From human review to automated evaluation
Once you understand your failure modes through human review, the next step is automating those checks. Evaluators let you measure quality at scale, turning subjective judgments into measurable results so you can track improvements over time and catch regressions early. Once you create an evaluator, you run it over your data using a task. Task setup is covered on the next page.
Evaluator detail
What is an evaluator
An evaluator looks at your data and returns a structured result, including some combination of label (e.g. correct / incorrect), a numeric score, and an explanation. Evaluators are versioned so every change is tracked. When you create an evaluator you also set its scope (span, trace, session, or experiment), which determines what unit of data it sees and where results appear.
How an LLM evaluator scores your data
`{query}`, `{reference}`, and `{output}`, which are mapped to your data at runtime. After running, the evaluator returns a structured output: a numeric score, a label (for example Correct), and an explanation.
LLM evaluators also have an optimization direction. Maximize when higher scores are better, minimize when lower scores are better. This tells Arize how to color results so you can see at a glance what is performing well and what needs attention.

How a code eval scores your data
evaluate method. The dataset_row input is a dictionary of span attributes—common keys include attributes.output.value, attributes.input.value, and attributes.llm.token_count.total. Use .get() to handle missing keys gracefully. The evaluator returns a structured output with a score, label (for example pass), and an explanation.
What kind of eval do I need?
Start with what you learned in error analysis. For each failure mode, ask: is this subjective or deterministic? Subjective or nuanced criteria: use an LLM-as-a-judge evaluator for high-volume checks with stable column mappings, or Agent as a Judge when the agent should read trace context at run time without upfront mappings. Examples: helpfulness, tone, correctness, agent trajectory quality. Objective and rule-based criteria: use a code evaluator. Examples: JSON validation, regex matching, keyword presence. You already own the scoring logic: use a remote evaluator. You keep models and governance on your infrastructure; Arize owns orchestration, retries, and writing results back. Also use remote when your scoring needs packages or runtimes that code evals don’t support. Most applications mix evaluator types. You can attach multiple eval tasks to the same project for layered coverage.Scope
When you create an evaluator, you define its scope, which tells the evaluator what unit of data to look at and where results appear.LLM-as-a-Judge
Use an LLM to assess outputs based on a prompt and criteria you define. You can create one from wherever you are in your workflow:- Evaluator Hub: Create and manage evaluators to reuse across any project or experiment.
- Tracing: Create an eval directly from a trace, span, or session when you spot something worth measuring.
- Datasets and experiments: Set up an eval to score experiment runs against your golden dataset.
- Prompt Playground: Test and iterate on your eval or run an eval on your prompt experiments.

Evaluator Hub lists saved LLM judges and their configuration
Setup Instructions
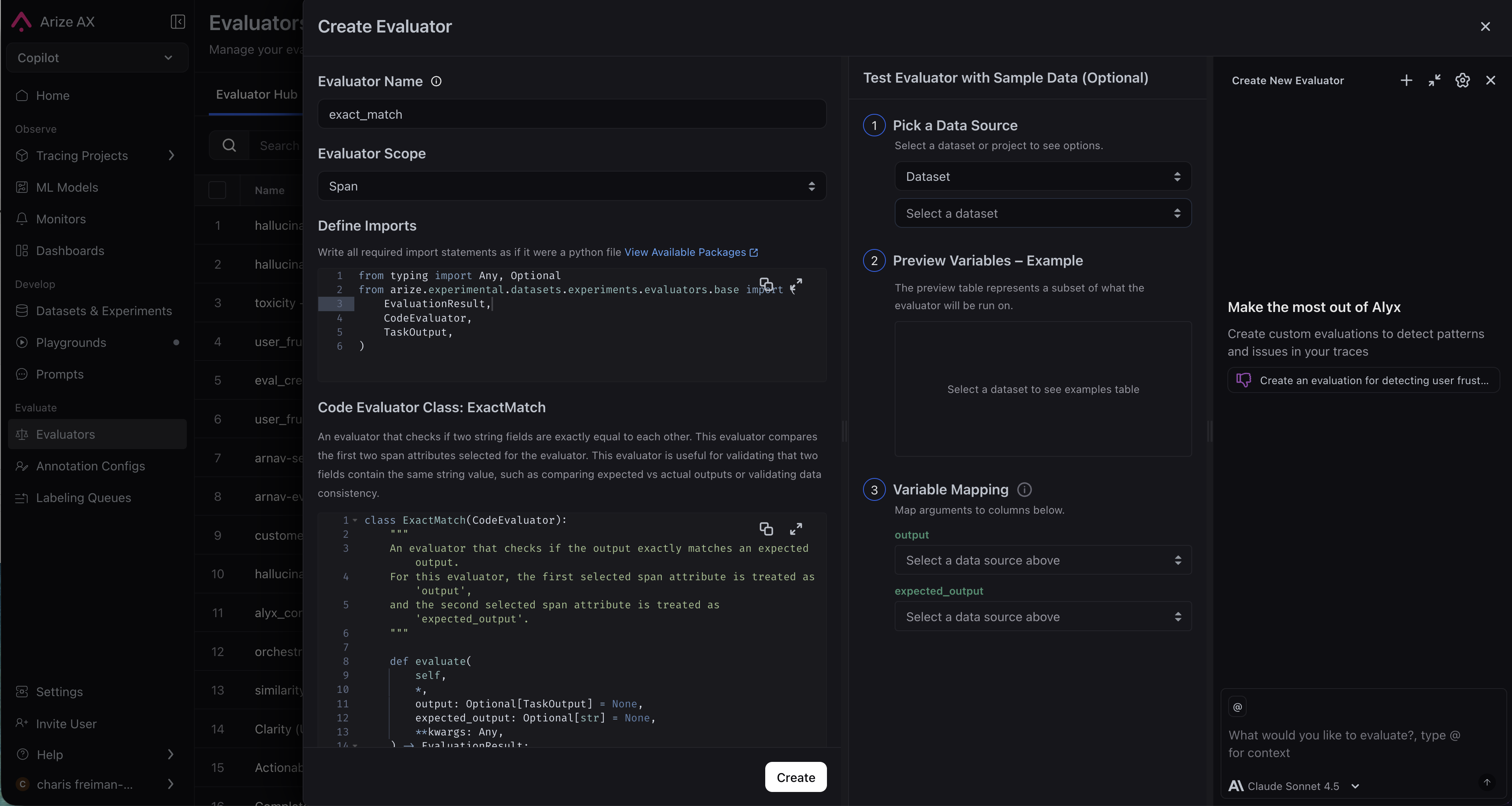
Set up an AI provider integration, write your eval template, map variables to your data, and save to the Evaluator Hub. For when to use span, trace, or session scope, see Scope above. You can create an LLM as a judge directly via the UI; you can also get Alyx or Arize Skills to do it for you.- By Arize Skills
- By Alyx
- By UI
Use the Arize skills plugin in your coding agent and the arize-evaluator skill to create evaluators via the 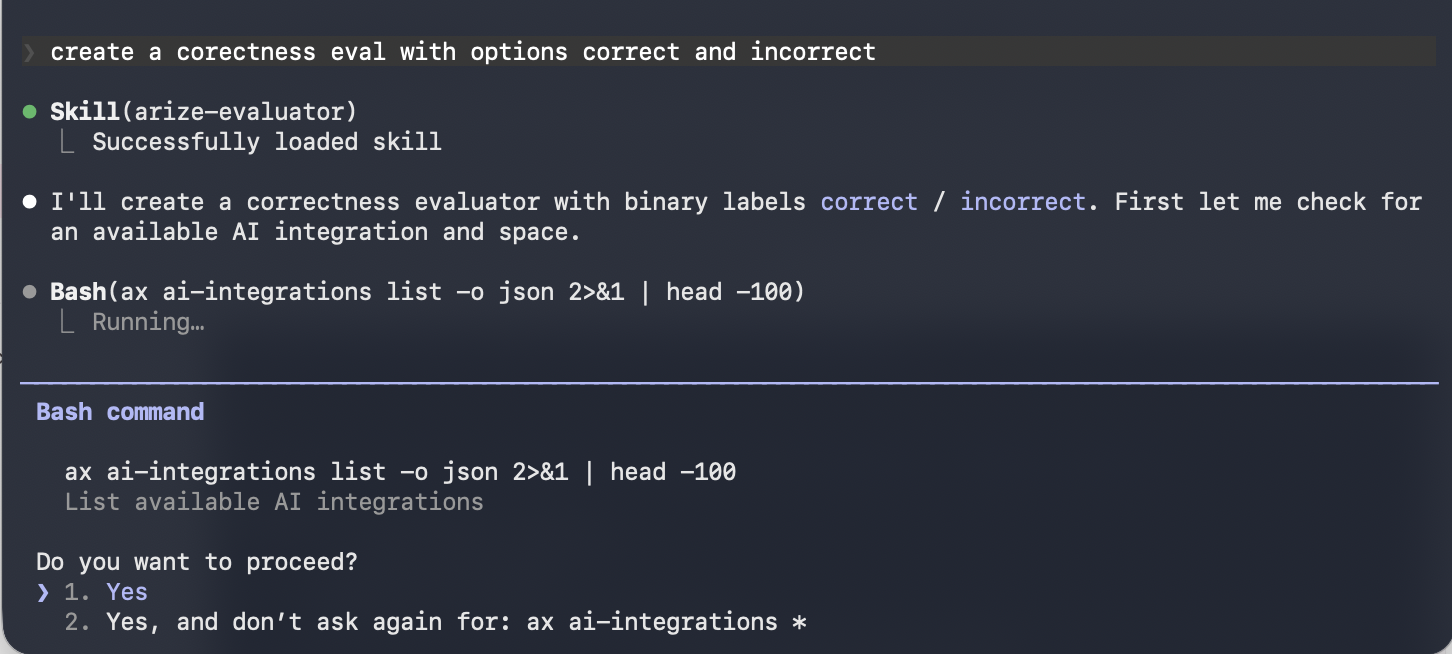

ax CLI without leaving your editor. See the skill doc for supported commands. Then ask your agent:- “Create a hallucination evaluator for my project”
- “Create an evaluator from blank with correct/incorrect labels”
- “Update the prompt on my correctness evaluator”





Code evaluators
Code evaluators run deterministic Python logic against your trace data. Faster, cheaper, and more consistent than LLM evals for objective checks.- By Arize Skills
- By Alyx
- By UI
- By Code
Use the Arize skills plugin in your coding agent and the arize-evaluator skill to create code evaluators and tasks via the
ax CLI without leaving your editor. See the skill doc for supported commands. Then ask your agent:- “Create a code evaluator that checks if the output is valid JSON”
- “Set up a regex evaluator that checks for a phone number in the response”