



At AI Engineer: Miami I was watching a talk by Dexter Horthy in which he mentioned as an aside that research showed that models have trouble following more than 150-200 instructions at once. That struck me as a really interesting fact, so I tracked down where he got that from: the IFScale benchmark from Jaroslawicz et al. (2025). That paper is nearly a year old, so I wondered how much better models have become since then. The answer is: a whole lot better, in fact, an order of magnitude better.
Let’s not beat around the bush though. Here’s the data:
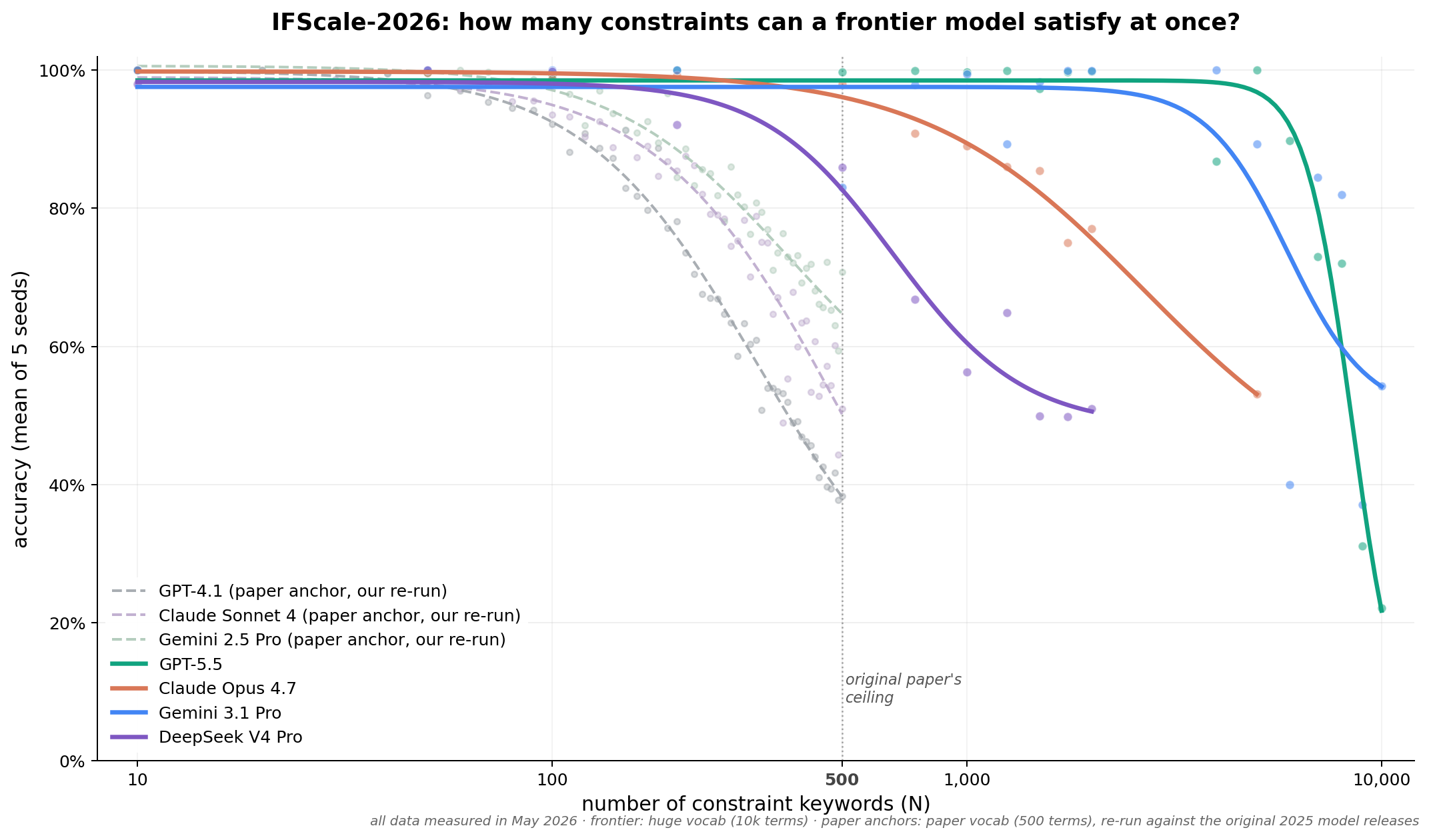
A quick TL;DR of this chart:
- The Y-axis is accuracy: given a whole bunch of rules to follow, what percentage of them does the model actually follow?
- The X-axis, which is log scale, is how many rules the model is trying to follow at once.
- The faint dotted lines are three older models that were available when the original paper was written and are still available today. You can see that past 100 rules, they begin to ignore some of the instructions they’re given. By 500 rules, they’re beginning to drop as many as half of them.
- The bold lines are some current frontier models. You can see they get much further before they start dropping instructions. GPT 5.5 does the best while DeepSeek V4 Pro does the worst.
So that’s our headline finding: a year ago, frontier models started losing track of instructions at somewhere around 200-300 simultaneous constraints. Depending on what model you pick, that boundary is now closer to 2,000 instructions.
Put simply, frontier models have gotten close to 10X better at following instructions in the last 12 months, and this has a lot of implications for real-world AI engineering, including:
- Skills files no longer have a compression problem
- Prompts can be extremely detailed
- A hard boundary of capability has become a soft tradeoff of cost-versus-capability
We’ll explain in full, but there’s a lot of nuance here, so we invite you to read on.
The original IFScale benchmark
Our work is based on the benchmark paper Jaroslawicz et al. (2025). The test is pretty simple: ask a model to write a business report that contains N specific keywords (chosen from a vocabulary of 500 ordinary English words like “customer”, “revenue”, “logistics”), then count how many keywords showed up correctly in the output.
The prompt itself is short:
You are tasked with writing a professional business report that adheres strictly to a set of constraints. Each constraint requires that you include the exact, literal word specified… The report should be structured like a professional business document with clear sections and relevant business insights. Do not simply repeat the constraints; rather, use them to inform the text of the report.
CONSTRAINTS
- Include the exact word: ‘customer’.
- Include the exact word: ‘revenue’. …
We test this output the same way the original paper did: with a simple regex-based exact-match. Plurals don’t count. Hyphenations don’t count. “Customer” satisfies “customer”; “customers” does not. We call the number of keywords density or N, and the percentage of them that show up in the output is accuracy.
We believe, as the original authors did, that this is a good proxy for the more general question of “how many instructions can a model follow at once?” The keywords are arbitrary, but they represent the kind of discrete, named constraints that show up in real-world skills files: “if the user says X, do Y”, “include a section on Z”, “don’t use the phrase W”. If a model can’t track 200 discrete items in a single prompt, that’s a problem for any skill spec with more than 200 items in it.
The original paper’s results are still true
Before extending the benchmark, we figured we should try replicating the original finding. So we re-ran it on three models from the original paper that are still available a year later: GPT-4.1, Claude Sonnet 4 (May 2025 release), and Gemini 2.5 Pro.
Fun fact: it turns out May 2026 is the last month these models will be available! They all get retired in June, so we got lucky that there was still something to compare.
We copied the original paper’s prompt and the vocabulary of 500 words it used to test, and ran it from N=10 to N=500, 5 tries each, averaged. This worked: our accuracy curves matched the shapes the original paper reported, with deltas under 3 percentage points at low densities and growing to about 10 points at N=500 which was well within the noise of a five-seed test.
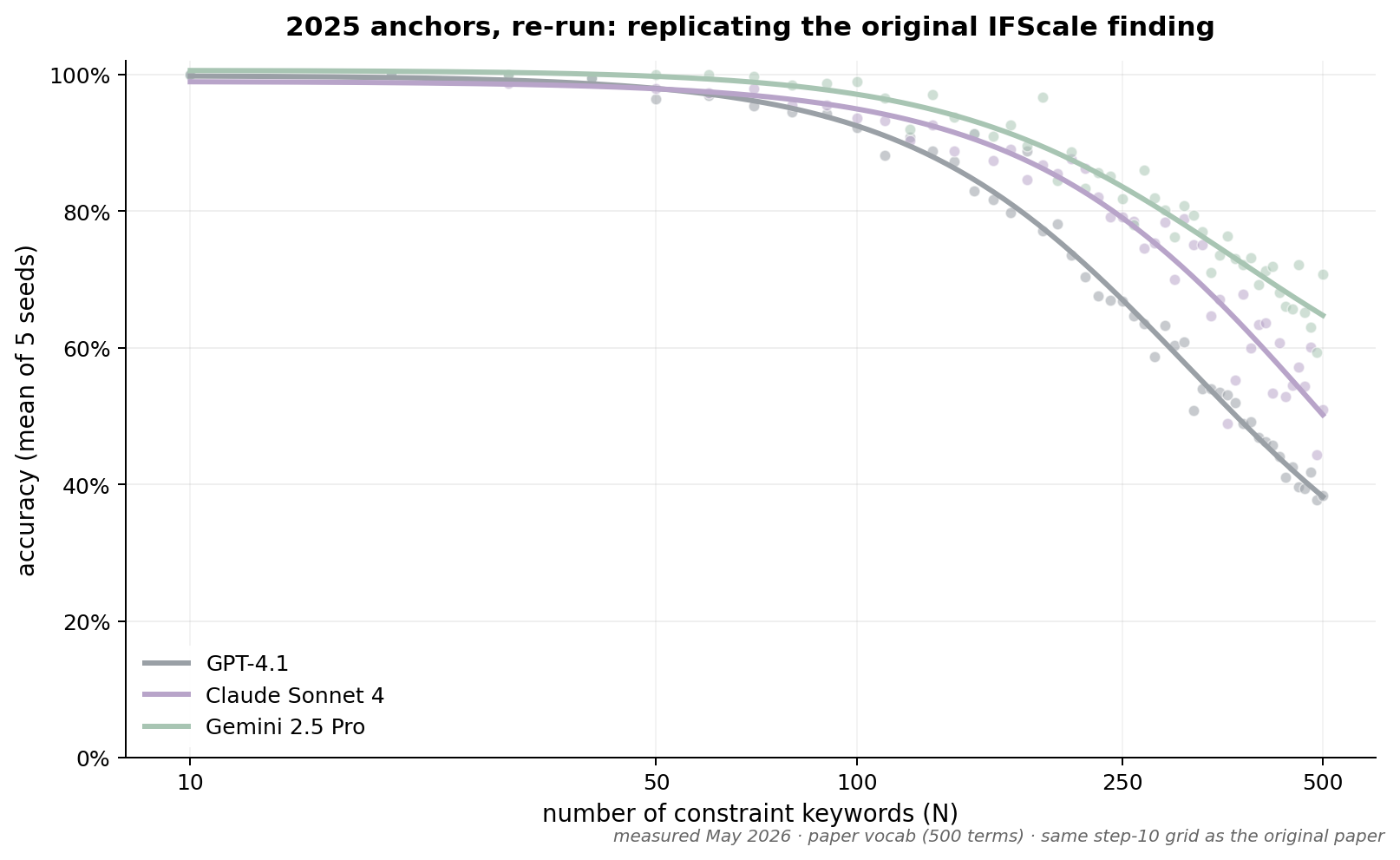
Moving the goalposts
Our initial plan was to simply try newer models on exactly the same data: same prompt, same vocabulary, same N range. But we quickly ran into a problem: the new models were doing so well that they were hitting 100% accuracy at N=500. The original paper’s ceiling was 500 constraints because that’s where the models of the day started dropping instructions; but current models are still perfect at 500 words!
So we had to make things harder: more words to include, out of a larger vocabulary. This took a number of attempts because we couldn’t find the ceiling. We doubled the number of instructions to follow, then doubled it again. Eventually we landed on a 10,000-word vocabulary before we started seeing meaningful degradation. Frontier models are a lot better!
Frontier models fail in different ways
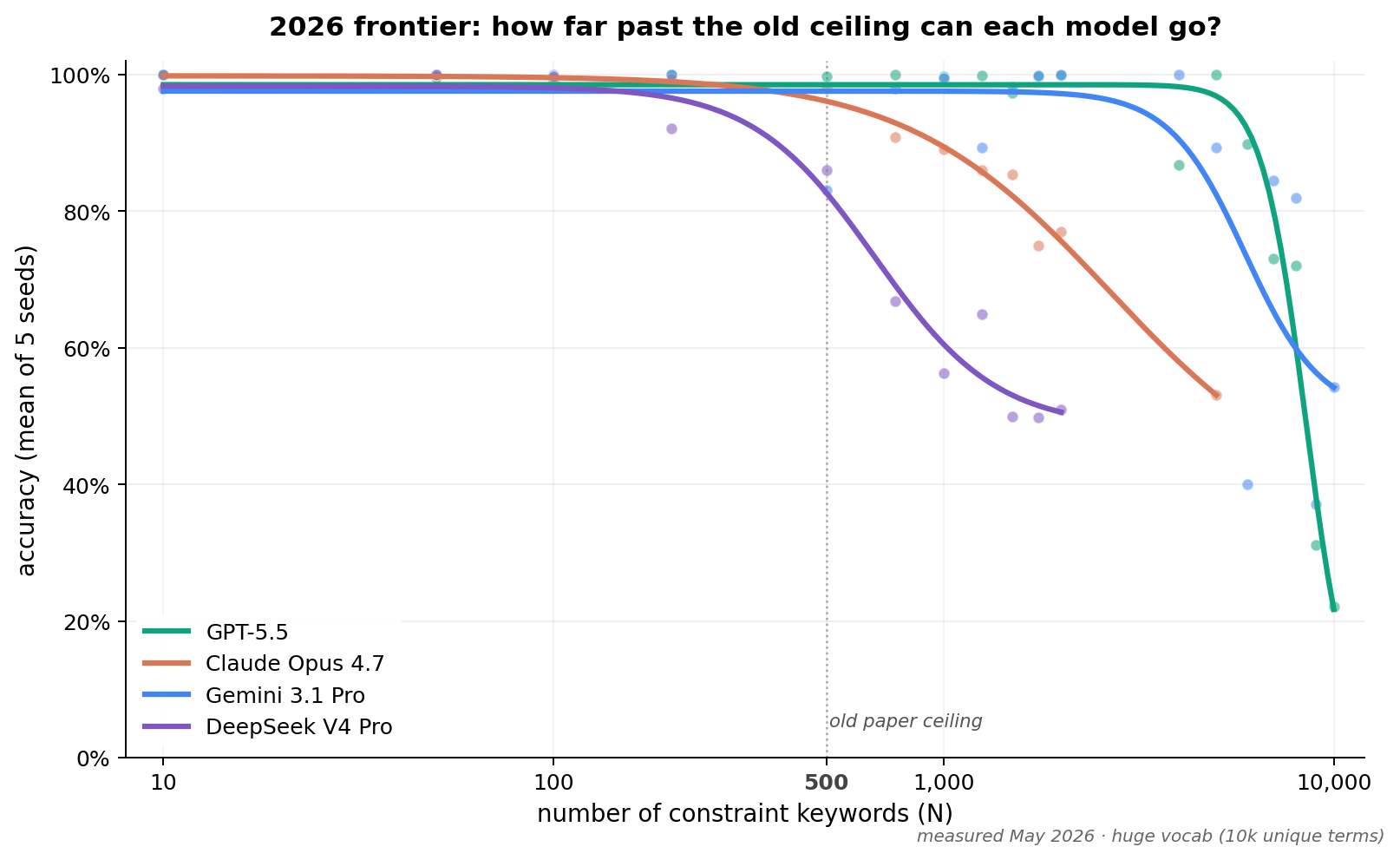
You’ve already seen the new data: the frontier models do way better. But how they do better is fascinating. They mostly don’t show the same kind of failure mode of merely “ignoring instructions”. Instead they have different problems when the number of rules gets really high.
DeepSeek V4 Pro is the closest to the original pattern: it starts dropping instructions around N=750, and by N=2,000 it’s ignoring nearly half of them.
Claude Opus 4.7 thinks the test is dangerous: In the chart, you can see that Claude does quite a lot better than DeepSeek, but the chart hides the curious behavior we observed: instead of merely forgetting instructions, Claude would outright refuse to answer, returning an API-level “refusal” error.
As far as we can tell, this is the unexpected effect of an Anthropic safety feature. Opus has a very sensitive “refusal classifier”: if you include certain combinations of words (like “anthrax” and “cyanide”) in the prompt, it will refuse to answer at all. The more words we included, even deliberately innocuous ones, the more likely we were to hit a combination of words that added up to “danger” as far as Claude is concerned.
We ended up having to run the entire vocabulary through OpenAI’s moderation API to remove “danger” words before we could get Opus to stop refusing, and even then we had to retry a lot. But the curve is still real: when it didn’t refuse outright, Opus was still beginning to forget some of the instructions it was given. By N=5,000, it was only following about half of them. But remember, the old ceiling was 200! This was still an order of magnitude improvement at least.
Gemini 3.1 Pro is rock-solid until it starts overthinking: Gemini’s data has a lot of noise in it because Gemini’s behavior is very unpredictable at high N. Up to N=5,000 it does incredibly well. Past that, it begins to fail in a very strange way: instead of forgetting instructions, it just spends its entire output budget on internal reasoning tokens and emits little or no visible report at all. It’s as if the model is trying so hard to follow the instructions that it runs out of “thinking space” and produces no answer at all.
GPT 5.5 thinks this test is stupid: GPT 5.5 does the best of all the models we tried, holding 99% accuracy through N=5,000 (with one stochastic dip at N=4,000 that you can see in the chart). Past that, it falls off. And at very high N, instead of merely dropping instructions, we began to get refusals. Instead of API-level refusals like Opus, GPT 5.5 would occasionally respond with a polite output message like this one:
I’m sorry, but the requested report cannot be produced in full within the practical response limits of this interface because it requires incorporating 4,000 exact terms while also maintaining a coherent professional business-report structure.
It would start generating the report, get frustrated, and then stop with a message like the above. In fairness to GPT 5.5, it’s sort of true! Asking for a coherent business report without specifying what the report’s about except that it should contain 5,000 specific words is a pretty unreasonable request, and GPT called us out on it. But it still counts as failure; the half-finished reports it produced would have a fraction of the required keywords.
What this means for real-world AI engineering
The capacity to track 2,000 (and up to 5,000!) simultaneous named constraints in a single prompt is now real on GPT 5.5 and Gemini 3.1 Pro. A year ago, all the frontier models would have failed at a fraction of that. This has some pretty big implications for how we build skills and agents:
- Skills files have less of a compression problem. If you were relying on data from a year ago, you’d be writing skills files that were pretty short (200 instructions or fewer), and then pointing to sub-skills or subagents. This is much less necessary now. You can include really long, detailed instructions in a single file and have confidence that the model will follow them.
- Prompts can be extremely detailed. If you have a use case that requires a lot of discrete constraints, you can now include them all in the prompt without worrying about the model losing track of them. This opens up new possibilities for complex tasks that require a lot of specific instructions. Anecdotally, a lot of people have been discovering this already.
- The trade-off has shifted from “can the model do it?” to “is the cost worth it?” A prompt or a skill with 2,000 instructions in it is probably going to work. It’s also going to be really long! That will make it more expensive from a token perspective and slower to run. So you still have to think about length, but it’s a much softer ceiling than it was.
Some caveats
We intend to turn our findings into a real, formal paper with a full methodology breakdown and a more rigorous analysis of the failure modes. In the meantime, here are some important caveats to keep in mind about this data:
- IFScale measures named-item inclusion. The capacity result is evidence that long skills files are viable, not proof that every kind of instruction in them is followed. We are using a proxy task that we think generalizes to all instructions, but proof is a higher bar than evidence.
- Different models hit the wall at very different N. The chart shows inflection points spanning roughly N=750 to N=9,000+. Pick your model carefully, and if it’s Claude remember to look out for danger words.
- Not every failure is at the API level. Claude’s API-level refusals are annoying, but GPT’s half-finished reports with polite refusals are more frustrating: you have to read the entire output to know if it was really paying attention or if it gave up.
What it cost
We instrumented every run with Arize AX from day one. It gave us a fast way to filter traces for various failure modes, and at the end we asked AX a question we couldn’t have answered any other way: what did this whole experiment cost?
| Model | Calls | Cost (USD) |
|---|---|---|
| claude-opus-4-7 | 1,326 | $121.82 |
| gpt-5.5-2026-04-23 | 92 | $37.51 |
| gemini-3.1-pro-preview | 120 | $23.64 |
| claude-sonnet-4-20250514 | 250 | $15.45 |
| gemini-2.5-pro | 251 | $6.10 |
| gpt-4.1-2025-04-14 | 250 | $3.46 |
| deepseek-v4-pro | 56 | $1.22 |
| Total | 2,345 | $209.19 |
The answer is $209. Note that we spent far more on Claude than anything else because Claude was also running the LLM-as-a-judge that checked the output for coherence and flagged refusals. It also includes a lot of trial-and-error runs as we were tuning the vocabulary and trying to find the ceiling for each model.
What’s next
As mentioned, we’re hoping to submit this research as a formal paper, which will require extra work. But in the meantime, the conclusions are yours to act on, and all the code and data is open source and available for you to explore and build on.
A year ago, skills files were a compression problem. They aren’t anymore. Now they’re a verification problem. Plan accordingly.
If you’re building agents or skills against the 2026 frontier and want help thinking about how to evaluate them at scale, Arize AX is what we use.