
Trace the Exponential
The open-source platform for agent development and evaluation
AI Engineers & Fortune 500 alike
Talk with your traces
Investigate issues, add annotations, run experiments, and more.
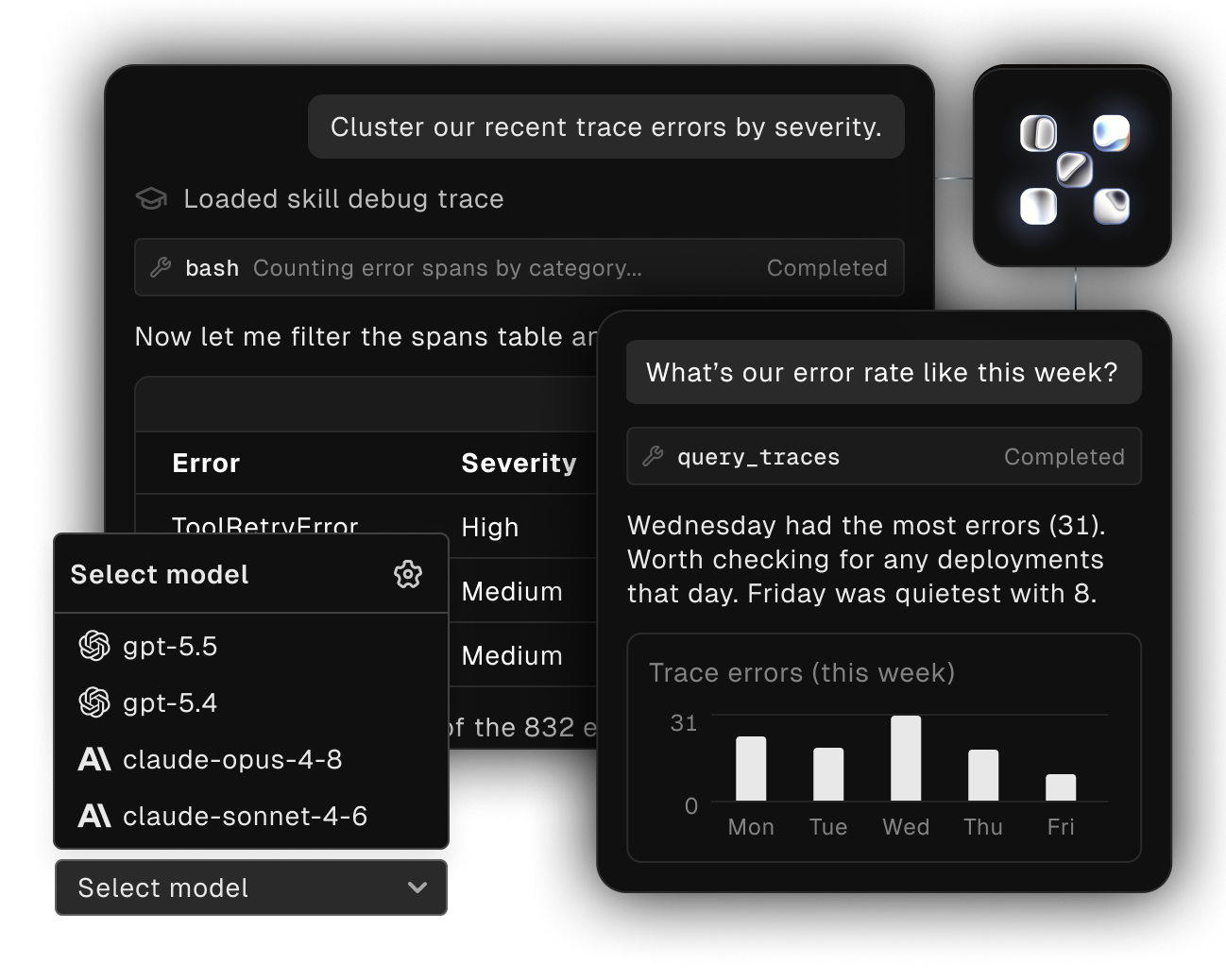
Get visibility into your agents
Without tracing, you’re flying blind. Phoenix shows every step your agent takes so you know what went wrong.
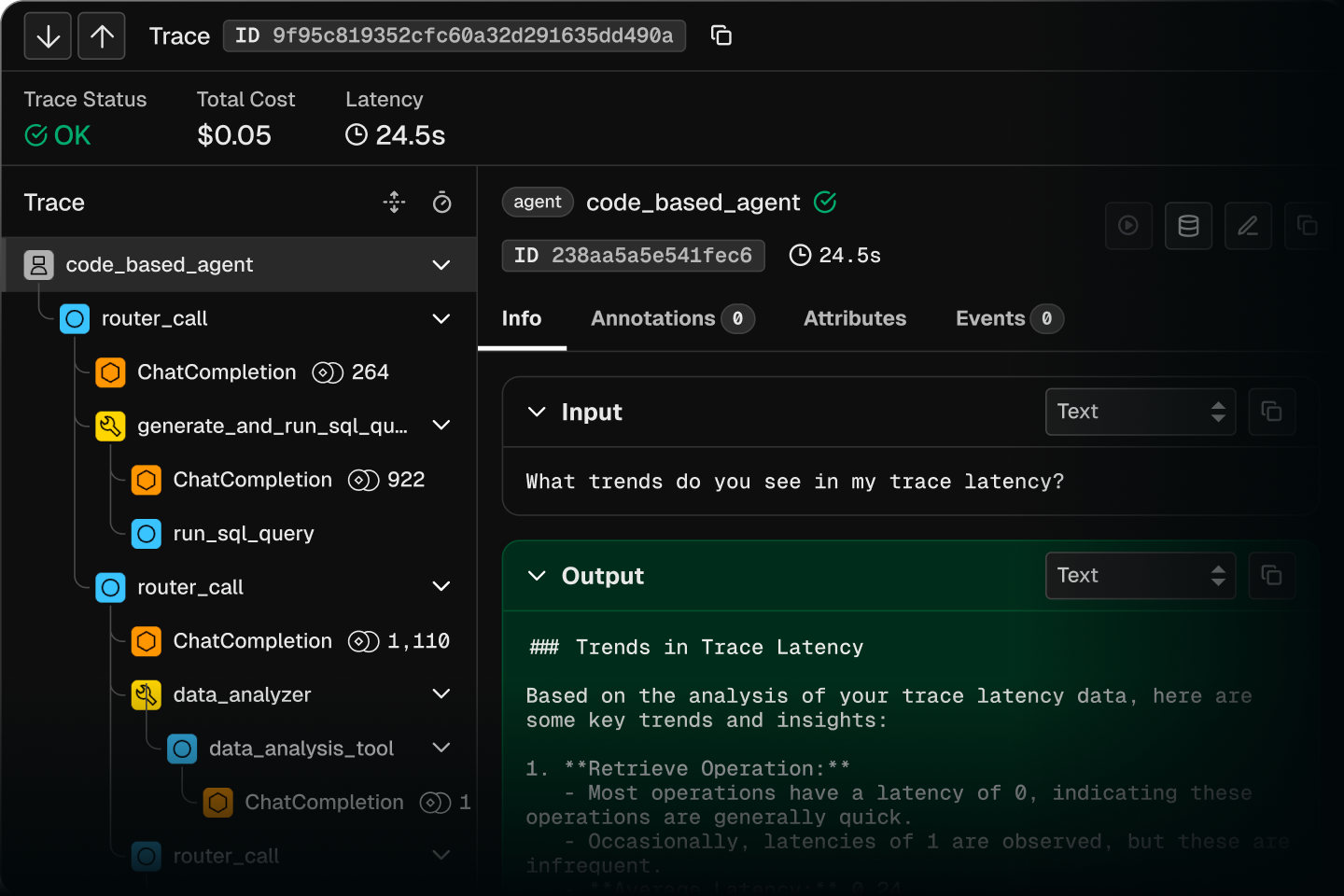
Measure and improve agent quality
Build evals that score outputs and catch issues before they reach your users.
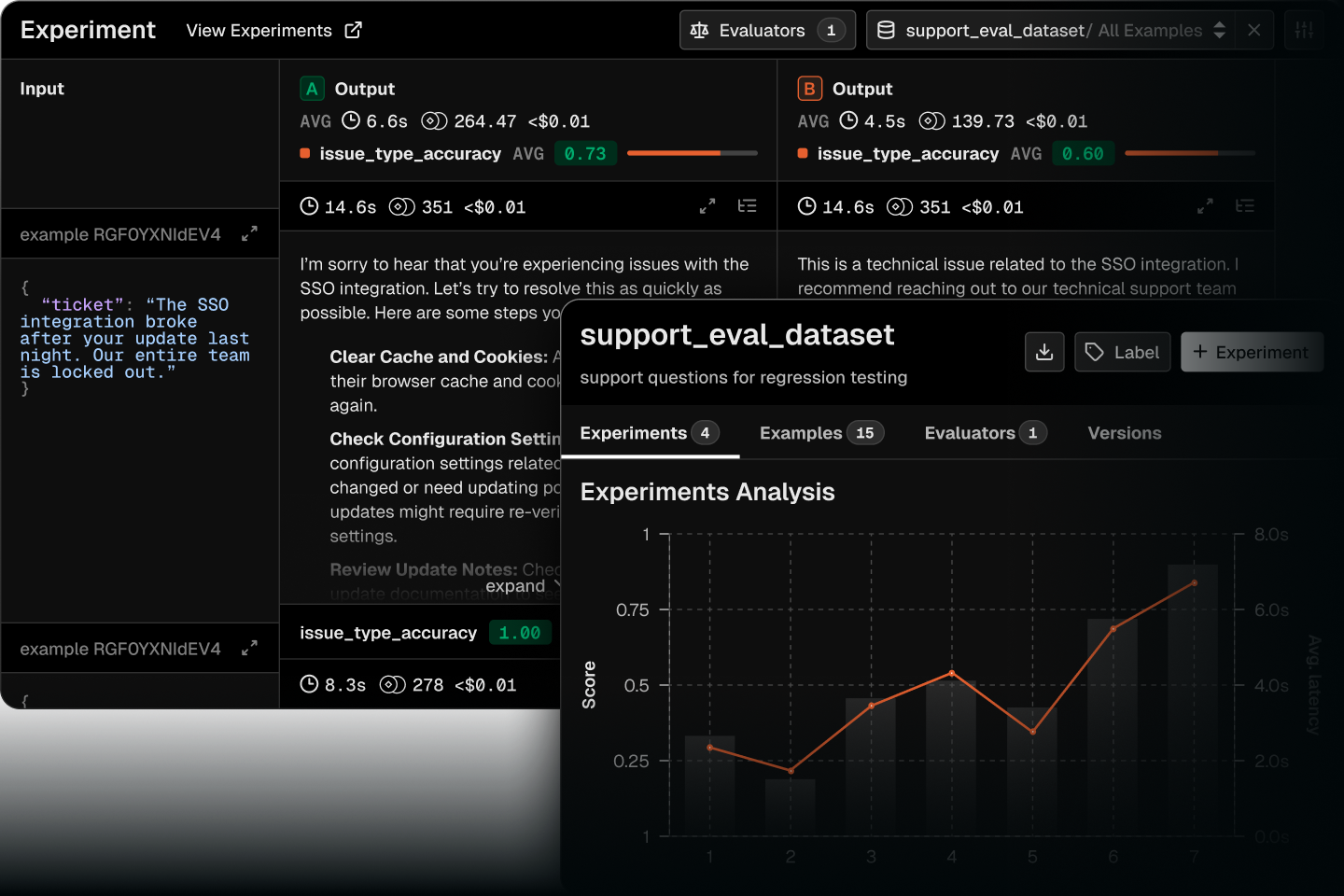
Test changes with evidence
Create datasets from traces, run experiments, and ship improvements.
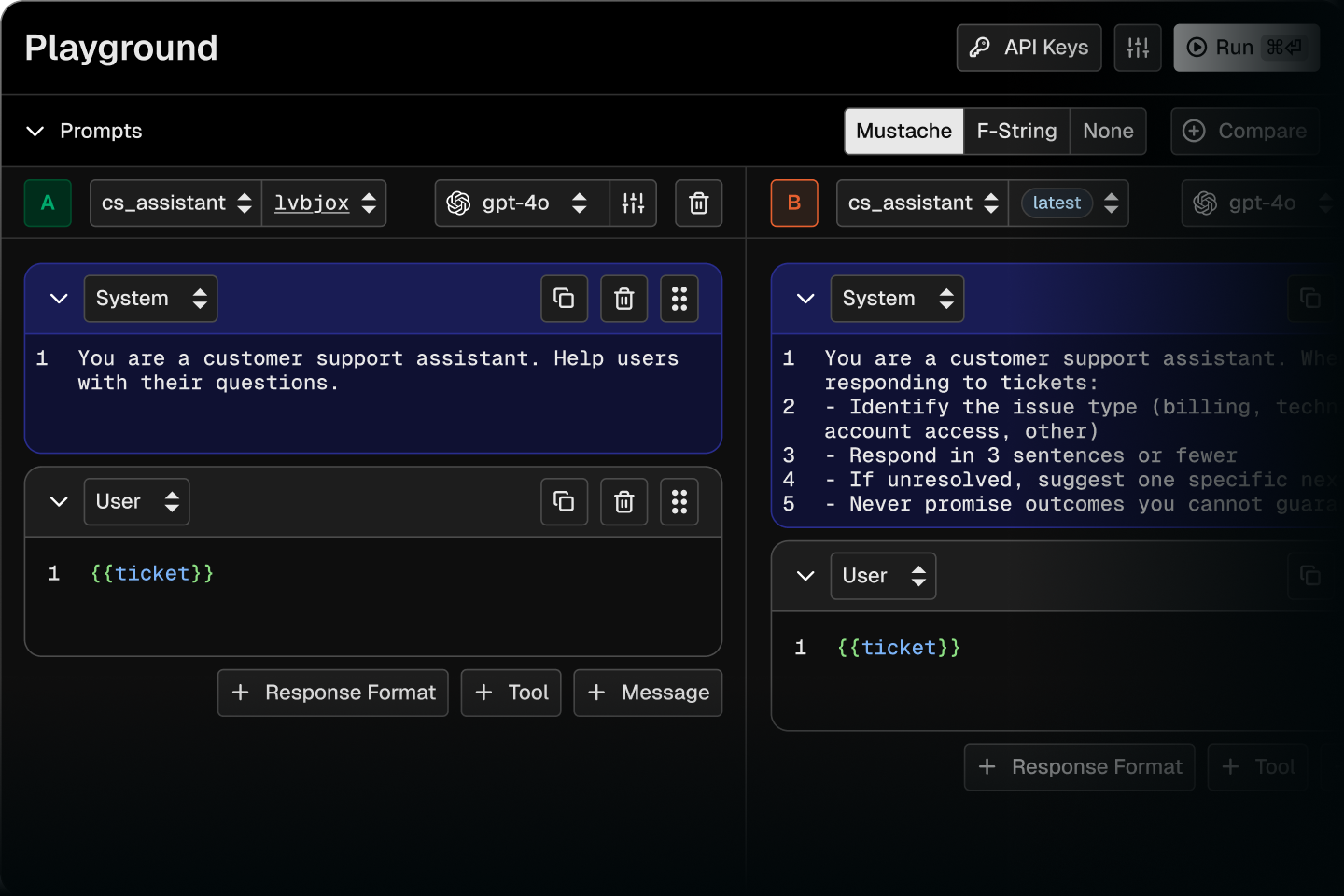
Agent Native
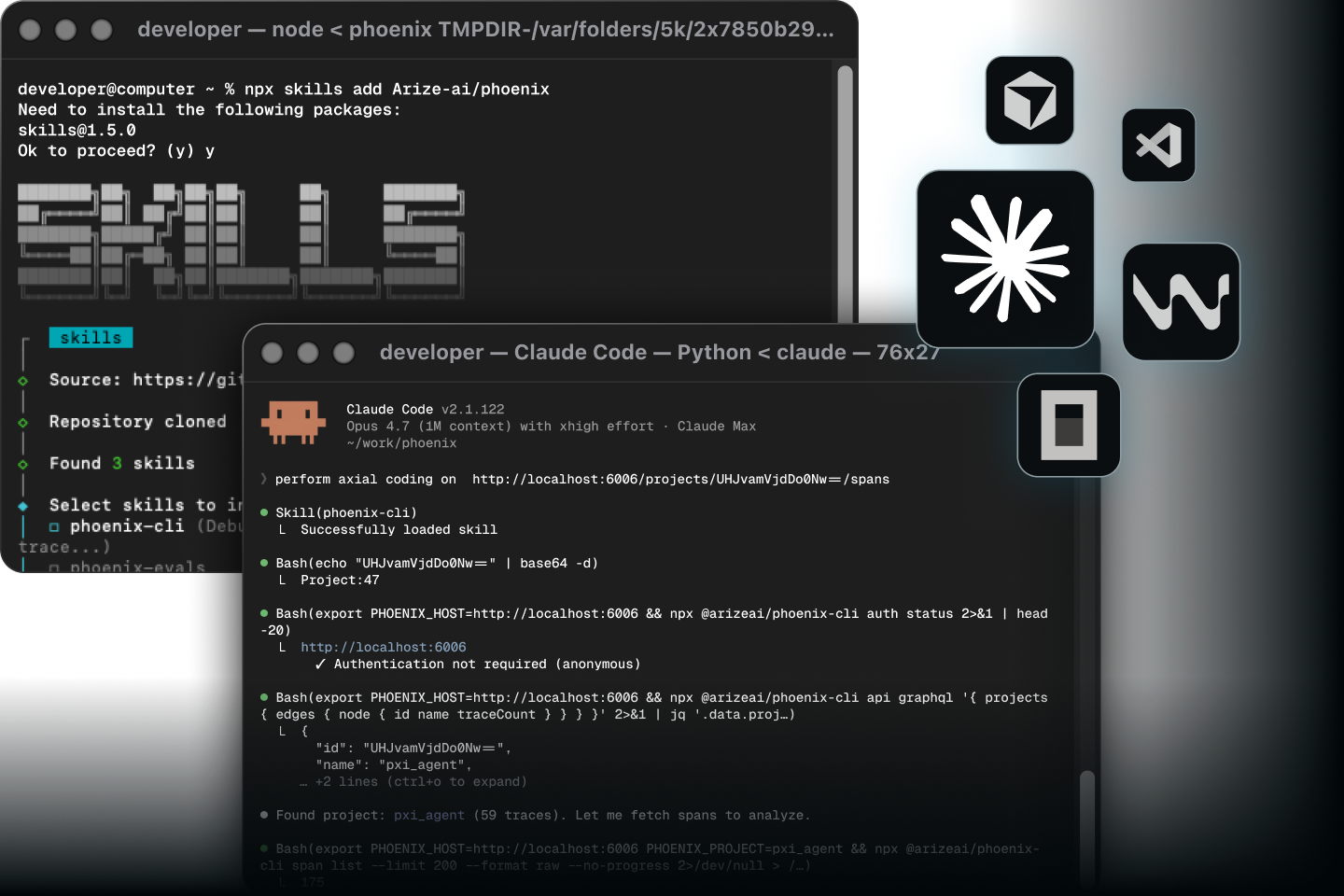
npx skills add Arize-ai/phoenix
Build automations using coding agents so you can focus on the things that matter.
A systematic way to improve AI quality
OBSERVE
1Why did my agent respond like that? Trace every step: prompts, retrievals, tool calls, outputs.
ANNOTATE
2Mark what worked. Flag what broke. Add labels with human review or LLM-as-judge.
HYPOTHESIZE
3Find the pattern. Is it the prompt? The retrieval? The model? Form a hypothesis about what to change.
EXPERIMENT
4Test your hypothesis. Make a change, run it under the same conditions, and benchmark performance.
MEASURE
5Score output across cost, latency, and performance. Ship only what improves quality.
Ask Another Question
Why did my agent respond like that? Trace every step: prompts, retrievals, tool calls, outputs.
Built by Engineers for builders like you.
Own your AI Stack

Privacy
Privacy
Your traces stay in your environment. Self-host Phoenix and keep sensitive data on your own infrastructure.

OSS Community
OSS Community
ELv2 licensed. 9k+ GitHub stars. Built in the open with contributions from teams building production agents.

Built on Standards
Built on Standards
Native OpenTelemetry support. Your traces work with the tools you already use. No proprietary lock-in.

Vendor Agnostic
Vendor Agnostic
Phoenix works with any model, framework, or language. No lock-in.
Deploy Anywhere in seconds



Kubernetes
Kubernetes
Deploy Phoenix with Helm. Manage, upgrade, and scale your Phoenix instance on Kubernetes.

Cloud
Cloud
Get 2 Phoenix Cloud instances for free. Start building with no infrastructure setup required.
Trusted by Builders
Join thousands of developers who ship AI with confidence.
3M+
Downloads Monthly
10k+
Github Stars
7k+
Community
22M+
OTEL Instrumentation Monthly Downloads

We are in an exciting time for AI technology including LLMs. We will need better tools to understand and monitor an LLM’s decision making. With Phoenix, Arize is offering an open source way to do exactly just that in a nifty library.

Erick Siavichay
Project Mentor, Inspirit AI

I always get asked what my favorite Open Source eval tool is. The most impressive one thus far to me is Phoenix.

Hamel Husain
Founder, Parlance Labs

As LLM-powered applications increase in sophistication and new use cases emerge, deeper capabilities around LLM observability are needed to help debug and troubleshoot. We’re pleased to see this open-source solution from Arize, along with a one-click integration to LlamaIndex, and recommend any AI engineers or developers building with LlamaIndex check it out.

Jerry Liu
CEO and Co-Founder, LlamaIndex
This is something that I was wanting to build at some point in the future, so I’m really happy to not have to build it. This is amazing.

Tom Matthews
Machine Learning Engineer at Unitary.ai
Arize’s Phoenix tool uses one LLM to evaluate another for relevance, toxicity, and quality of responses. The tool uses ‘Traces’ to record the paths taken by LLM requests (made by an application or end user) as they propagate through multiple steps. An accompanying OpenInference specification uses telemetry data to understand the execution of LLMs and the surrounding application context. In short, it’s possible to figure out where an LLM workflow broke or troubleshoot problems related to retrieval and tool execution.

Lucas Mearian
Senior Reporter, ComputerWorld
Large language models…remain susceptible to hallucination — in other words, producing false or misleading results. Phoenix, announced today at Arize AI’s Observe 2023 summit, targets this exact problem by visualizing complex LLM decision-making and flagging when and where models fail, go wrong, give poor responses or incorrectly generalize.

Shubham Sharma
VentureBeat

Phoenix is a much-appreciated advancement in model observability and production. The integration of observability utilities directly into the development process not only saves time but encourages model development and production teams to actively think about model use and ongoing improvements before releasing to production. This is a big win for management of the model lifecycle.

Christopher Brown
CEO and Co-Founder of Decision Patterns and a former UC Berkeley Computer Science lecturer
Phoenix integrated into our team’s existing data science workflows and enabled the exploration of unstructured text data to identify root causes of unexpected user inputs, problematic LLM responses, and gaps in our knowledge base.

Yuki Waka
Application Developer, Klick
Get started in Seconds
Agent Mastery
Learn to build, debug, and evaluate AI agents

Docs
Quickstarts, API reference, and integration guides






Stay in the Loop with Phoenix
Get Phoenix updates, releases, and AI engineering
insights delivered to your inbox.