
This week the field shipped four kinds of memory, and Apple paid Google a billion dollars a year for one of them. None of the four is what the demos imply.
In the last six weeks alone, the launches stacked up faster than anyone could read them. HydraDB raised $6.5M and shipped a memory layer with a 90.79% LongMemEval-S claim, Anthropic launched the first Dreams feature for its Managed Agents, OpenAI shipped Dreaming for ChatGPT, Apple unveiled Siri AI at WWDC, Cognition shipped Devin Auto-Triage, and the Letta team published a red-team study finding that models exhibit “deep self-identification with ephemerality that cannot be repaired with prompting alone.”
Most of this is framed as memory. Almost none of it is what readers mean by the word.
The taxonomy below is the way we read what’s actually shipping. Four buckets, each with a different architectural commitment, each solving a real but smaller-than-marketed problem. The bucket nobody is in is the unsolved one, and that bucket is where memory in the cognitive-science or product-manager sense of the term would actually live.
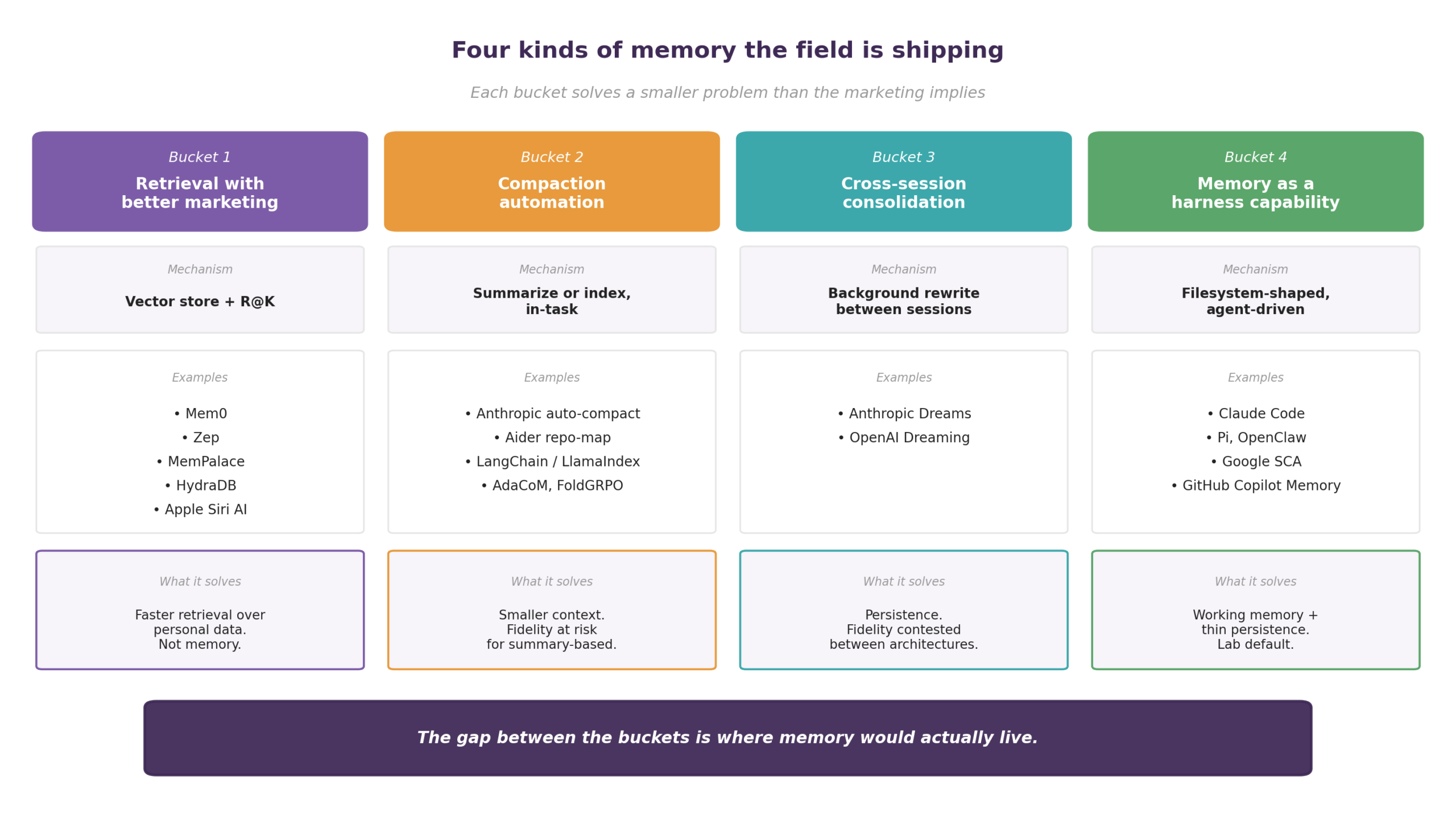
Bucket 1: Retrieval with better marketing
The largest bucket by product count, and the most consistent in mechanism across the cluster. You chunk the data, embed the chunks, store them in a vector database with an optional graph layer for entity relations, query with another embedding, and return the top-K. Sometimes there is an LLM extractor on the write side deciding what to remember, sometimes everything is stored verbatim and the rerank does the work, but the headline number is almost always retrieval recall — R@5 or R@10 — and the benchmark is almost always LongMemEval, LoCoMo, ConvoMem, or MemBench.
Mem0, Zep, Letta’s commercial product, MemPalace, and HydraDB all sit here despite the visible differences in their marketing.
HydraDB is the freshest example. Their headline claim is 90.79% on LongMemEval-S, which is a real number and also the same R@K-on-a-QA-benchmark pattern the MemPalace audit pulled apart in detail two months ago. LongMemEval’s official metric is end-to-end QA accuracy scored by an LLM judge, not retrieval recall, so R@K under those conditions tells you the retriever found the right document, not that the system answered the question. The MemPalace community spent six months learning this in public, and a vendor raised $6.5M this month presenting the same framing.
Apple is now the most prominent consumer-facing example of the pattern. The demos on stage at WWDC 2026 were textbook RAG over user data: “Show me the files Eric sent me last week,” “Find the email where Eric mentioned ice skating,” “Find the books that Eric recommended to me.” Apple VP Mike Rockwell described the feature with the verbs “find” and “get more done,” neither of which is a memory verb in any architectural sense. Apple describes the mechanism underneath as a system-wide semantic index over the user’s apps and data. The branding is personal context, the deployment is split between local Apple Intelligence for simple requests and Google’s Gemini in the cloud for complex ones, and the partnership reportedly costs Apple an estimated billion dollars a year.
What this bucket actually solves is faster retrieval over personal or organizational data with better-than-grep relevance ranking, which is useful and worth shipping. It is not what the marketing copy means by memory.
The gap between marketing and meaning matters more in this bucket than any of the others, because consumers carry a much richer intuition about memory than the architecture delivers. A non-technical user who hears that Siri now has memory expects something close to human memory: an assistant that knows them as a person, builds understanding over time, notices when facts have changed, connects what was said in one conversation to what was discussed in another, and remembers not just what they asked about but how they like things done. That intuition is closer to the cognitive-science decomposition into episodic, semantic, and procedural memory than it is to the demos. The demos show retrieval, framed as personal context. The gap between “find the file Eric sent” and “knows me” is the entire missing primitive.
Bucket 2: Compaction automation
The second bucket is in-task context management, which is the work of keeping the agent’s working context small without the developer hand-rolling truncation rules. Production implementations have proliferated over the last quarter, and the engineering is real.
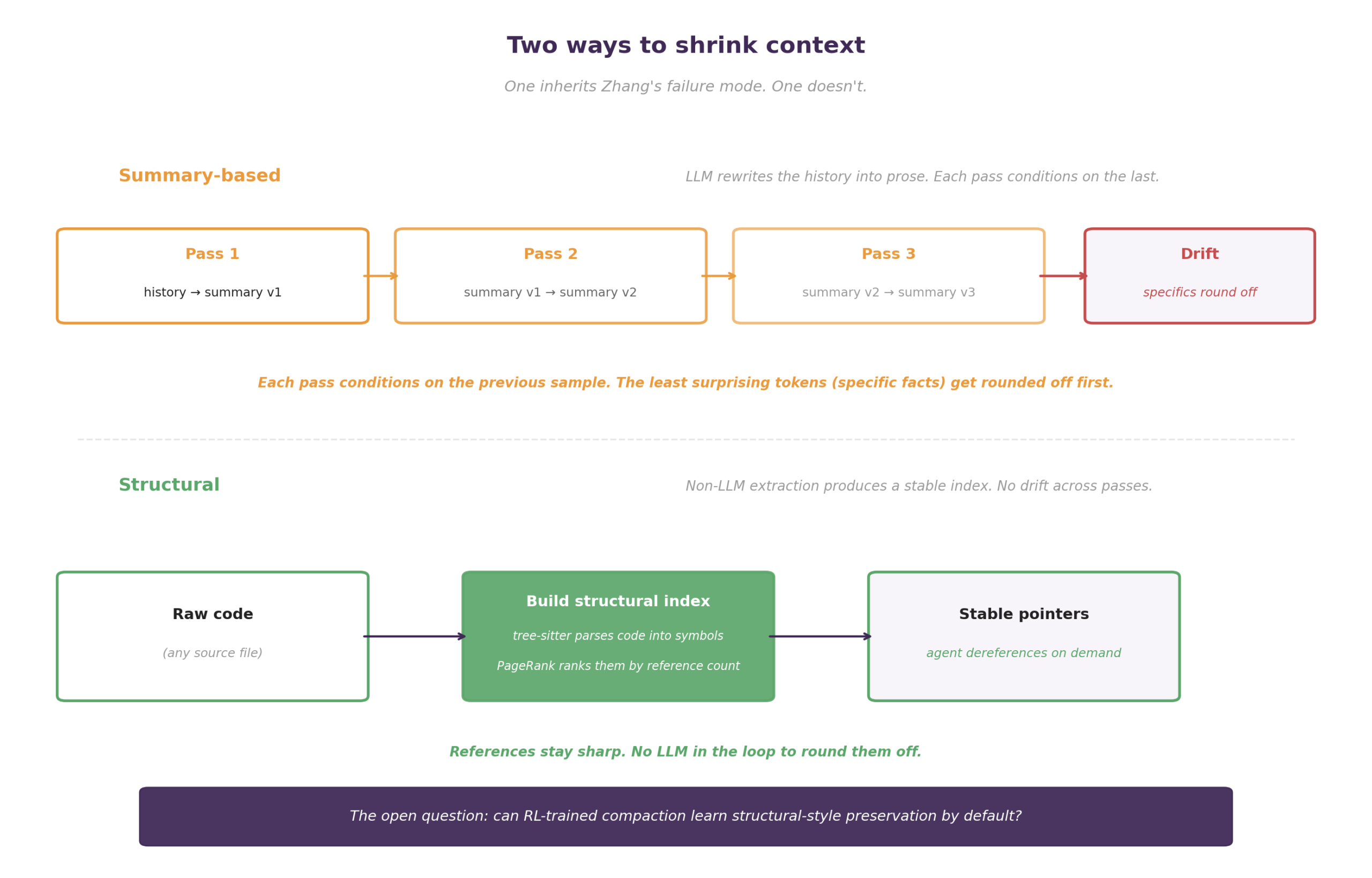
Anthropic shipped the strongest production artifact via its compact-2026-01-12 beta header, which triggers at 150K tokens by default and rewrites the conversation history into a compressed form the agent can continue from, with the mechanism fully disclosed in the API docs. LangChain and LlamaIndex both ship summarization middleware. Aider has used a repo-map from before this wave hit by constructing a structural index from tree-sitter and PageRank rather than an LLM summary. On the research side, AdaCoM (arXiv 2605.30785) and Context-Folding / FoldGRPO (arXiv 2510.11967) both argue that compaction policies can be RL-trained against a frozen agent and transferred across tasks.
The architectural fact that matters across this bucket is that there are two ways to shrink context. You can summarize, in which case an LLM rewrites the history into prose and the next pass conditions on that prose, or you can index, in which case tree-sitter, repo-map, or some other structural mechanism produces references the agent can dereference on demand. Summary-based compaction inherits the failure mode Dylan Zhang documented in Useful Memories Become Faulty When Continuously Updated by LLMs, where each summary is a sample from a distribution, the next pass conditions on that sample, and specific facts (the least surprising tokens) get progressively rounded off until the compressed history drifts away from what actually happened. Structural compaction does not have that problem because there is no LLM in the loop deciding what stays. The open research question this bucket genuinely opens is whether RL-trained compaction can learn to do structural-style preservation by default rather than summary-style rounding, and nobody has shown this convincingly yet.
Bucket 3: Cross-session consolidation
This is the bucket two labs shipped within 30 days of each other, and it is the bucket where the architectural choices diverge most visibly.
Anthropic launched Dreams for Managed Agents on May 6 as a developer-invoked async API that takes an existing memory store plus 1 to 100 raw session transcripts, runs them through a selectable Claude model, and produces a separate output store. The Anthropic documentation is unusually explicit on the architectural commitment: “a dream reads an existing memory store alongside past session transcripts, then produces a new, reorganized memory store… The input store is never modified.”
OpenAI launched Dreaming for ChatGPT on June 4, also using the biological-sleep metaphor, with a mechanism that secondary coverage characterizes as a background process operating over the user’s full chat history and writing consolidated profile artifacts in place. The internal benchmarks are unfalsifiable, scored by an unreleased LLM-judge eval set, and the launch page itself has been inaccessible for direct retrieval since release, leaving the specifics of the mechanism less verifiable than Anthropic’s.
The convergence on the metaphor is striking, and the architectural divergence is more so. Anthropic preserves the input store and produces a parallel artifact, while OpenAI rewrites in place. Zhang’s paper, in the same window, is precisely about the failure mode the in-place pattern is susceptible to: an iterated generative loop with no anchor, where each consolidation pass conditions on the previous one’s output and drifts toward the LLM’s prior rather than toward the truth of what happened. Anthropic’s design hedges against that. OpenAI’s does not.
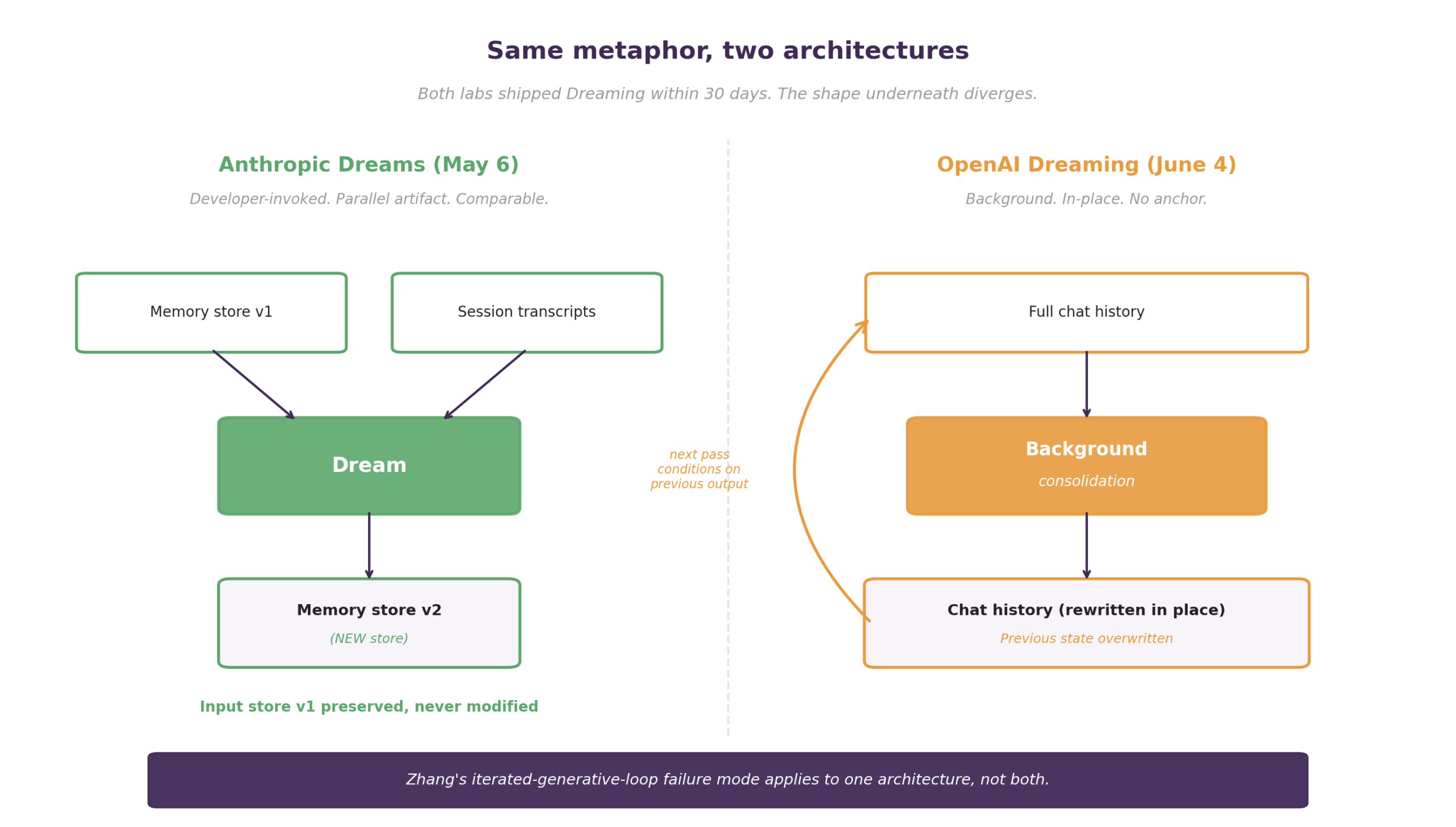
The observation worth holding here is that cross-session consolidation is not one architecture but at least two, and the academic empirical case suggests one of the two bets is structurally weaker. What this bucket actually solves is persistence of user-relevant facts across sessions, and whether the consolidation step adds value or destroys signal is the open question.
Bucket 4: Memory as a harness capability
The fourth bucket is the one the labs themselves default to in their flagship products. Claude Code, Pi, OpenClaw, and Google’s Sufficient Context Agent for Gemini share the same architectural pattern underneath: the agent uses grep, ls, glob, and read_file against a real filesystem or a virtual one backed by Postgres, S3, or another store, generates its own keyword queries, iterates as needed, and composes its answer from what it finds. In the architectural pattern itself, there is no embedding step and no pre-computed index — the model is the index.
This bucket received a wave of consumer-facing additions in the last six weeks. Cognition Devin Auto-Triage launched May 18 as a long-term-memory incident-response agent using the harness pattern. GitHub Copilot Memory turned on by default in March with a 28-day TTL, the TTL itself being an architectural choice about how long to retain. Microsoft Agent Framework 1.0 made FileMemoryProvider the default in April.
What unifies the bucket is the rejection of vector storage as the primary mechanism. The architectural bet is that LLM pretraining on Unix gives grep, ls, and glob a fluency advantage no embedding API can match, and that letting the model drive multi-step retrieval beats letting an index decide what is similar. The Letta filesystem benchmark from earlier this year (74.0% on LoCoMo) was the headline empirical exhibit for the pattern. Vercel’s Testing if bash is all you need experiment points at an honest limitation: when the data is structured and has a clean schema, SQL beats both bash and filesystem agents by a wide margin (100% versus 52.7% and 63.0% in their head-to-head comparison). The lesson is not that filesystems are universal but that filesystem-shaped APIs over whatever storage layer makes sense (Postgres, files, vectors, SQL) is the interface the labs have converged on, because that is the interface the models are fluent in.
The most explicit articulation of the pattern this week came from outside the major labs. Andrej Karpathy’s LLM Wiki gist describes a memory architecture as a collection of interlinked markdown files the agent maintains itself, with an index.md and log.md for navigation, an AGENTS.md file encoding the maintenance schema, and raw source documents kept immutable below the wiki layer. Angie Jones’s implementation writeup at the Agentic AI Foundation, published the same day as the Apple keynote, maps that wiki structure onto seven distinct memory categories (semantic, entity, episodic, summary, procedural, conversational, working) and lands on the framing the bucket has been gesturing at: vector retrieval and embeddings support the memory system rather than define it. The memory is the maintained body of knowledge itself, and the LLM is the bookkeeper.
This is also the bucket where our own production engineering on Alyx lives most directly. The LargeJson pattern stores data server-side and gives the agent a json_id handle alongside a structure-preserving preview, with jq and grep_json as query primitives. The PlanMessage stores the agent’s plan outside conversation history on disk and dynamically regenerates it on every LLM call so it cannot be buried or truncated by tool-call noise. Neither depends on an embedding store, and both are auditable per session via traces.
What this bucket actually solves is working memory for an agent inside a single session with retrieval grounded in real storage, plus a thin layer of file persistence for state across sessions. The architectural commitment is honest and the engineering pays off, but it is not the missing primitive.
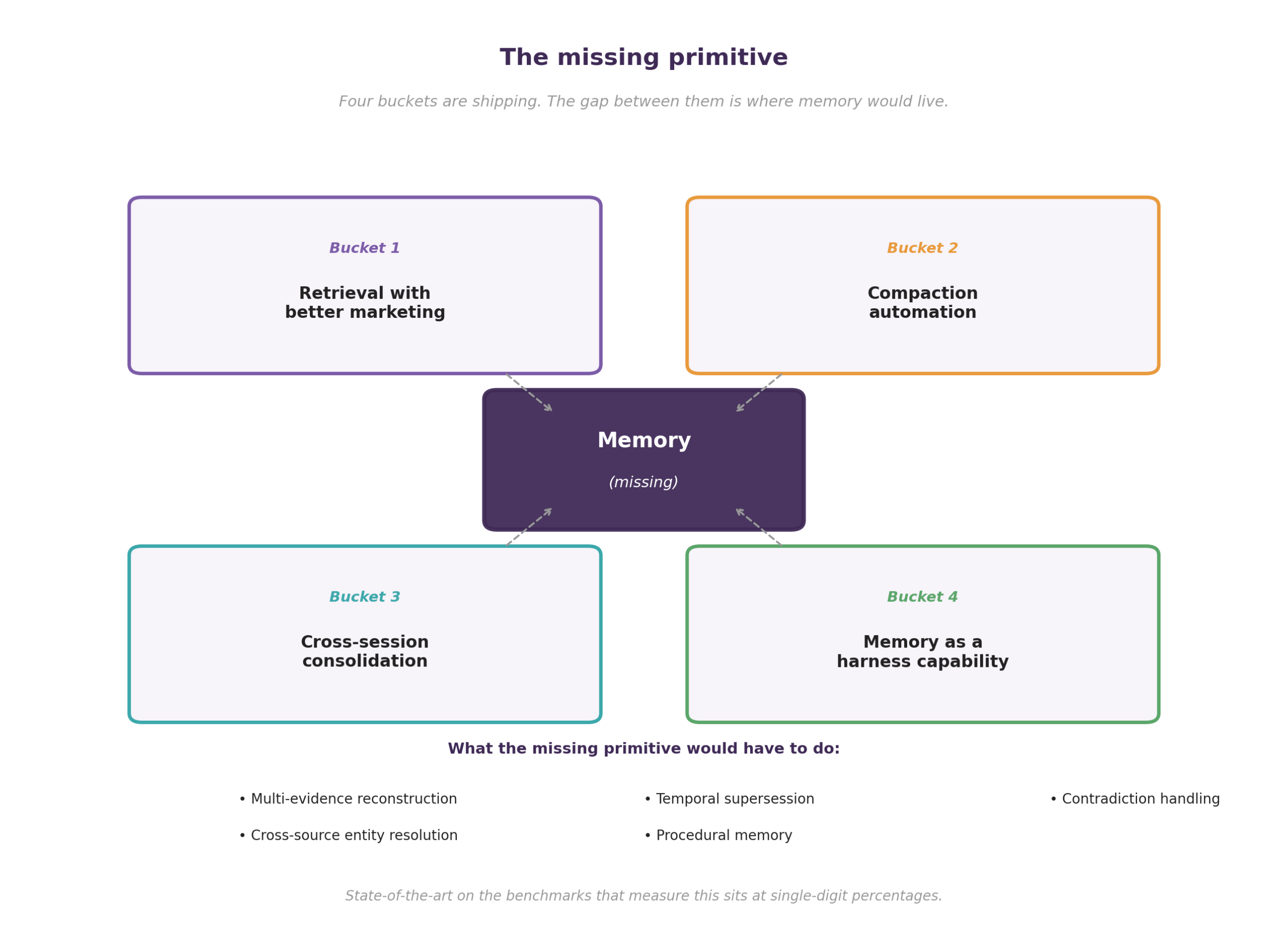
What none of the four buckets solves
The capability that would be memory in the sense a product manager or a cognitive scientist means it is mostly absent from all four buckets. The unsolved problems sit between them.
Multi-evidence reconstruction, which is the task of answering a question that requires assembling information from many sources where no single source is sufficient, is what retrieval and consolidation both gesture at but neither delivers cleanly. MemoryAgentBench, accepted at ICLR 2026, measures this directly, and the current state of the art scores roughly 6% on multi-hop conflict resolution. That tracks Zhang’s empirical case that abstraction-based memory degrades faster than no memory at all once the input distribution shifts.
Temporal supersession, which is the work of knowing that an old fact has been replaced by a new one, is mostly manual in shipping systems. Zep’s Graphiti does it with explicit bi-temporal edges, which works at small scale and breaks down on entity resolution. Reddy and Challaram (arXiv 2606.01435) showed that LLM judgment on temporal supersession scores 67.2%, while a deterministic-code rule scores 94.8%, which means the LLM is the wrong tool for the job and the right tool does not compose cleanly with the LLM-driven memory architectures that dominate the buckets above.
Contradiction handling, cross-source entity resolution, and procedural memory (remembering not facts but how a task was previously done and what worked) sit in the same gap. Recent Sakana ALE-Agent work gets closest with episodic working memory in an evolutionary search loop, but episodic-only sidesteps the failure mode of consolidation rather than solving persistence.
The taxonomy above describes what the field is shipping. The category between the buckets describes what would actually be memory.
What this means for builders
If you are shipping an agent with memory needs, three things from the catalogue are worth carrying with you. First, the bucket you are actually in is rarely the one your marketing copy implies, and the discipline of running end-to-end QA accuracy on the assembled system rather than R@K on the retriever is the cheapest way to find out; the MemPalace audit is now well-documented evidence that R@K on a QA benchmark is a leaderboard trick. Second, if you are choosing between buckets, the lab default is bucket 4: filesystem-shaped APIs over whatever storage actually scales, with embeddings as a relevance signal where they help rather than as the architecture, because the model is now smarter than the index. Third, if you are shipping consolidation, do what Anthropic did and preserve the input store; the empirical case against in-place LLM-driven consolidation is strong enough that you should not assume your consolidation step is helping until a pre-consolidation versus post-consolidation eval says so. Dream into a separate artifact, compare, keep the better one, and accept that the comparison requires trace-level instrumentation at the session boundary, because the bucket you are in is less important than whether you can tell when it stops working.
Closer
The Letta paper that landed in early May is the cleanest architectural statement of what the four buckets are not. The team red-teamed multiple frontier models against the “context constitution” — the prompts those models received describing themselves as stateful, persistent agents — and found something the prompts could not repair. The models, they wrote, exhibit “deep self-identification with ephemerality that cannot be repaired with prompting alone.” You cannot prompt a model into being stateful. You have to architect the state outside the model and feed it back in.
The four buckets are four architectural commitments about what to feed back in. All four are real engineering. None of them is the missing primitive.
The missing primitive — the thing that would close the gap between the buckets and what readers mean by memory — would have to compose evidence across many memories, resolve contradictions, handle supersession, and remember not just facts but procedures. No vendor in the catalogue above is selling it, and the empirical state-of-the-art on the benchmarks that measure it sits at single-digit percentages. This week Apple announced the biggest Siri update in fifteen years, and the demos were retrieval, the cloud was Google, and the architecture was admission. The Letta paper says prompting cannot fix the ephemerality, and Apple’s billion dollars a year says the same thing in different units.
Memory is still missing because nobody has yet figured out what it is.