of what’s being evaluated. For agent and LLM systems, that scope is rarely a static benchmark row. More often, inputs come from two sources: traces or experiments. Traces capture real production behavior, while experiments package curated datasets, production slices, or controlled scenarios designed to probe specific failure modes.
A real evaluation harness needs to operate at four levels of granularity:
- Spans. A single unit of work, such as one LLM call, retrieval, or tool invocation. Span-level evals answer: did this specific step succeed?
- Traces. The full chain of spans for a single user request. Trace-level evals answer: did the end-to-end workflow deliver the right outcome?
- Agent trajectories. The ordered path an agent took, including tool choices and handoffs. Trajectory evals answer: did the agent reason correctly on the way to its answer?
- Sessions. Multi-turn interactions between a user and the system. Session evals answer: did the system maintain coherence, context, and goal state over time?
An evaluation harness that can only score at the span level cannot evaluate agents. And a harness that only scores traces can’t help you debug which specific step broke. The input stage is where the harness decides which unit of work matters for a given question, pulls the right data (live traces, curated datasets, or experiment runs), and filters it so evaluators see clean, targeted context.
This is also where inputs get prepared. Reference answers, retrieved documents, tool schemas, expected trajectories. Whatever the evaluator needs to reason over a case, the input stage assembles.
Stage 2: Run evaluation methods
Execution is how scoring happens. A mature harness supports multiple methods because no single evaluation technique covers every failure mode.
- LLM-as-a-Judge. A strong model evaluates another model’s output against a rubric. This is useful for open-ended quality questions such as relevance, faithfulness, tone, and correctness. It can work without ground truth, but is most effective when the judge prompt is calibrated against human labels.
- Deterministic code checks. Code-based checks use functions, string matching, regex, schema validation, or structural assertions. They’re useful when the correct answer has a fixed shape.
- Embedding similarity. This method scores the semantic distance between an output and a reference. It’s useful for fuzzy equivalence checks where an exact match is too strict and LLM-as-Judge is overkill.
- Custom scoring functions. These cover anything else the team needs, such as calling an internal API, running a classifier, or comparing against a golden dataset. The harness executes the function, persists the score, and makes it available to downstream workflows.
The execution stage should be indifferent to where the evaluator code lives, whether that’s on the Arize AX platform, behind an API, in an open source package, or inside the user’s own infrastructure. What matters is that results land in a consistent format and location, so downstream stages can act on them the same way.
An evaluation harness should support evaluators beyond its own first-party scoring methods so teams can reuse the evaluators they already trust and avoid being locked into a single vendor’s evaluation model.
Stage 3: Act on evaluation results
This is where many evaluation workflows break down: they produce scores without connecting them to annotation, alerting, CI/CD, or experiments.
Running an evaluation produces a score, but the score only has value when it changes what happens next. Actions are what turn the observed layer into part of the development workflow.
The four most useful action patterns are:
- Annotation queues. Low-confidence evaluator outputs, ambiguous failures, and edge cases are routed to humans for labeling. Those labels feed back into evaluator calibration, regression datasets, and fine-tuning sets.
- Monitors and alerts. Thresholds on eval metrics fire alerts when quality or reliability metrics move outside expected ranges. This could include hallucination spikes, tool-call failures, retrieval relevance degradation, or other task-specific failures. Those alerts go to the tools teams already use, such as Slack, PagerDuty, and webhooks.
- CI/CD gates. Evaluations run against candidate prompt and model changes before anything ships. Regressions can block the deployment, so teams can catch quality drops before they hit production.
- AI-assisted experiment workflows. Evaluation results feed directly into experiment loops where an AI copilot (such as Arize Alyx, our AI engineering agent) or coding agent proposes, tests, and iterates on fixes until a target metric threshold is met.
When these four actions are wired into the workflow, the evaluation harness becomes part of the development and operations loop instead of a standalone measurement tool.
How an evaluation harness works
An evaluation harness is the connective tissue between three things your team probably already has:
- An instrumented application (usually via OpenTelemetry and OpenInference, the open standards for AI tracing)
- A set of evaluators you trust
- Downstream operational tooling (alerting, annotation, CI/CD, experiment workflows)
Without a harness, those three components are often connected through notebooks, Slack messages, and the one-off scripts maintained by individual engineers. An evaluation harness connects them into a single, continuous quality system.
What to look for in an evaluation harness
A harness worth adopting should:
- Accept inputs at span, trace, trajectory, and session granularity
- Support LLM-as-Judge, code-based, embedding, and custom evaluators
- Run evaluators written anywhere, not just first-party ones
- Persist results in a consistent data model
- Integrate with annotation, alerting, CI/CD, and experiment workflows out of the box
- Build on open tracing standards (OpenTelemetry, OpenInference) so instrumentation is portable
- Support both offline experiments and online (production) evaluation from the same primitives
If a tool handles only one or two of these requirements, it may still be useful. But it’s closer to a script wrapper than infrastructure for a production evaluation practice.
Why agents need evaluation harnesses
Agents are where the need for an evaluation harness becomes most obvious.. A standalone LLM evaluation can often focus on a single response. Agent evaluation has to account for the sequence of decisions that produced the final outcome. That sequence can include tool calls, handoffs, retrieval steps, and partial outputs.
Each step can succeed while the overall outcome fails. Each step can fail while the overall outcome succeeds.
That’s why trajectory evaluation, tool selection accuracy, agent handoff quality, and session coherence are first-class concerns for teams running agents in production. These concerns require more than benchmark-style evaluation. They require the full three-stage architecture: inputs scoped to the right level of granularity, execution methods flexible enough to score multi-step behavior, and actions that route failures to the right queue.
Agent evaluation is becoming more operational as teams move from offline checks to continuous regression testing and production monitoring.
Teams that treated evals as an afterthought in 2024 are now blocking every prompt and model change on a regression run. Teams that adopted the harness pattern early are now wiring up monitor-triggered autonomous agents that triage production failures without human intervention.
How Arize supports evaluation harness workflows
Arize is an evaluation and observability platform built around the harness pattern. The three-stage architecture described in this post is the reference architecture for how Arize AX, our enterprise platform, operates. Phoenix, our open-source project, also offers instrumentation, trace schemas, evaluator logic, and can be self hosted. Plus, anything you build on Phoenix carries forward when you graduate to AX.
We went deeper on the operational maturity curve (GUI evaluation, AI-assisted eval ops, programmatic workflows, monitor-triggered autonomous agents) in From First Eval to Autonomous AI Ops: A Maturity Model for AI Evaluation. This post is the definitional companion.
FAQ
What is an evaluation harness in AI? An evaluation harness is standardized infrastructure that defines what gets evaluated in an AI system, runs the scoring, and acts on the results. It is the architectural backbone of a production evaluation practice. The three stages are evaluation inputs, evaluation execution, and evaluation actions.
What is the difference between an evaluation harness and a benchmark? A benchmark is usually a standardized model evaluation: a dataset and scoring method used to compare a model in isolation, such as MMLU, HellaSwag, or HumanEval. An evaluation harness is the infrastructure for running evaluations against a model or application and routing the results somewhere useful.
In production AI, the more important problem is often task evaluation: how well a specific system performs a specific workflow with your prompts, tools, retrieval, user context, and constraints. A benchmark can tell you how capable a model is in general. A harness helps you evaluate whether your application is doing the job you actually need it to do.
Is lm-evaluation-harness the same as an evaluation harness? lm-evaluation-harness is a specific open-source framework from EleutherAI for running language models against academic benchmarks. It is an evaluation harness for pre-training research. It is not designed for evaluating agents, RAG systems, or production AI applications, which is what most teams building with LLMs today need.
Do I need an evaluation harness if I’m just running a few eval scripts? Only if you plan to keep doing that forever. An eval script answers a one-time question. A harness answers the same question continuously, every day, as your system, prompts, models, and user behavior change. The moment you ask “did our quality drop this week?” or “will this prompt change break anything?” you need a harness.
Can I build my own evaluation harness? Yes. The three-stage architecture is straightforward to describe and hard to execute well. Teams that build their own typically underestimate the action stage: annotation routing, alerting, CI/CD integration, and experiment workflows require real engineering investment. Teams also tend to underestimate the operational overhead: maintaining evaluation definitions, updating templates, onboarding new teams and use cases, and managing changes as systems evolve. Most teams are better served by adopting a harness built on open standards like OpenTelemetry and OpenInference so their instrumentation stays portable.
What does an evaluation harness evaluate? In modern systems, a harness evaluates at four levels: individual spans (one LLM call or tool call), full traces (one user request end to end), agent trajectories (the path an agent took), and sessions (multi-turn interactions over time). The right level depends on the question you are asking.
How does an evaluation harness integrate with CI/CD? The harness exposes evaluation as a first-class step in the build pipeline. Candidate prompt and model changes run through a regression dataset, scored by the same evaluators used in production. Failures block the merge. This is the single most effective pattern for preventing silent quality regressions.
Ready to see the harness in practice? Start with Phoenix for open-source evaluation and tracing, or request a demo of Arize AX to see the full production evaluation harness in action.